Amazon SageMaker ランダムカットフォレストアルゴリズムを使用した Amazon DynamoDB ストリームでの異常検出
Amazon SageMaker ランダムカットフォレストアルゴリズムを使用した Amazon DynamoDB ストリームでの異常検出:
異常検出技術の導入を検討したことがありますか? 異常検出とは、分析しているデータの大部分と大きく異なるため信憑性にかける、あまり見かけないアイテム、イベント、あるいは観察を特定するために使用する手法です。 異常検出のアプリケーションは幅広い分野で利用されており、例えば、異常購入や銀行へのサイバー侵入の検出、MRI スキャンでの悪性腫瘍の発見、不正な保険請求の特定、製造時の異常な機械動作の発見、侵入を知らせるネットワークトラフィックの異常なパターンの検出などがあります。
こうしたアプリケーションには多くの市販品がありますが、Amazon SageMaker、AWS Glue、AWS Lambda を使えば、異常検出システムを簡単に実装することができます。Amazon SageMaker は、機械学習モデルの構築、トレーニング、デプロイを、規模を問わず迅速に行う完全マネージド型プラットフォームです。AWS Glue は、完全マネージド型の ETL サービスで、分析のためのデータやモデルの準備が簡単にできます。AWS Lambda は、普及しているサーバーレスのリアルタイムプラットフォームです。これらのサービスを使用すれば、モデルを新しいデータで自動的に更新することができ、その新しいモデルを使って、リアルタイムに異常をより正確に知らせることができます。
このブログ記事では、AWS Glue でデータを準備し、Amazon SageMaker で異常検出モデルをトレーニングする方法について説明します。今回のエクササイズでは、Numenta Anomaly Benchmark (NAB) ニューヨーク市タクシーデータのサンプルを Amazon DynamoDB に保存し、AWS Lambda 関数を用いてリアルタイムでストリーミングしています。
ここで説明するソリューションは、以下のような利点があります。
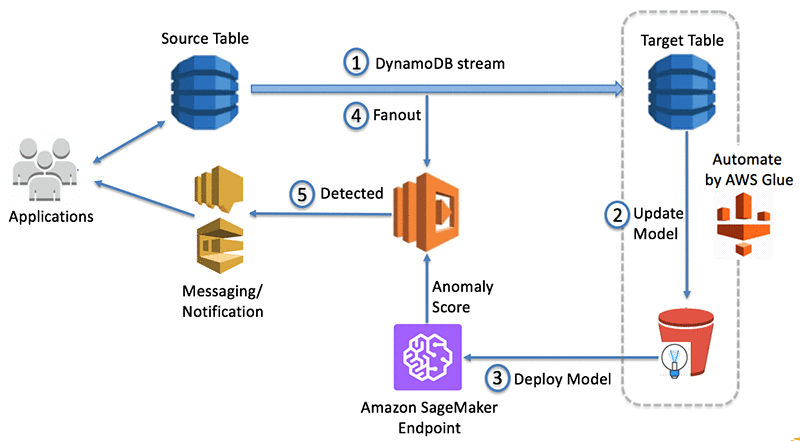
アーキテクチャーにおけるデータ処理の手順は、次のとおりです。
この例では、米国東部 (オハイオ) (us-east-2) リージョン内の DynamoDB テーブル (“taxi_ridership”) は、DynamoDB の「グローバルテーブル」を使用して、米国東部(バージニア北部) (us-east-1) リージョン内の同じ名前を持つ別の DynamoDB テーブルにレプリケートしています。

さらに、
最後に、AWS Glue ジョブは、DynamoDB テーブルが存在する同じリージョン (このブログの投稿では us-east-1) に作成する必要があります。AWS Glue ジョブの作成の詳細については、「AWS Glue でジョブを追加する」を参照してください。
この AWS Glue ジョブは、CSV ファイルを Amazon S3 上の指定されたパスに書き込みます ( “s3://<bucket name>/<project name>/taxi-ridership-rawdata/” )。
モデルの作成が成功したら、Amazon SageMaker コンソールに日付形式の新しいモデル名が表示されます。

各データポイントについて推論 (= 異常スコア) を取得したら、リアルタイムでの異常検出に使用する
バッチ変換ジョブの履歴は、Amazon SageMaker コンソールの [Batch transform jobs] メニューにあります。

これで Amazon SageMaker エンドポイントが作成され、AWS Glue ジョブが完了しました。AWS Glue コンソールの [Logs] のリンクを選択すると、AWS Glue ジョブの詳細ログを確認できます。




Amazon CloudWatch の出力ログの例を、次に示します。DynamoDB には

AWS Glue はユーザーのスクリプトに基づく柔軟性が大きく、新しいデータソースを追加し続けるため、今回の例を自身の特定のユースケースに合わせることができます。AWS Lambda 機能は他の多くの AWS ストリーミングサービスでも機能するので、他の種類のデータソースやストリームをこのアーキテクチャに適用することも可能です。
最後に、この記事の異常検出システムで、ビジネスリスクを回避し、コストを削減できることを期待しています。
 Yong Seong Lee は AWS ビッグデータサービスのクラウドサポートエンジニアです。ビッグデータやデータ解析、機械学習のテクノロジーならなんでも関心があります。AWS サービスの利用に苦戦しているお客様へのサポートが彼の仕事です。「人生を楽しむ。好奇心を持つ。これ以上ないほどの経験をする。」というのが、彼のモットーです。
Yong Seong Lee は AWS ビッグデータサービスのクラウドサポートエンジニアです。ビッグデータやデータ解析、機械学習のテクノロジーならなんでも関心があります。AWS サービスの利用に苦戦しているお客様へのサポートが彼の仕事です。「人生を楽しむ。好奇心を持つ。これ以上ないほどの経験をする。」というのが、彼のモットーです。
異常検出技術の導入を検討したことがありますか? 異常検出とは、分析しているデータの大部分と大きく異なるため信憑性にかける、あまり見かけないアイテム、イベント、あるいは観察を特定するために使用する手法です。 異常検出のアプリケーションは幅広い分野で利用されており、例えば、異常購入や銀行へのサイバー侵入の検出、MRI スキャンでの悪性腫瘍の発見、不正な保険請求の特定、製造時の異常な機械動作の発見、侵入を知らせるネットワークトラフィックの異常なパターンの検出などがあります。
こうしたアプリケーションには多くの市販品がありますが、Amazon SageMaker、AWS Glue、AWS Lambda を使えば、異常検出システムを簡単に実装することができます。Amazon SageMaker は、機械学習モデルの構築、トレーニング、デプロイを、規模を問わず迅速に行う完全マネージド型プラットフォームです。AWS Glue は、完全マネージド型の ETL サービスで、分析のためのデータやモデルの準備が簡単にできます。AWS Lambda は、普及しているサーバーレスのリアルタイムプラットフォームです。これらのサービスを使用すれば、モデルを新しいデータで自動的に更新することができ、その新しいモデルを使って、リアルタイムに異常をより正確に知らせることができます。
このブログ記事では、AWS Glue でデータを準備し、Amazon SageMaker で異常検出モデルをトレーニングする方法について説明します。今回のエクササイズでは、Numenta Anomaly Benchmark (NAB) ニューヨーク市タクシーデータのサンプルを Amazon DynamoDB に保存し、AWS Lambda 関数を用いてリアルタイムでストリーミングしています。
ここで説明するソリューションは、以下のような利点があります。
- 既存のリソースを最大限に活用して、異常検出を行います。例えば、災害対策 (DR) やその他の目的で Amazon DynamoDB Streams を使用したことがある場合、そのストリームのデータを異常検出に使用できます。加えて、スタンバイストレージは通常、使用率が低いものです。認識しにくいデータは、トレーニングデータに使用できます。
- ユーザーの介入なしに、定期的に新しいデータでモデルを自動的に再トレーニングすることができます。
- ランダムカットフォレストを組み込んだ Amazon SageMaker アルゴリズムを使えば、簡単に再トレーニングできます。Amazon SageMaker は、安全でスケーラブルな環境で、特定のワークフローに適応できる、柔軟な分散トレーニングオプションを提供します。
ソリューションのアーキテクチャ
次の図は、ソリューションの全体的なアーキテクチャを示しています。アーキテクチャーにおけるデータ処理の手順は、次のとおりです。
- ソース DynamoDB は変更を取得し、それらを DynamoDB ストリームに格納します。
- AWS Glue ジョブは、ターゲット DynamoDB テーブルから定期的にデータを取得し、Amazon S3 でモデルアーティファクトを作成または更新するために Amazon SageMaker を使用してトレーニングジョブを実行します。
- 同じ AWS Glue ジョブは、ランダムカットフォレストに基づくリアルタイムでの異常検出に、Amazon SageMaker エンドポイントで更新されたモデルをデプロイします。
- AWS Lambda 関数は、DynamoDB ストリームからデータをポーリングし、Amazon SageMaker エンドポイントを呼び出して推論を取得します。
- Lambda 関数は、異常を検出すると、ユーザーアプリケーションに知らせます。
自動更新モデルの構築
このセクションでは、AWS Glue が DynamoDB テーブルを読み込み、Amazon SageMaker のモデルを自動的にトレーニングおよびデプロイする方法について説明します。ここでは、DynamoDB ストリームがすでに有効になっており、DynamoDB アイテムがストリームに書き込まれているとします。これらをまだ設定していない場合は、次のドキュメントを参照して詳細を確認してください。「DynamoDB ストリーム を使用したテーブルアクティビティのキャプチャ」、「DynamoDB ストリーム と AWS Lambda のトリガー」、および「グローバルテーブル」。この例では、米国東部 (オハイオ) (us-east-2) リージョン内の DynamoDB テーブル (“taxi_ridership”) は、DynamoDB の「グローバルテーブル」を使用して、米国東部(バージニア北部) (us-east-1) リージョン内の同じ名前を持つ別の DynamoDB テーブルにレプリケートしています。
AWS Glue ジョブを作成し、データを準備する
モデルトレーニングのデータを準備するために、データを DynamoDB に保存します。AWS Glue ジョブはcreate_dynamic_frame_from_options() を使い、dynamodb connection_type 引数を用いて、ターゲット DynamoDB テーブルからデータを取得します。DynamoDB からデータを取り出す場合は、モデルトレーニングに必要な列のみを選択し、Amazon S3 に CSV ファイルとして書き込むことをお勧めします。 これは、AWS Glue の ApplyMapping.apply() 関数を使って、行うことができます。この例では、transaction_id と ridecount 列のみがマッピングされています。さらに、
write_dynamic_frame.from_options 関数を実行する時は、format_options = {"writeHeader":False , "quoteChar":"-1"} のオプションを追加する必要があります。列の名前と二重引用符 (” ‘) は、モデルのトレーニングには必要ないためです。最後に、AWS Glue ジョブは、DynamoDB テーブルが存在する同じリージョン (このブログの投稿では us-east-1) に作成する必要があります。AWS Glue ジョブの作成の詳細については、「AWS Glue でジョブを追加する」を参照してください。
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.job import Job
## @params: [JOB_NAME]
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
job = Job(glueContext)
job.init(args['JOB_NAME'], args)
my_region = '<region name>'
my_bucket = '<bucket name>'
my_project = '<project name>'
my_train_data = "s3://{}/{}/taxi-ridership-rawdata/".format(my_bucket , my_project )
my_dynamodb_table = "taxi_ridership"
## Read raw(source) data from target DynamoDB
raw_data_dyf = glueContext.create_dynamic_frame_from_options("dynamodb", {"dynamodb.input.tableName" : my_dynamodb_table , "dynamodb.throughput.read.percent" : "0.7" } , transformation_ctx="raw_data_dyf" )
## Write necessary columns into S3 as CSV format for creating Random Cut Forest(RCF) model
selected_data_dyf = ApplyMapping.apply(frame = raw_data_dyf, mappings = [("transaction_id", "string", "transaction_id", "string"), ("ridecount", "string", "ridecount", "string")], transformation_ctx = "selected_data_dyf")
datasink = glueContext.write_dynamic_frame.from_options(frame=selected_data_dyf , connection_type="s3", connection_options={ "path": my_train_data }, format="csv", format_options = {"writeHeader": False , "quoteChar": "-1" }, transformation_ctx="datasink")

トレーニングジョブを実行し、モデルを更新する
データが準備できたら、Amazon SageMaker でトレーニングジョブを実行できます。トレーニングジョブを Amazon SageMaker に送信するには、AWS Glue ETL スクリプトが自動的にバンドルしている boto3 パッケージをインポートする必要があります。これで、AWS Glue ETL スクリプトで Python 用の低レベル SDK を使用することができます。トレーニングジョブの作成方法の詳細については、「ステップ 3.3.2: トレーニングジョブを作成する」を参照してください。Create_training_job 関数は、指定した S3 のパスにモデルアーティファクトを作成します。これらのモデルアーティファクトは、次のステップでモデルを作成するために必要です。## Execute training job with CSV data and create model artifacts for RCF
import boto3
from time import gmtime, strftime
sagemaker = boto3.client('sagemaker', region_name= my_region)
job_name = 'randomcutforest-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
sagemaker_role = "arn:aws:iam::<account id>:role/service-role/<AmazonSageMaker-ExecutionRole-Name>"
containers = {
'us-west-2': '174872318107.dkr.ecr.us-west-2.amazonaws.com/randomcutforest:latest',
'us-east-1': '382416733822.dkr.ecr.us-east-1.amazonaws.com/randomcutforest:latest',
'us-east-2': '404615174143.dkr.ecr.us-east-2.amazonaws.com/randomcutforest:latest',
'eu-west-1': '438346466558.dkr.ecr.eu-west-1.amazonaws.com/randomcutforest:latest'}
image = containers[my_region]
artifacts_location = 's3://{}/{}/artifacts'.format(my_bucket , my_project )
print('myINFO : training artifacts will be uploaded to: {}'.format(artifacts_location))
create_training_params = \
{
"AlgorithmSpecification": { "TrainingImage": image, "TrainingInputMode": "File" },
"RoleArn": sagemaker_role, "OutputDataConfig": {"S3OutputPath": artifacts_location },
"ResourceConfig": { "InstanceCount": 2, "InstanceType": "ml.c4.xlarge", "VolumeSizeInGB": 50 },
"TrainingJobName": job_name,
"HyperParameters": { "num_samples_per_tree": "200", "num_trees": "50", "feature_dim": "2" },
"StoppingCondition": { "MaxRuntimeInSeconds": 60 * 60 },
"InputDataConfig": [
{
"ChannelName": "train",
"ContentType": "text/csv;label_size=0",
"DataSource": {
"S3DataSource": {"S3DataType": "S3Prefix", "S3Uri": my_train_data, "S3DataDistributionType": "ShardedByS3Key" }
},
"CompressionType": "None",
"RecordWrapperType": "None"
}
]
}
sagemaker.create_training_job(**create_training_params)
status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus']
print('myINFO : Status of {} traning job ==> {}'.format(job_name , status ))
try:
sagemaker.get_waiter('training_job_completed_or_stopped').wait(TrainingJobName=job_name)
finally:
status = sagemaker.describe_training_job(TrainingJobName=job_name)['TrainingJobStatus']
print("myINFO : Training job ended with status: " + status)
if status == 'Failed':
message = sagemaker.describe_training_job(TrainingJobName=job_name)['FailureReason']
print('myINFO : Training failed with the following error: {}'.format(message))
raise Exception('Training job failed')
## Create Model from model artifacts
model_name=job_name
print("myINFO : Model name - {}".format(model_name))
info = sagemaker.describe_training_job(TrainingJobName=job_name)
model_data = info['ModelArtifacts']['S3ModelArtifacts']
primary_container = {'Image': image, 'ModelDataUrl': model_data }
create_model_response = sagemaker.create_model(
ModelName = model_name,
ExecutionRoleArn = sagemaker_role,
PrimaryContainer = primary_container)
print("myINFO : Created Model ARN : {}".format( create_model_response['ModelArn']))
バッチ変換を実行し、カットオフスコアを取得する
このトレーニング済みモデルを使用して、各トレーニングデータポイントの異常スコアを計算することができます。使用するデータ量が多いので、Amazon SageMaker のバッチ変換機能 を使用します。バッチ変換機能は、トレーニング済みモデルを使って Amazon S3 のデータセット全体の推論を取得し、バッチ変換ジョブの作成時に指定する S3 バケットに推論を保存します。各データポイントについて推論 (= 異常スコア) を取得したら、リアルタイムでの異常検出に使用する
score_cutoff 値を取得する必要があります。簡素化するため、標準的な手法を使って異常を分類しました。平均スコアから 3σ (シグマ) の範囲より外れる異常スコアを、異常とみなします。## Execute Batch Transform in order to calculate anomaly scores and the value of score cutoff.
## score cutoff will be used in Lambda function in real time to identify anomalous transaction
import time
batch_job_name = 'Batch-Transform-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
batch_output = "s3://{}/{}/batch_output/".format(my_bucket , my_project )
request = {
"TransformJobName": batch_job_name,
"ModelName": model_name,
"MaxConcurrentTransforms": 1,
"TransformOutput": { "S3OutputPath": batch_output },
"TransformInput" : {
"ContentType": "text/csv;label_size=0",
"DataSource" : {
"S3DataSource": { "S3DataType": "S3Prefix", "S3Uri": my_train_data }
}
},
"TransformResources": { "InstanceType": "ml.m4.xlarge","InstanceCount": 1 }
}
response = sagemaker.create_transform_job(**request)
batch_status = 'InProgress'
while batch_status == 'InProgress':
batch_status = sagemaker.describe_transform_job( TransformJobName=batch_job_name)['TransformJobStatus']
print("myINFO : Batch job {} in Progress ".format( batch_job_name ))
time.sleep(10)
if batch_status == 'Failed':
message = sagemaker.describe_transform_job(TransformJobName=batch_job_name)['FailureReason']
print('myINFO : Transforming job failed with the following error: {}'.format(message))
raise Exception('Transforming job failed')
## Calculate score_cutoff from the result of Batch-Transform
from pyspark.sql.functions import mean, stddev
from decimal import Decimal
all_scores_dfy = glueContext.create_dynamic_frame_from_options("s3", {'paths': [ batch_output ]}, format="json", transformation_ctx = "all_scores_dfy" ).toDF()
score_mean = all_scores_dfy.agg(mean(all_scores_dfy["score"]).alias("mean")).collect()[0]["mean"]
score_stddev = all_scores_dfy.agg(stddev(all_scores_dfy["score"]).alias("stddev")).collect()[0]["stddev"]
score_cutoff = Decimal( str( score_mean + 3*score_stddev ) )
print("myINFO : RFC score cutoff : {}".format( score_cutoff))
モデルをデプロイし、カットオフスコアを更新する
AWS Glue ETL スクリプトでの最終ステップは、更新したモデルを Amazon SageMaker エンドポイントにデプロイし、取得したscore_cutoff の値をリアルタイム異常検出用の DynamoDB テーブルにアップロードすることです。Lambda 関数は、DynamoDB の score_cutoff の値をクエリして、新しいトランザクションの異常スコアと比較します。## Create Endpoint Configuration for realtime service
endpoint_config_name = 'randomcutforest-endpointconfig-' + strftime("%Y-%m-%d-%H-%M-%S", gmtime())
create_endpoint_config_response = sagemaker.create_endpoint_config(
EndpointConfigName = endpoint_config_name,
ProductionVariants=[{ 'InstanceType':'ml.m4.xlarge', 'InitialInstanceCount':1, 'ModelName':model_name, 'VariantName':'AllTraffic'}]
)
print("myINFO : Endpoint Config Arn: " + create_endpoint_config_response['EndpointConfigArn'] )
## Create/Update Endpoint with new configuration that has updated model.
endpoint_name = 'randomcutforest-endpoint'
endpoint_status = ""
try:
endpoint_status = sagemaker.describe_endpoint(EndpointName=endpoint_name)['EndpointStatus']
except Exception as e :
endpoint_status = "NotInService"
print("myINFO : randomcutforest-endpoint Status: " + status)
if endpoint_status == 'InService':
update_endpoint_response = sagemaker.update_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name)
try:
sagemaker.get_waiter('endpoint_in_service').wait(EndpointName=endpoint_name)
finally:
resp = sagemaker.describe_endpoint(EndpointName=endpoint_name)
status = resp['EndpointStatus']
print("myINFO : Update endpoint {} ended with {} status: ".format( resp['EndpointArn'] , status ) )
if status != 'InService':
message = sagemaker.describe_endpoint(EndpointName=endpoint_name)['FailureReason']
print('myINFO : Endpoint update failed with the following error: {}'.format(message))
raise Exception('Endpoint update did not succeed')
else:
create_endpoint_response = sagemaker.create_endpoint( EndpointName=endpoint_name, EndpointConfigName=endpoint_config_name)
try:
sagemaker.get_waiter('endpoint_in_service').wait(EndpointName=endpoint_name)
finally:
resp = sagemaker.describe_endpoint(EndpointName=endpoint_name)
status = resp['EndpointStatus']
print("myINFO : Create endpoint {} ended with {} status: ".format( resp['EndpointArn'] , status ) )
if status != 'InService':
message = sagemaker.describe_endpoint(EndpointName=endpoint_name)['FailureReason']
print('myINFO : Endpoint creation failed with the following error: {}'.format(message))
raise Exception('Endpoint creation did not succeed')
## Add the score_cutoff value into DynamoDB
## score_cutoff will be queried by Lambda function for real time abnormal detection
dynamodb_table = boto3.resource('dynamodb', region_name= my_region).Table('anomaly_cut_off')
dynamodb_table.put_item(Item= {'data_kind': my_dynamodb_table ,'update_time': strftime("%Y%m%d%H%M%S", gmtime()), 'score_cutoff': score_cutoff })
print('myINFO : New score_cutoff value has been updated in DynamoDB table.')
## Delete Temporary data to save cost.
s3 = boto3.resource('s3').Bucket(my_bucket )
s3.objects.filter(Prefix="{}/taxi-ridership-rawdata".format(my_project)).delete()
s3.objects.filter(Prefix="{}/batch_output".format(my_project)).delete()
print('myINFO : Temporary S3 objects have been deleted.')
## End job
job.commit()Score_cutoff の値は、パーティションキーが taxi-ridership で、範囲キーが最新の更新時間である DynamoDB テーブルに格納されます。AWS Glue ジョブをスケジューリングする
前出のスクリプトは同じ AWS Glue ジョブで実行されており、AWS Glue はトリガーを作成して、時間ベースのスケジュールをサポートします。時間ベースのスケジュールを定義し、それを自身のジョブに関連付けると、定期的に新しいデータでモデルを再トレーニングすることができます。 モデルをあまり頻繁に更新する必要はないと思います。 毎週か隔週での更新で十分でしょう。リアルタイムでの異常検出
このセクションでは、AWS Lambda 関数からリアルタイムで、異常なトランザクションを検出する方法について説明します。DynamoDB ストリームをポーリングするには、AWS Lambda 関数を作成する必要があります。AWS Lambda 関数を作成する際、「dynamodb-process-stream-python3」ブループリントを使えば、迅速に実装することができます。ブループリントの Lambda 関数は、指定した DynamoDB テーブルと統合することができます。ブループリントは、基本的な Lambda コードを提供します。各データポイントで異常スコアを取得する
Lambda 関数のコードを、簡単に説明します。新しいデータのため、INSERT イベントと MODIFY イベントのみをフィルタリングします。 Lambda 関数は、それらをインスタンス配列に追加し、配列内のイベント全体の推論を取得します。Amazon SageMaker ランダムカットフォレストアルゴリズムは、複数のレコードを入力要求として受け入れ、マルチレコードの推論を返してミニバッチの予測をサポートします。詳細は、「一般的なデータ形式 — 推論」を参照してください。import json
import boto3
from boto3.dynamodb.conditions import Key, Attr
print("Starting Lambda Function.... ")
sagemaker = boto3.client('sagemaker-runtime', region_name ='<region name>' )
dynamodb_table = boto3.resource('dynamodb', region_name='us-east-1').Table('anomaly_cut_off')
def lambda_handler(event, context):
#print("Received event: " + json.dumps(event, indent=2))
transaction_data = {} # key : transaction_id / value : ridecount
for record in event['Records']:
## filter only INSERT or MODIFY event and add to "transaction_data" dictionary
if record['eventName'] == "INSERT" or record['eventName'] == "MODIFY":
transaction_id = record['dynamodb']['NewImage']['transaction_id']['S']
ridecount = record['dynamodb']['NewImage']['ridecount']['S']
transaction_data[transaction_id] = ridecount
print( "transaction_data: " + str(transaction_data ))
features=[]
features_dic={}
instances=[]
instances_dic={} # example, {'instances': [{'features': ['10231', '3837']}, {'features': ['10232', '10844']}]}
for key in transaction_data.keys():
features.append(key)
features.append(transaction_data[key])
features_dic["features"] = features
instances.append(features_dic)
features=[]
features_dic={}
instances_dic["instances"] = instances
transaction_json = json.dumps(instances_dic) # To make argument format for invoke_endpoint method.
異常なトランザクションのアラート
機能の配列は、sagemaker.invoke_endpoint 関数に送信できます。インスタンス配列の各機能に対応するスコアの配列を返します。DynamoDB テーブルから取得した score_cutoff の最新値に応じて、各スコアを比較できます。新しいトランザクションの異常スコアが score_cutoff の値より大きい場合、そのトランザクションを異常とみなします。その後、Lambda 関数はユーザーアプリケーションに知らせます。 response = sagemaker.invoke_endpoint( EndpointName='randomcutforest-endpoint', Body=transaction_json , ContentType='application/json' )
scores_result = json.loads(response['Body'].read().decode())
print("Result score : "+ str(scores_result)) # return an array of score
response = dynamodb_table.query(
Limit = 1,
ScanIndexForward = False,
KeyConditionExpression=Key('data_kind').eq('taxi_ridership') & Key('update_time').lte('99990000000000')
)
socre_cutoff = response['Items'][0]['score_cutoff']
print("socre cutoff : " + str(socre_cutoff) )
for index in range(len(scores_result['scores'])):
if scores_result['scores'][index]['score'] > socre_cutoff:
print("Detected abnormal transaction ID : {} , Ridecount : {}".format(instances[index]['features'][0], instances[index]['features'][1] ))
## Add your codes to send a notification
return 'Successfully processed {} records.'.format(len(event['Records']))
10231 と 21101 の 2 つのトランザクションが作成され、これらのトランザクションによって Lambda 関数が新しいイベントとしてトリガーされました。21101 のトランザクションの異常スコアは、3.6189932108 です。これは、DynamoDB テーブルのカットオフ値 (1.31462299965) よりも大きいため、トランザクションは異常であると検出されます。結論
このブログ投稿では、Amazon SageMaker、AWS Glue、および AWS Lambda を使用して、Amazon DynamoDB ストリームで異常検出システムを構築する方法を紹介しました。AWS Glue はユーザーのスクリプトに基づく柔軟性が大きく、新しいデータソースを追加し続けるため、今回の例を自身の特定のユースケースに合わせることができます。AWS Lambda 機能は他の多くの AWS ストリーミングサービスでも機能するので、他の種類のデータソースやストリームをこのアーキテクチャに適用することも可能です。
最後に、この記事の異常検出システムで、ビジネスリスクを回避し、コストを削減できることを期待しています。
著者について
Yong Seong Lee は AWS ビッグデータサービスのクラウドサポートエンジニアです。ビッグデータやデータ解析、機械学習のテクノロジーならなんでも関心があります。AWS サービスの利用に苦戦しているお客様へのサポートが彼の仕事です。「人生を楽しむ。好奇心を持つ。これ以上ないほどの経験をする。」というのが、彼のモットーです。
コメント
コメントを投稿