RStudio を実行するために Amazon EMR のエッジノードを立ち上げる
RStudio を実行するために Amazon EMR のエッジノードを立ち上げる:
RStudio Server は R およびデータサイエンティストの間で人気のツールにブラウザベースのインターフェイスを提供します。データサイエンティストは分散型トレーニングを実行するために、Amazon EMR 上で実行する Apache Spark クラスターを使用します。前回のブログ記事では、著者が Amazon EMR クラスターに RStudio Server をインストールする方法を紹介しました。しかし、特定のシナリオでは、スタンドアロンの Amazon EC2 インスタンスにインストールし、リモートの Amazon EMR クラスターに接続するケースも考えられます。EC2 上で RStudio を実行することの利点としては次のようなものが考えられます。
この記事では、リモートワークロード用に構成された RStudio Server とともに Amazon EC2 を Amazon EMR のエッジノードとして構成するステップを 1 つずつ追って説明していきます。
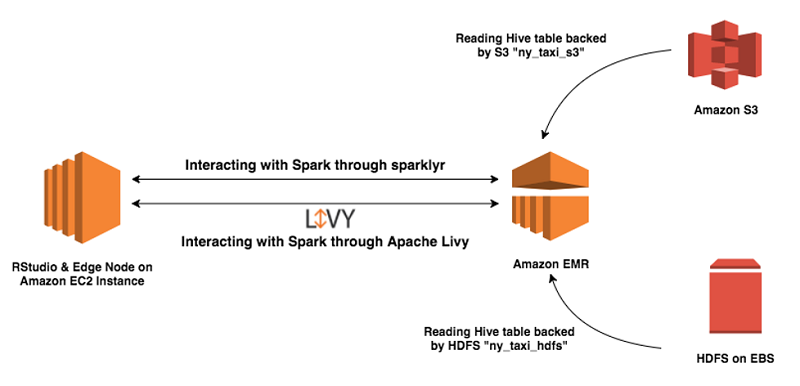
俯瞰的に見るとこのソリューションには以下のステップがあります。
エッジノードに Spark と Hadoop をインストールしたあと、リモートの Amazon EMR クラスターと通信できるようエッジノードを構成します。これを実行するために、EMR クラスターの複数の構成ファイルをエッジノードにコピーする必要があります。新しく作成された EMR クラスターから構成ファイルを EC2 インスタンス上のエッジノードにコピーする方法としては、手動と自動の 2 つあります。次の章ではこの 2 つのアプローチについて解説します。
また、ローカルマシンからエッジノードへこれらのファイルをコピーする際にも同じツールを使用できます。
PC ユーザーは EMR マスターノードと PC 間で接続したり、ファイルを転送したりする際に、WinSCP のようなアプリケーションを使用します。
注意: Amazon EMR 上にインストールされているアプリケーションによっては、クラスターから他のライブラリーのコピーが必要になる場合があります。一例として、このソリューションで使用された Hadoop と Spark パッケージのオープンソース型ディストリビューションでは、EMRFS のライブラリーがありません。つまり、EMRFS を使用するためには、EMRFS のライブラリーをエッジノードへコピーし、ライブラリーを含めるために classpath を更新します。
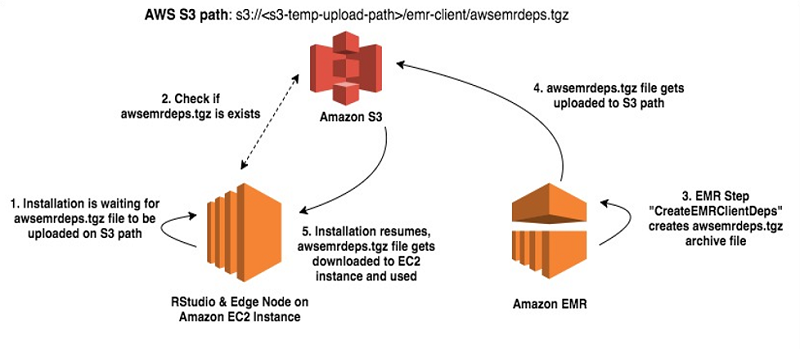
このソリューションでは、EMR ステップ (CreateEMRClientDeps) がスクリプト create-emr-client.sh を実行し、構成ファイルを Amazon S3 へコピーします。このスクリプトは、最初にすべての必要なライブラリーとともに、アーカイブファイル awsemrdeps.tgz を作成します。それから /emr-client/ で終わる接頭辞付きで、そのファイルを一時的な S3 バケットに、アップロードします。エッジノードでは、S3 からエッジノードへ awsemrdeps.tgz ファイルをコピーし直すとき、install-client-and-rstudio.sh スクリプトが使用されます。
Amazon EMR のエッジノードを作成し、エッジノードで RStudio を実行するために、AWS CloudFormation ステップを見ていきましょう。
この CloudFormation テンプレートでは、立ち上げ中、次のパラメータを渡す必要があります。
重要: このテンプレートは EMR エッジノードを作成して、リモートの EMR ワークロード用に RStudio を構成する方法を示すためにのみデザインされたものです。このセットアップは変更なく本番環境で使用するために作成されたものではありません。US-East-1 リージョン以外でこのソリューションを試す場合は、忘れずに s3://aws-data-analytics-blog/rstudio-edge-node から必要なファイルをダウンロードしてください。その後、AWS のリージョンのバケットにそのファイルをアップロードし、適切にスクリプトを編集してから、実行します。
CloudFormation スタックを開始するには、[Launch Stack] を選択します。

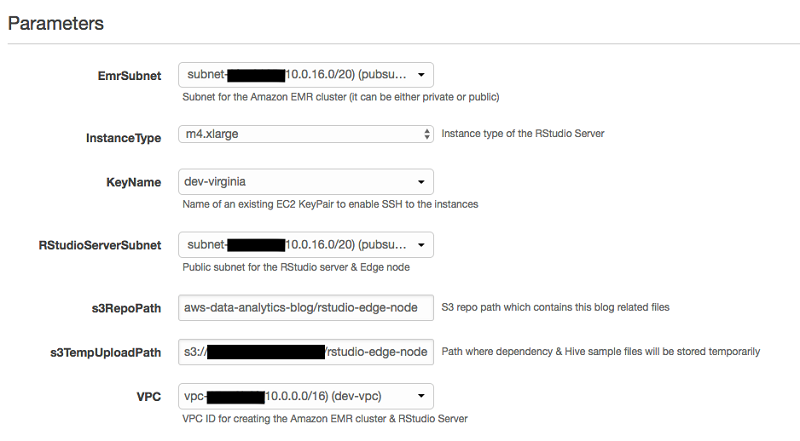
次のサンプルスクリーンショットではスタックパラメータを示しています。
このスタックを起動することで、次の AWS リソースが作成されます。
このソリューションで使用された CloudFormation テンプレートは、S3 パスを構成し、それぞれの場所にファイルを格納します。EMR クライアントの依存関係アーカイブ awsemrdeps.tgz は <<s3-temp-upload-path>>/emr-client/ ロケーションに格納されます。サンプルデータファイル tripdata.csv は <<s3-temp-upload-path>>/ny-taxi/ に格納されています。
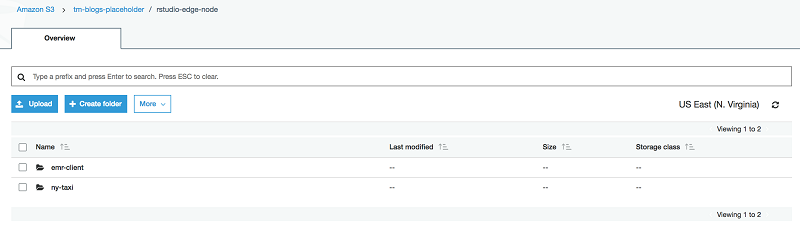
次のスクリーンショットでは、S3 パスがデプロイメント後にどのように構成されるかを示しています。この例では、S3 のフルパスである s3://<<my-bucket>>/rstudio-edge-node を渡します。これは Amazon S3 アカウント上にあります。
CloudFormation テンプレートが正常に実行完了したら、RStudio Server の DNS アドレスが、以下の通り Outputs タブに表示されます。
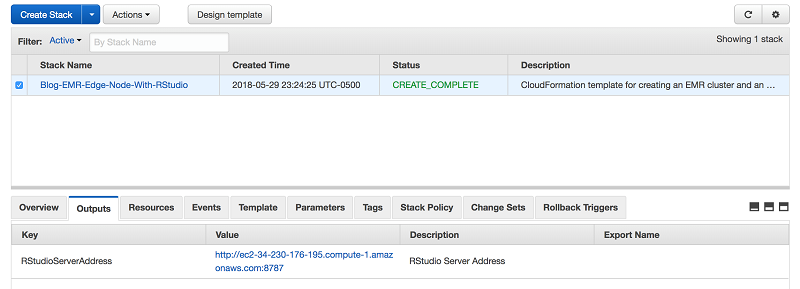
表示されているアドレスは、RStudio Server とエッジノードの DNS アドレスです。ユーザーはFoxyProxy を有効化した直後、このアドレスに接続できるようになるはずです。
2 つ目の EMR ステップである CreateHiveTables は CloudFormation テンプレートの一部として作成されています。このステップでは 2 つの Hive テーブルが作成され、これらは後の工程で、サンプルモデルを実行するために、RStudio の R で使用されます。いずれも外部 Hive テーブルです。1 つは EMR クラスターの HDFS に格納され、もう 1 つは Amazon S3 に格納されます。ここでの目標は RStudio が、HDFS と S3 の支援を受けたストレージでデータをどのように消費するかを実証することです。
以下のセクションには、Amazon EMR のクライアント機能をテストするステップのリストを示しましたがテストはオプションです。

ログインが成功すると、このウェルカムウィンドウに移動します。左側の大きなウィンドウは、コンソールウィンドウで、R の書き込みを行うところです。
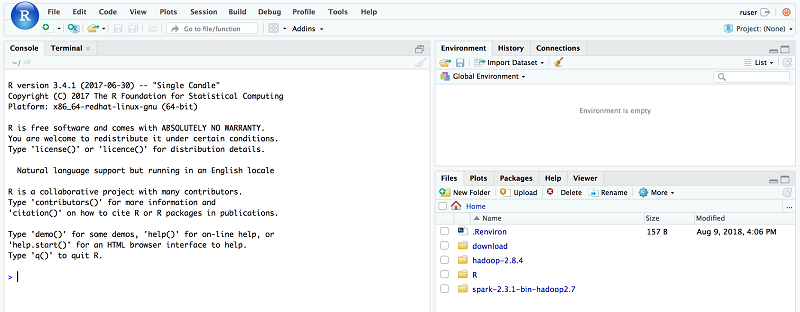
R コンソールに SparkContext を作成します。RStudio が既に必要な環境変数と、AWS CloudFormation スタックを介してファイルのセットアップが済んでいるため、追加の構成は不要です。このソリューションでは、Spark に接続するために、Sparklyr が使用されます。次のように、SparkContext を作成する前に、必要な R パッケージを添付します。
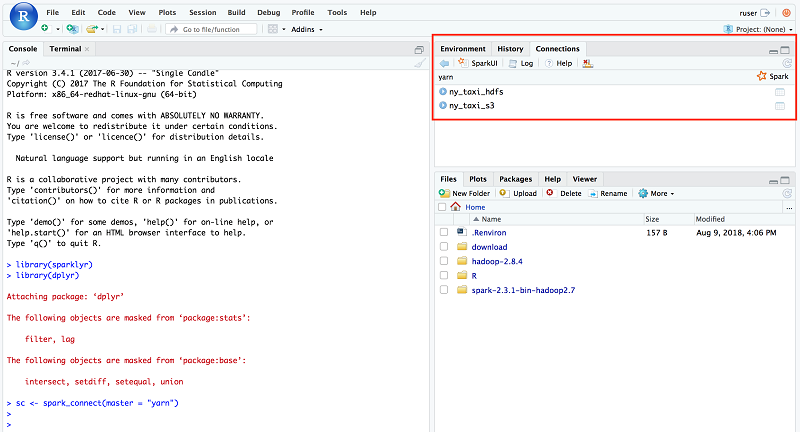
Spark への接続が確立されると、「yarn」接続チャネルが作成されます (右隅の Connections タブ上で RStudio UI でこれを見つけます)。同一ウィジェットの Hive メタデータも表示されます。CloudFormation テンプレートが Hive テーブルを 2 つ作成したため、次に示すように、これらのテーブルは「yarn」の下に表示されます。
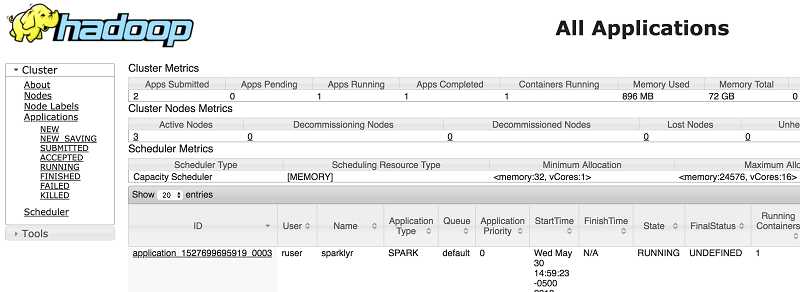
YARN アプリケーションもまた ruser の下に配置されています。アプリケーションのステータスは、接続が確立されている間は RUNNING になります。YARN リソースマネージャー UI でもアプリケーションのステータスを見つけることができます。ユーザーは ruser で、アプリケーション名が sparklyr であることに注意してください。
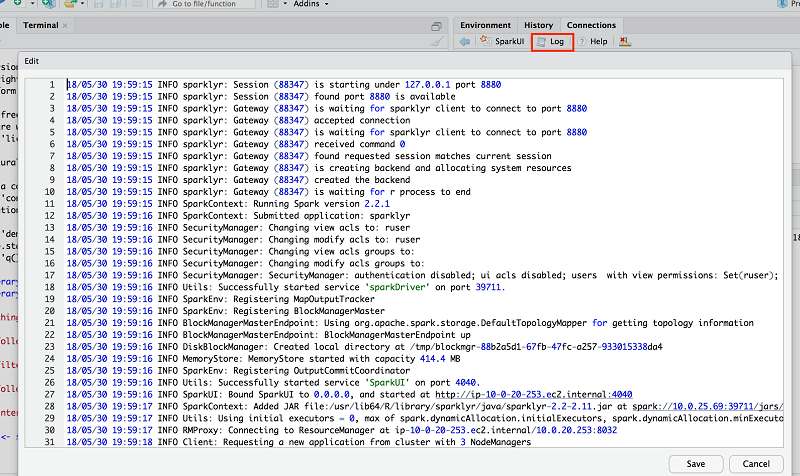
詳細についてはウィジェットで Log を選択して、YARN のアプリログを確認してください。
続いて、これらの 2 つの Hive テーブルのデータにアクセスできるかどうかをテストします。データのサンプルを取り出すために ny_taxi_hdfs テーブルを選択します。
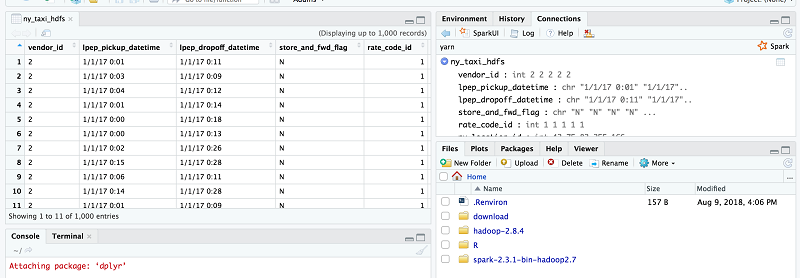
S3 のデータのサンプルを取り出すために ny_taxi_s3 テーブルを選択します。
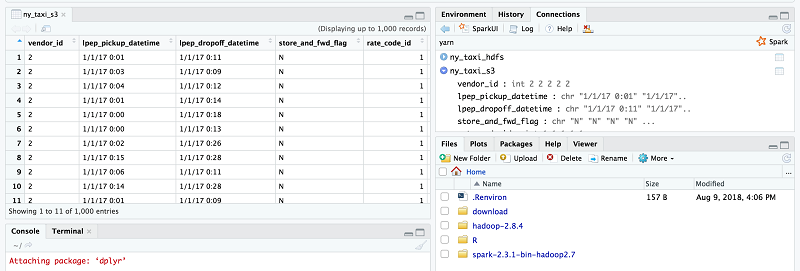
これらの 2 つのテストが正常に実行できたら、エッジノードで実行中の RStudio がリモート EMR クラスターに格納されたデータを消費できることが分かります。
開発フェーズ中、一部のデータを S3 バケットへ再度書き込めるようにしたいと考えるかも知れません。そのため、ユーザーが R と Spark を使用して、S3 に直接データを書き込めるかどうかを確認するのは良い案です。これをテストするために、spark_read_table API を使用して ny_taxi_hdfs Hive テーブルを読み込みます。次に、spark_write_csv API を呼び出し、S3 のターゲットパスを渡して Amazon S3 にデータを書き込みます。この章では、新しい S3 パスとして、s3://tm-blogs-placeholder/write-from-rstudio を使用しました。
書き込み処理後、S3 のロケーションは次のように表示されます。
また、YARN のアプリケーションログでも Spark の書き込みログを確認できます。
次は R でデータを分析し、グラフを描いてみましょう。これを実行するためにはまず、ny_taxi data の数を確認してください。20,000 という数値が返るはずです。
続いて、各レートのコードタイプの走行回数を見つけます。6 種類の異なるレートのコードタイプがあり、1 は標準のレートコードで、5 は交渉後のレートを意味します。詳細については、タクシーデータの詳細辞書をご覧ください。
このグラフをもとに、 (一部の交渉後の料金を支払った一部の乗客を除き) 残りの乗客は、利用後に標準のレートを支払ったと言えます。
次に、ニューヨークエリアとクイーンズおよびマンハッタン間での平均的な走行時間を割り出します。pu_location_id 値はタクシーに乗車したゾーン、do_location_id はタクシーを降車したゾーンをそれぞれ示します。このテストでは乗車ゾーンとして 129 を、降車ゾーンとして 82 を使用します。タクシーゾーン 129 とはクイーンズ区のジャクソンハイツ地区、タクシーゾン 82 はエルムハースト地区に該当します。詳細については、こちらのタクシーゾーン検索テーブルを参照してください。
この図から、乗車平均時間は 10 分~ 12 分であったと言えます。一部、午前 1 時頃に乗車時間が 30 分を越える希なピーク時間が見られました。
問題 1: RStudio Server の URL をクリックすると「There is no Internet connection」(インターネット接続がありません) というエラーが返る。
ソリューション: ブラウザ内で FoxyProxy を構成したこと、RStudio EC2 インスタンスのパブリック IP アドレスに接続していることを確認してください。このアドレスは AWS CloudFormation コンソールの Outputs タブから確認できます。
問題 2: EMR のステップジョブ CreateClientDeps が失敗する。
ソリューション: この EMR ステップジョブは、create-emr-client.sh スクリプトを実行します。このスクリプトはすべての必須依存関係を持ったアーカイブを作成し、それを S3 ロケーションにアップロードします。エッジノードが S3 への書き込みアクセス許可がない場合は、このステップジョブが失敗します。このソリューションでは、また、デフォルトの EMR ロール EMR_EC2_DefaultRole がエッジノードインスタンスに割り当てられています。EMR_EC2_DefaultRole には、CloudFormation パラメータ S3TempUploadPath によって付与された S3 ロケーションへの書き込みアクセスがあるものと想定しています。
問題 3: AWS CloudFormation テンプレート Blog-EMR-Edge-Node-With-RStudio がタイムアウトを起こす、または失敗する。
ソリューション: install-client-and-rstudio.sh という名前のスクリプトが、エッジノードの cfn-init を介して実行されます。また、これは、/tmp/edge-node-rstudio-installation.log ファイルにログを書き込みます。このスクリプトにはスリープ節が含まれ、S3 で awsemrdeps.tgz が利用できるようになるまで待機します。この節は20分後にタイムアウトします。スクリプトが指定された時間内にこのファイルを見つけ出せないと、その後の実行は失敗します。また、このソリューションでは、RStudio はパッケージのインストール中に、 http://cran.rstudio.com/ を repo として使用します。Amazon EC2 インスタンスがインターネットに接続できない場合は、インスタンスはそのパッケージをダウンロードしてインストールできないため、テンプレートが失敗する場合があります。エッジノードの NAT を備えたパブリックサブネットかプライベートサブネットを選ぶようにしてください。
問題 4: Amazon EMR クライアントのテスト中に、Spark のサンプルアプリケーションが、NoClassdefFounderror または UnsupportedOperationException エラーで失敗する。
ソリューション: このブログ記事では、Amazon EMR 5.16.0 を使用しています。EMR リリースに対応した Hadoop および Spark のバージョンを使用するようにしてください。マスタ―ノードのアプリケーションバージョンが、エッジノードのアプリケーションバージョンと異なる場合は、クライアントが NoClassdefFounderror または UnsupportedOperationException エラーで失敗する可能性があります。両方のロケーションで常に Hadoop と Spark の同一バージョンをインストールするようにしてください。
 Tanzir Musabbir は AWS の EMR スペシャリストソリューションアーキテクトです。彼はオープンソース型ビッグデータテクノロジーをいち早く採り入れた人物です。AWS において、彼はお客様と協力しながら、Amazon EMR、Amazon Athena 、AWS Glue の分析ソリューションを実行するための構造的なガイダンスを提供しています。Tanzir はリアルマドリードの大ファンで、余暇には旅に出るのが好きです。
Tanzir Musabbir は AWS の EMR スペシャリストソリューションアーキテクトです。彼はオープンソース型ビッグデータテクノロジーをいち早く採り入れた人物です。AWS において、彼はお客様と協力しながら、Amazon EMR、Amazon Athena 、AWS Glue の分析ソリューションを実行するための構造的なガイダンスを提供しています。Tanzir はリアルマドリードの大ファンで、余暇には旅に出るのが好きです。
RStudio Server は R およびデータサイエンティストの間で人気のツールにブラウザベースのインターフェイスを提供します。データサイエンティストは分散型トレーニングを実行するために、Amazon EMR 上で実行する Apache Spark クラスターを使用します。前回のブログ記事では、著者が Amazon EMR クラスターに RStudio Server をインストールする方法を紹介しました。しかし、特定のシナリオでは、スタンドアロンの Amazon EC2 インスタンスにインストールし、リモートの Amazon EMR クラスターに接続するケースも考えられます。EC2 上で RStudio を実行することの利点としては次のようなものが考えられます。
- EC2 インスタンス上で RStudio Server を実行することにより、インスタンス上に科学的モデルとモデルアーティファクトをそのまま保存できます。アプリケーションの要件を満たすために、EMR クラスターの再起動が必要になることがあります。RStudio Server を別途実行することで、柔軟性が向上し、Amazon EMR クラスターにすべて依存する必要がなくなります。
- Amazon EMR のマスターノード上に RStudio をインストールするには、同一ノード上で稼動しているアプリケーションとリソースを共有する必要があります。スタンドアロンの Amazon EC2 インスタンス上で RStudio を実行することで、他のアプリケーションとリソースを共有する必要なく、リソースを使用できるようになります。
- ご使用の環境に複数の Amazon EMR クラスターをお持ちの方もおいでかと思います。エッジノードに RStudio を配置すると、ご使用の環境で任意の EMR クラスターに接続できるという柔軟性が得られます。
この記事では、リモートワークロード用に構成された RStudio Server とともに Amazon EC2 を Amazon EMR のエッジノードとして構成するステップを 1 つずつ追って説明していきます。
ソリューションの概要
次のいくつかのセクションでは、エッジノードの作成、RStudio のインストール、エッジノード上で実行している R からリモートの Spark クラスターへ接続する方法について解説します。俯瞰的に見るとこのソリューションには以下のステップがあります。
- Amazon EC2 インスタンスを作成する。
- そのインスタンスに、RStudio Server と、必要な依存関係をインストールする。
- Apache Spark と Hadoop のクライアントライブラリー、依存関係を同じインスタンス上にインストールする。
- Apache Spark、Livy、Hive の各アプリケーションとともに、Amazon EMR クラスターを起動する。
- Amazon EC2 インスタンスを EMR クライアントとして構成する。
- サンプルのリモートジョブを実行して、EMR クライアントの機能をテストする。
- Sparklyr を使用して、R から Spark クラスターに接続する。
- RStudio から EMR 上の Hive テーブルとやり取りする。
- EMR クラスター上のデータに R モデルを実行する。
Amazon EMR 用のエッジノードの作成
この演習では、エッジノードに Spark クライアントを作成します。Spark は Hadoop ライブラリーに依存するため、エッジノードに Hadoop もインストールします。クライアントが正常に機能するように、Hadoop と Spark の同一バージョンを EMR クラスター上にも同様にインストールします。このライブラリーのほとんどが JVM 上で実行されるため、EMR クラスター上の JVM と同じ JVM をインストールするようお勧めします。エッジノードに Spark と Hadoop をインストールしたあと、リモートの Amazon EMR クラスターと通信できるようエッジノードを構成します。これを実行するために、EMR クラスターの複数の構成ファイルをエッジノードにコピーする必要があります。新しく作成された EMR クラスターから構成ファイルを EC2 インスタンス上のエッジノードにコピーする方法としては、手動と自動の 2 つあります。次の章ではこの 2 つのアプローチについて解説します。
手動アプローチ
EMR クラスターが稼動したら、EMR マスターノードからローカルのマシンに必要な構成ファイルをコピーするために、安全な転送ツール scp を使用できます。私は、自分の ノート PC を使いました。> mkdir emr-config
> cd emr-config
> scp -i <key> hadoop@<master-node-dns>:/etc/hadoop/conf/*-site.xml .> scp -i <key> hdfs-site.xml ec2-user@<edge-node-dns>:/etc/hadoop/conf/.注意: Amazon EMR 上にインストールされているアプリケーションによっては、クラスターから他のライブラリーのコピーが必要になる場合があります。一例として、このソリューションで使用された Hadoop と Spark パッケージのオープンソース型ディストリビューションでは、EMRFS のライブラリーがありません。つまり、EMRFS を使用するためには、EMRFS のライブラリーをエッジノードへコピーし、ライブラリーを含めるために classpath を更新します。
自動アプローチ (このソリューションで使用)
前述のアプローチでお気づきかも知れませんが、コピー操作は次の 2 回必要になります。- EMR マスターノードからローカルマシン
- ローカルマシンからエッジノードへ
このソリューションでは、EMR ステップ (CreateEMRClientDeps) がスクリプト create-emr-client.sh を実行し、構成ファイルを Amazon S3 へコピーします。このスクリプトは、最初にすべての必要なライブラリーとともに、アーカイブファイル awsemrdeps.tgz を作成します。それから /emr-client/ で終わる接頭辞付きで、そのファイルを一時的な S3 バケットに、アップロードします。エッジノードでは、S3 からエッジノードへ awsemrdeps.tgz ファイルをコピーし直すとき、install-client-and-rstudio.sh スクリプトが使用されます。
Amazon EMR のエッジノードを作成し、エッジノードで RStudio を実行するために、AWS CloudFormation ステップを見ていきましょう。
AWS CloudFormation を使用したウォークスルー
以下は、このソリューション用に AWS CloudFormation テンプレートを実行するための前提条件です。- 少なくとも 1 つ以上のパブリックサブネットと 1 つ以上のプライベートサブネット を指定して Amazon VPC を作成します。
- IAM ポリシーを更新し、ユーザーが IAM ポリシー、インスタンスプロファイル、ロール、セキュリティグループにアクセスできるようにします。
- Amazon S3 用の VPC エンドポイントを有効化します。
- EC2 インスタンスに接続するため EC2 キーペアを作成します。
この CloudFormation テンプレートでは、立ち上げ中、次のパラメータを渡す必要があります。
| パラメータ | 説明 |
| EmrSubnet | Amazon EMR クラスターがデプロイされるサブネット。パブリックまたはプライベートのいずれかのサブネットに指定できます。 |
| InstanceType | RStudio Server とエッジノードに使用された Amazon EC2 インスタンスタイプで、m4.xlarge がデフォルトになります。 |
| KeyName | Amazon EMR およびエッジノードにアクセスするための既存の EC2 キーペアの名前。 |
| RStudioServerSubnet | RStudio Server とエッジノードが立ち上げられるパブリックサブネット。 |
| S3RepoPath | すべての必須ファイル (テンプレート、スクリプトジョブ、サンプルデータなど) が格納される Amazon S3 パス。 |
| S3TempUploadPath | 一時的な依存関係ファイルや Hive のサンプルデータを格納するための AWS アカウントの S3 パス。 |
| VPC | EMR とエッジノードがデプロイされる Virtual Private Cloud (VPC) の ID。 |
CloudFormation スタックを開始するには、[Launch Stack] を選択します。
次のサンプルスクリーンショットではスタックパラメータを示しています。
このスタックを起動することで、次の AWS リソースが作成されます。
| 論理 ID | リソースタイプ | 説明 |
| EMRCluster | Amazon EMR クラスター | Spark と Hive のジョブを実行する EMR クラスター |
| CreateEMRClientDeps | EMR ステップジョブ | クライアントの依存関係を作成し、S3 にアップロードするスクリプトを実行するジョブ |
| CreateHiveTables | EMR ステップジョブ | Hive のサンプルデータをコピーし、Hive のテーブルを作成するジョブ |
| RStudioConfigureWaitCondition | CloudFormation wait condition | 待機ハンドラーとともに機能する待機条件で、RStudio Server のセットアッププロセスが完了するのを待機する |
| RStudioEIP | 伸縮自在な IP アドレス | RStudio Server 向けの伸縮自在な IP アドレス |
| RStudioInstanceProfile | インスタンスプロファイル | RStudio のインスタンスプロファイルとエッジノードインスタンス (このソリューションでは、EMR の立ち上げ中作成された、デフォルトロールの EMR_EC2_DefaultRole を使用しました) |
| RStudioSecGroup | Amazon EC2 セキュリティグループ | エッジノードへの着信トラフィックを制御するセキュリティグループ |
| RStudioServerEC2 | Amazon EC2 インスタンス | エッジノードと RStudio Server の EC2 インスタンス |
| RStudioToEMRSecGroup | Amazon EC2 セキュリティグループ | EMR とエッジノード間のトラフィックを制御するセキュリティグループ |
| RStudioWaitHandle | CloudFormation の待機ハンドラー | RStudio Server が起動されたあとにトリガーされる待機ハンドラー |
| SecGroupSelfIngress | Amazon EC2 セキュリティグループの侵入ルール | インスタンスが同じセキュリティグループのインスタンスと通信できるようにする RStudioToEMRSecGroup への侵入ルール |
次のスクリーンショットでは、S3 パスがデプロイメント後にどのように構成されるかを示しています。この例では、S3 のフルパスである s3://<<my-bucket>>/rstudio-edge-node を渡します。これは Amazon S3 アカウント上にあります。
CloudFormation テンプレートが正常に実行完了したら、RStudio Server の DNS アドレスが、以下の通り Outputs タブに表示されます。
表示されているアドレスは、RStudio Server とエッジノードの DNS アドレスです。ユーザーはFoxyProxy を有効化した直後、このアドレスに接続できるようになるはずです。
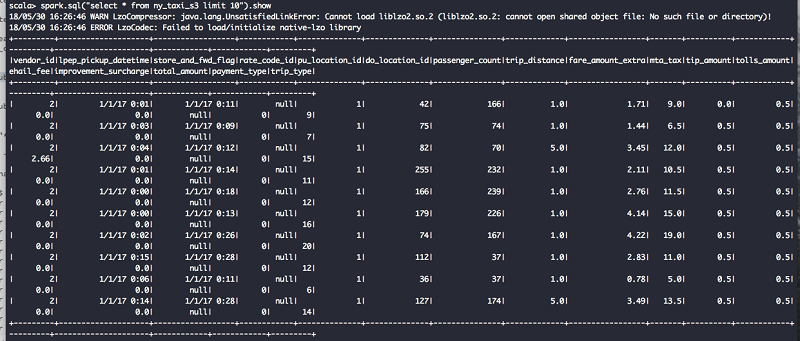
データとテーブルをテストする
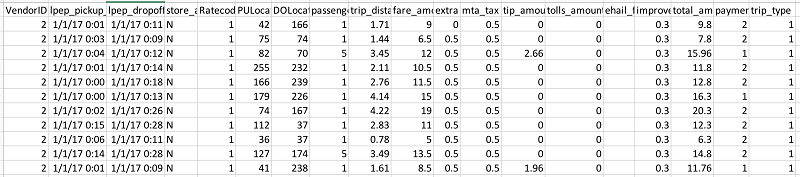
ソースデータについては、ニューヨーク市のタクシーとリムジンコミッション (TLC) の走行記録データを使用しました。データの説明については、このタクシーデータの詳細辞書を参照してください。走行データはコンマ区切り値 (CSV) 形式で、1 行目はヘッダーです。以下の画像は走行データセットのデータを示します。2 つ目の EMR ステップである CreateHiveTables は CloudFormation テンプレートの一部として作成されています。このステップでは 2 つの Hive テーブルが作成され、これらは後の工程で、サンプルモデルを実行するために、RStudio の R で使用されます。いずれも外部 Hive テーブルです。1 つは EMR クラスターの HDFS に格納され、もう 1 つは Amazon S3 に格納されます。ここでの目標は RStudio が、HDFS と S3 の支援を受けたストレージでデータをどのように消費するかを実証することです。
| テーブル名 | ストレージタイプ | パス |
| ny_taxi_hdfs | HDFS | /user/ruser/ny_taxi |
| ny_taxi_s3 | S3 | s3://<s3-temp-upload-path>/ny_taxi |
EMR クラインと機能のテスト (オプション)
EMR クライアントがエッジノード上で正しく構成されている場合は、エッジノードから EMR クラスターへ Spark ジョブを発行できるはずです。この機能を試すには、エッジノードに次のいくつかのステップを適用しましょう。- デフォルトのユーザー ec2-user を使用してエッジノードにログインする。
- CloudFormation Outputs タブからこのホストのアドレスを選択する。
ssh -i <<key-pair>> ec2-user@<<rstudio-server-address>>- CloudFormation テンプレートもまた、新しいユーザー、呼び出した ruser を作成する。ユーザーは Spark ジョブを使用したり、RStudio UI を使用したりすることができる。ec2-user から ruser へユーザーを切り替える。
[ec2-user@ip-10-0-30-164 ~]$ sudo -s
[root@ip-10-0-30-164 ec2-user]# su – ruser- リモートの EMR クラスターに Spark のサンプルジョブを発行する。
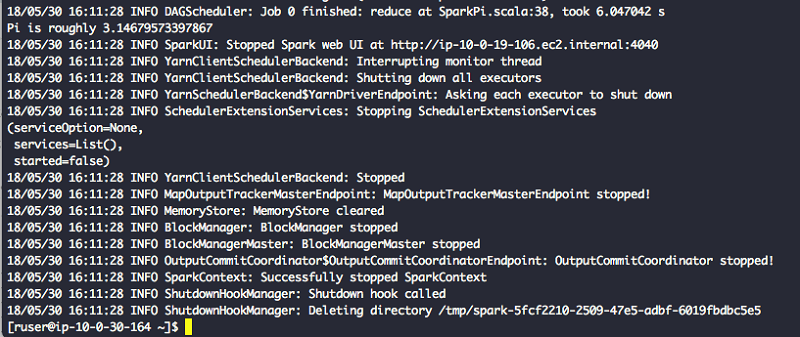
$SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn $SPARK_HOME/examples/jars/spark-examples_2.11-2.3.1.jar- 端末と EMR コンソールでジョブのステータスを確認する。Spark のサンプルジョブが正常に終了するはずです。端末には、次に示すように Pi の値が表示されるはずです。
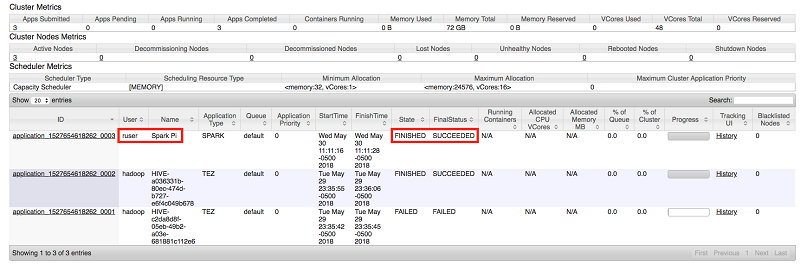
- リソースマネージャーの UI でジョブステータスを確認します。Spark PI ジョブが ruser として実行され、正常に完了していることが分かります。
- spark シェル、リモートの EMR クラスターから Hive テーブルのデータを実行し、このセットアップをさらにテストします。
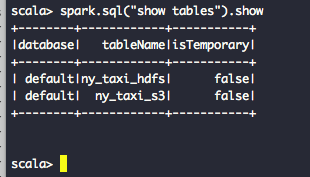
[ruser@ip-10-0-30-164 ~]$ $SPARK_HOME/bin/spark-shell- すべての使用できる Hive テーブルのリストとそのコンテンツを確認します。
scala> spark.sql("show tables").showscala> spark.sql("select * from ny_taxi_s3 limit 10").showR を実行し、Apache Spark に接続する
この章ではいくつかのテストと Amazon EMR からの RStudio 消費データからのモデルを実行していきます。CloudFormation コンソールの Outputs タブで RStudio Server のアドレスを見つけます。ユーザー名は ruser でパスワードは BigData26 です。ログインが成功すると、このウェルカムウィンドウに移動します。左側の大きなウィンドウは、コンソールウィンドウで、R の書き込みを行うところです。
R コンソールに SparkContext を作成します。RStudio が既に必要な環境変数と、AWS CloudFormation スタックを介してファイルのセットアップが済んでいるため、追加の構成は不要です。このソリューションでは、Spark に接続するために、Sparklyr が使用されます。次のように、SparkContext を作成する前に、必要な R パッケージを添付します。
library(sparklyr)
library(dplyr)
sc <- spark_connect(master = "yarn")YARN アプリケーションもまた ruser の下に配置されています。アプリケーションのステータスは、接続が確立されている間は RUNNING になります。YARN リソースマネージャー UI でもアプリケーションのステータスを見つけることができます。ユーザーは ruser で、アプリケーション名が sparklyr であることに注意してください。
詳細についてはウィジェットで Log を選択して、YARN のアプリログを確認してください。
続いて、これらの 2 つの Hive テーブルのデータにアクセスできるかどうかをテストします。データのサンプルを取り出すために ny_taxi_hdfs テーブルを選択します。
S3 のデータのサンプルを取り出すために ny_taxi_s3 テーブルを選択します。
これらの 2 つのテストが正常に実行できたら、エッジノードで実行中の RStudio がリモート EMR クラスターに格納されたデータを消費できることが分かります。
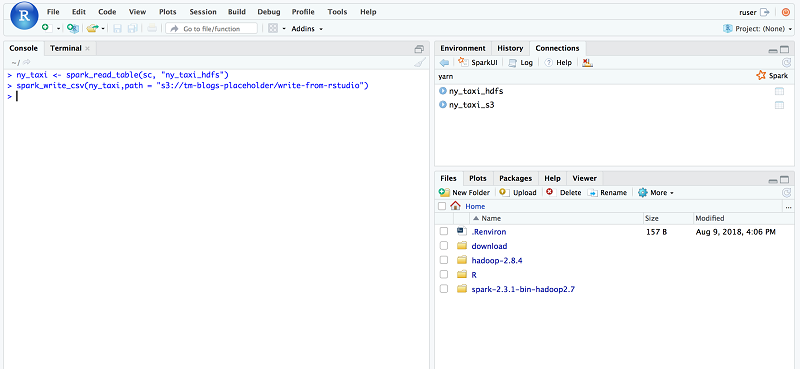
開発フェーズ中、一部のデータを S3 バケットへ再度書き込めるようにしたいと考えるかも知れません。そのため、ユーザーが R と Spark を使用して、S3 に直接データを書き込めるかどうかを確認するのは良い案です。これをテストするために、spark_read_table API を使用して ny_taxi_hdfs Hive テーブルを読み込みます。次に、spark_write_csv API を呼び出し、S3 のターゲットパスを渡して Amazon S3 にデータを書き込みます。この章では、新しい S3 パスとして、s3://tm-blogs-placeholder/write-from-rstudio を使用しました。
ny_taxi <- spark_read_table(sc, "ny_taxi_hdfs")
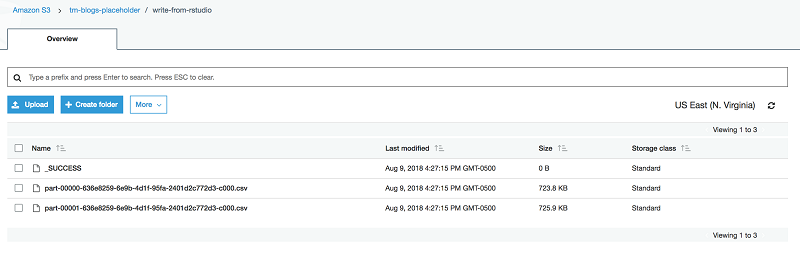
spark_write_csv(ny_taxi,path = "s3://tm-blogs-placeholder/write-from-rstudio")書き込み処理後、S3 のロケーションは次のように表示されます。
また、YARN のアプリケーションログでも Spark の書き込みログを確認できます。
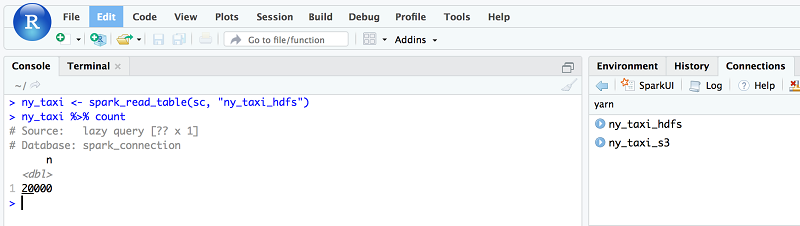
次は R でデータを分析し、グラフを描いてみましょう。これを実行するためにはまず、ny_taxi data の数を確認してください。20,000 という数値が返るはずです。
ny_taxi <- spark_read_table(sc, "ny_taxi_hdfs")
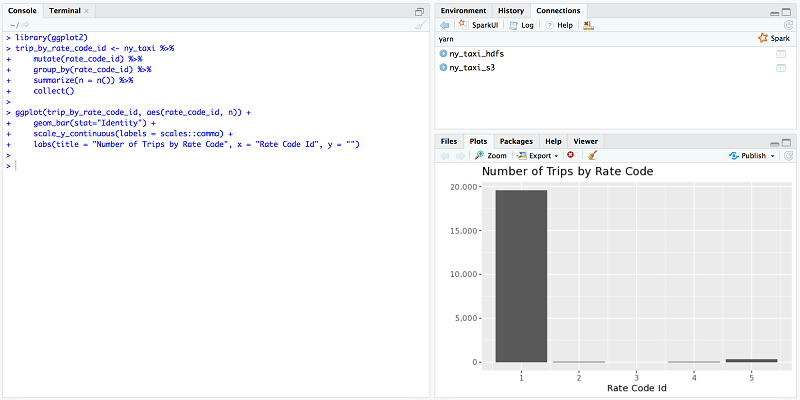
ny_taxi %>% count続いて、各レートのコードタイプの走行回数を見つけます。6 種類の異なるレートのコードタイプがあり、1 は標準のレートコードで、5 は交渉後のレートを意味します。詳細については、タクシーデータの詳細辞書をご覧ください。
library(ggplot2)
trip_by_rate_code_id <- ny_taxi %>%
mutate(rate_code_id) %>%
group_by(rate_code_id) %>%
summarize(n = n()) %>%
collect()
ggplot(trip_by_rate_code_id, aes(rate_code_id, n)) +
geom_bar(stat="Identity") +
scale_y_continuous(labels = scales::comma) +
labs(title = "Number of Trips by Rate Code", x = "Rate Code Id", y = "")このグラフをもとに、 (一部の交渉後の料金を支払った一部の乗客を除き) 残りの乗客は、利用後に標準のレートを支払ったと言えます。
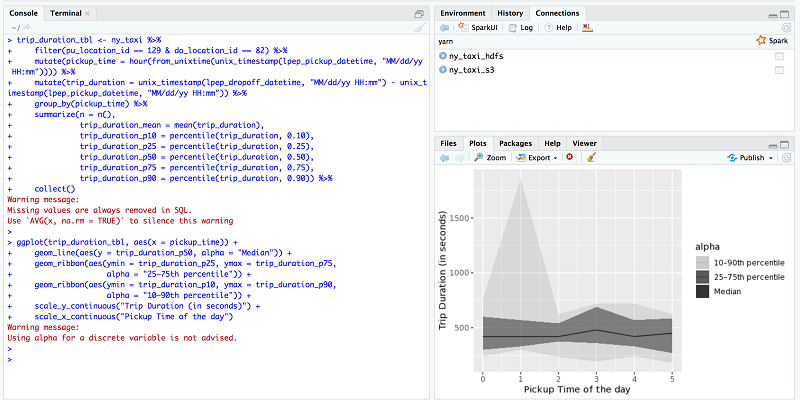
次に、ニューヨークエリアとクイーンズおよびマンハッタン間での平均的な走行時間を割り出します。pu_location_id 値はタクシーに乗車したゾーン、do_location_id はタクシーを降車したゾーンをそれぞれ示します。このテストでは乗車ゾーンとして 129 を、降車ゾーンとして 82 を使用します。タクシーゾーン 129 とはクイーンズ区のジャクソンハイツ地区、タクシーゾン 82 はエルムハースト地区に該当します。詳細については、こちらのタクシーゾーン検索テーブルを参照してください。
trip_duration_tbl <- ny_taxi %>%
filter(pu_location_id == 129 & do_location_id == 82) %>%
mutate(pickup_time = hour(from_unixtime(unix_timestamp(lpep_pickup_datetime, "MM/dd/yy HH:mm")))) %>%
mutate(trip_duration = unix_timestamp(lpep_dropoff_datetime, "MM/dd/yy HH:mm") - unix_timestamp(lpep_pickup_datetime, "MM/dd/yy HH:mm")) %>%
group_by(pickup_time) %>%
summarize(n = n(),
trip_duration_mean = mean(trip_duration),
trip_duration_p10 = percentile(trip_duration, 0.10),
trip_duration_p25 = percentile(trip_duration, 0.25),
trip_duration_p50 = percentile(trip_duration, 0.50),
trip_duration_p75 = percentile(trip_duration, 0.75),
trip_duration_p90 = percentile(trip_duration, 0.90)) %>%
collect()
ggplot(trip_duration_tbl, aes(x = pickup_time)) +
geom_line(aes(y = trip_duration_p50, alpha = "Median")) +
geom_ribbon(aes(ymin = trip_duration_p25, ymax = trip_duration_p75,
alpha = "25–75th percentile")) +
geom_ribbon(aes(ymin = trip_duration_p10, ymax = trip_duration_p90,
alpha = "10–90th percentile")) +
scale_y_continuous("Trip Duration (in seconds)") +
scale_x_continuous("Pickup Time of the day")この図から、乗車平均時間は 10 分~ 12 分であったと言えます。一部、午前 1 時頃に乗車時間が 30 分を越える希なピーク時間が見られました。
次のステップ
この投稿記事の目標の 1 つ目は、エッジノードまたは Amazon EMR クライアントを Amazon EC2 インスタンス上に作成する方法を解説することです。2 つ目は、他のアプリケーション、このケースでは RStudio がどのようにエッジノードまたは Amazon EMR クライアントを使用してワークロードをリモートで発行するかを紹介することです。この同じアプローチを使用して、他の Hadoop アプリケーション (Hive クライアント、Oozieクライアント、HBaseクライアントなど) のエッジノードを作成することもできます。データサイエンティストは追加パッケージを追加することで、R 環境を強化しつつ、開発者を EMR 環境から完全に切り離すことができます。このソリューションをさらに強化し、本番環境で利用できるようにするには、以下のオプションをご覧ください。- Amazon EMR インターフェイス用の使いやすい URL をご使用ください。たとえば、hive.metastore.uris の値用に、thrift://ip-10-0-20-253.ec2.internal:9083 の代わりに、thrift://hive-metastore.dev.example.corp:9083 のようなものを使用できます。同様に、yarn.resourcemanager.address のプロパティ値に ip-10-0-20-253.ec2.internal:8032 を使用する代わりに、dev.emr.example.corp:8032 を使用できます。このアプローチの利点は、EMR クラスターを取り除いても (新しい IP アドレスで) 再作成することが可能である点です。クライアントノードの構成を変更する必要はありません。このブログ投稿記事では Amazon EMR に使いやすい URL を作成する方法を解説しています。
- すでに Amazon EMR クラスターに Microsoft Active Directory を統合している場合は、RStudio でも同じことを実行可能です。その場合、データ分析ソリューションにシングルサインオン方式を導入できます。
- エッジノードの動向をモニタリングしたり、別のシナリオ (ディスクスペースの使用状況、メモリの市場状況など) 用にアラートをトリガーしたりするには、詳細な Amazon CloudWatch logs を有効化します。このアプローチを使用することで、潜在的な故障が起こる前に、データサイエンティストに前もって伝えることができます。
- H20 は R で使用される人気のあるパッケージの 1 つです。ユーザーが独自のデータでパターンを検出するために、潜在的な多数のモデルを適用できるオープンソース型のソフトウェアです。このソリューションで Sparklyr がインストールされたのと同じように、CRAN を使用して、H20 をインストールできます。RStudio でこれを実行できます。代わりに、install-client-and-rstudio.sh にそれを配置することで、インストールプロセスの一部として H20 パッケージを追加することもできます。
install.packages("h2o")
library(h2o)
localH2O = h2o.init()共通の問題
すべての可能性のあるシナリオをすべて網羅するのは困難ですが (これらは AWS 環境により異なるため)、この章では生じる可能性のある共通の問題とその解決方法について説明します。問題 1: RStudio Server の URL をクリックすると「There is no Internet connection」(インターネット接続がありません) というエラーが返る。
ソリューション: ブラウザ内で FoxyProxy を構成したこと、RStudio EC2 インスタンスのパブリック IP アドレスに接続していることを確認してください。このアドレスは AWS CloudFormation コンソールの Outputs タブから確認できます。
問題 2: EMR のステップジョブ CreateClientDeps が失敗する。
ソリューション: この EMR ステップジョブは、create-emr-client.sh スクリプトを実行します。このスクリプトはすべての必須依存関係を持ったアーカイブを作成し、それを S3 ロケーションにアップロードします。エッジノードが S3 への書き込みアクセス許可がない場合は、このステップジョブが失敗します。このソリューションでは、また、デフォルトの EMR ロール EMR_EC2_DefaultRole がエッジノードインスタンスに割り当てられています。EMR_EC2_DefaultRole には、CloudFormation パラメータ S3TempUploadPath によって付与された S3 ロケーションへの書き込みアクセスがあるものと想定しています。
問題 3: AWS CloudFormation テンプレート Blog-EMR-Edge-Node-With-RStudio がタイムアウトを起こす、または失敗する。
ソリューション: install-client-and-rstudio.sh という名前のスクリプトが、エッジノードの cfn-init を介して実行されます。また、これは、/tmp/edge-node-rstudio-installation.log ファイルにログを書き込みます。このスクリプトにはスリープ節が含まれ、S3 で awsemrdeps.tgz が利用できるようになるまで待機します。この節は20分後にタイムアウトします。スクリプトが指定された時間内にこのファイルを見つけ出せないと、その後の実行は失敗します。また、このソリューションでは、RStudio はパッケージのインストール中に、 http://cran.rstudio.com/ を repo として使用します。Amazon EC2 インスタンスがインターネットに接続できない場合は、インスタンスはそのパッケージをダウンロードしてインストールできないため、テンプレートが失敗する場合があります。エッジノードの NAT を備えたパブリックサブネットかプライベートサブネットを選ぶようにしてください。
問題 4: Amazon EMR クライアントのテスト中に、Spark のサンプルアプリケーションが、NoClassdefFounderror または UnsupportedOperationException エラーで失敗する。
ソリューション: このブログ記事では、Amazon EMR 5.16.0 を使用しています。EMR リリースに対応した Hadoop および Spark のバージョンを使用するようにしてください。マスタ―ノードのアプリケーションバージョンが、エッジノードのアプリケーションバージョンと異なる場合は、クライアントが NoClassdefFounderror または UnsupportedOperationException エラーで失敗する可能性があります。両方のロケーションで常に Hadoop と Spark の同一バージョンをインストールするようにしてください。
クリーンアップ
このソリューションのテストを終えたら、AWS CloudFormation を使用して作成した AWS リソースをすべて削除してください。Blog-EMR-Edge-Node-With-RStudio というスタックネームを削除するには、AWS CloudFormation コンソールか、AWS CLI を使用します。概要
この投稿記事では、Amazon EMR にクライアントを作成する方法をご紹介しました。また、そのクライアントノードに RStudio をインストールする方法と、Amazon EMR で稼動している Apache Spark クラスターに接続する方法もご覧に入れました。Spark に接続するために Sparklyr を使用し、HDFS と S3 の両方からのデータを消費し、R モデルを使用してデータを分析しました。次は皆さんの番です。このソリューションを試して、皆さんの体験をお聞かせください。その他の参考資料
この記事が参考になった場合は、Running sparklyr – RStudio’s R Interface to Spark on Amazon EMR、Statistical Analysis with Open-Source R and RStudio on Amazon EMR、および Running R on Amazon Athena もご覧ください。今回のブログ投稿者について
Tanzir Musabbir は AWS の EMR スペシャリストソリューションアーキテクトです。彼はオープンソース型ビッグデータテクノロジーをいち早く採り入れた人物です。AWS において、彼はお客様と協力しながら、Amazon EMR、Amazon Athena 、AWS Glue の分析ソリューションを実行するための構造的なガイダンスを提供しています。Tanzir はリアルマドリードの大ファンで、余暇には旅に出るのが好きです。
コメント
コメントを投稿