Amazon Athena で CTAS ステートメントを使用して、コストを削減し、パフォーマンスを向上させる
Amazon Athena で CTAS ステートメントを使用して、コストを削減し、パフォーマンスを向上させる:
Amazon Athena は、標準 SQL を使用して Amazon S3 でのデータの分析を簡易化するインタラクティブなクエリサービスです。Athena はサーバーレスであるため、インフラストラクチャの管理は不要であり、実行したクエリにのみ課金されます。Athena は最近、SELECT クエリまたは CREATE TABLE AS SELECT (CTAS) ステートメントの結果を使用するテーブルの作成のサポートをリリースしました。 アナリストは、CTAS ステートメントを使用して、データのサブセットまたは列のサブセット上の既存のテーブルから新しいテーブルを作成することができます。また、Apache Parquet や Apache ORC などのカラムナ形式にデータを変換し、分割するオプションもあります。Athena は、結果として得られたテーブルとパーティションを AWS Glue データカタログに自動的に追加し、その後のクエリですぐに使用できるようにします。
CTAS ステートメントは、大きなテーブルから構築された小さなテーブルでクエリを実行できるようにすることで、コストを削減し、パフォーマンスを向上させます。この記事では、元のデータセットよりも小さい新しいデータセットを作成し、その後のクエリをより高速に実行できるという、CTAS の使用の利点を示す 3 つのユースケースについて説明します。これらのユースケースではデータを繰り返し照会する必要があると想定して、より小さく、より最適なデータセットを照会して、より迅速に結果を取得できるようになりました。
この記事では、CloudTrail テーブルの名前が「cloudtrail_logs」であり、そのテーブルが default データベースに存在することを前提としています。
次のクエリは、最近 30 日間の Athena イベントを使用します。「athena_30_days」と呼ばれる新しいテーブルを作成し、データファイルを Parquet 形式で保存します。
元の CloudTrail データに対してこのクエリを実行すると、実行には 5 分ほどかかり、14 GB 程度のデータをスキャンします。これは、未加工データが JSON 形式であり、十分に分割されていないためです。 新たに作成したテーブルで SELECT * を実行すると、1.7 秒かかり、1.14MB のデータをスキャンします。
これで、複数のクエリを実行したり、縮小したデータセットでダッシュボードを構築することができます。
たとえば、次のクエリは、それぞれの Athena API の合計数を集計し、結果を IAM ユーザー、日付、API イベント名でグループ化します。 このクエリは、わずか 1.8 秒で完了しました。
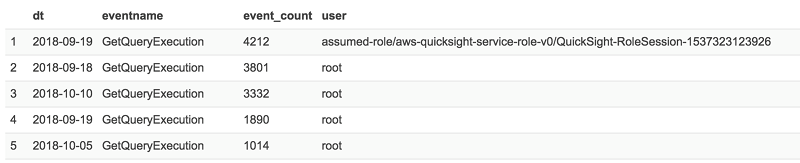
前のクエリの例は、Athena サービスによって呼び出された最近 30 日間の S3 GetObject API イベントを返します。 これは、S3 インベントリテーブルから返された各イベントの S3 オブジェクトのサイズとストレージクラスを追加します。
次に、たとえば、Athena が各キーにアクセスした回数を数え、小から大へと回数に基づいて結果を並べ替えることができます。 これは、スキャンしているファイルのサイズと頻度を示します。これを知ることで、それらのキーで圧縮を実行して最適化する必要があるかどうかを判断するのに役立ちます。
この例の場合、次のようになります。
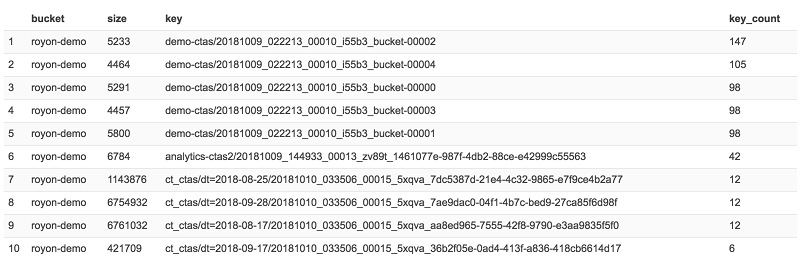
CREATE TABLE キーワードの後、AS キーワードの前に WITH 句を追加したことに注意してください。 この WITH 句で、必要なテーブルプロパティを定義できます。 この特別なケースでは、「year」と 「month」をパーティショニング列と宣言し、ORC を出力形式と定義しました。 ORC を使用した理由は、CloudTrail データに、Parquet 仕様では許可されていないが ORC では許可されている空の列が含まれている可能性があるからです。 さらに、テーブルを保存する外部 S3 の場所を定義しました。 外部の場所を定義しない場合、Athena はデフォルトのクエリ結果の S3 の場所を使用します。
結果として得られる S3 宛先バケットは、次の例のようになります。
Athena CTAS でサポートされている追加の最適化はバケット化です。 パーティショニングは、特定の列に基づいて同様のタイプのデータをグループ化するために使用されます。 バケット化は、通常、パーティション内のデータを多数の等しいグループまたはファイルに結合するために使用されます。 したがって、カーディナリティが低い列にはパーティショニングが最適であり、カーディナリティが高い列にはバケット化が最適です。 詳細については、Bucketing vs Partitioningを参照してください。
それでは、以前の CTAS の例で、バケット化を追加しましょう。
そして、S3 では次のように表示されます。
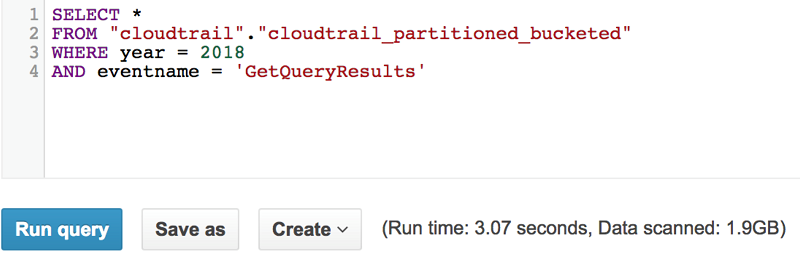
以下に、パーティショニングされたテーブルと、パーティショニングおよびバケット化されたテーブルの両方のクエリの例を示します。 速度は似ていますが、バケット化のクエリはより少ないデータしかスキャンしていないことが分かります。
パーティショニングされたテーブル:

パーティショニングおよびバケット化されたテーブル:
 Roy Hasson は、AWS Analytics のグローバルビジネス開発マネージャーです。彼は世界中の顧客と協力して、データ処理、分析、ビジネスインテリジェンスのニーズを満たすソリューションを設計しています。Roy は、マンチェスターユナイテッドの大ファンであり、家族とともにチームを応援しています。
Roy Hasson は、AWS Analytics のグローバルビジネス開発マネージャーです。彼は世界中の顧客と協力して、データ処理、分析、ビジネスインテリジェンスのニーズを満たすソリューションを設計しています。Roy は、マンチェスターユナイテッドの大ファンであり、家族とともにチームを応援しています。
Amazon Athena は、標準 SQL を使用して Amazon S3 でのデータの分析を簡易化するインタラクティブなクエリサービスです。Athena はサーバーレスであるため、インフラストラクチャの管理は不要であり、実行したクエリにのみ課金されます。Athena は最近、SELECT クエリまたは CREATE TABLE AS SELECT (CTAS) ステートメントの結果を使用するテーブルの作成のサポートをリリースしました。 アナリストは、CTAS ステートメントを使用して、データのサブセットまたは列のサブセット上の既存のテーブルから新しいテーブルを作成することができます。また、Apache Parquet や Apache ORC などのカラムナ形式にデータを変換し、分割するオプションもあります。Athena は、結果として得られたテーブルとパーティションを AWS Glue データカタログに自動的に追加し、その後のクエリですぐに使用できるようにします。
CTAS ステートメントは、大きなテーブルから構築された小さなテーブルでクエリを実行できるようにすることで、コストを削減し、パフォーマンスを向上させます。この記事では、元のデータセットよりも小さい新しいデータセットを作成し、その後のクエリをより高速に実行できるという、CTAS の使用の利点を示す 3 つのユースケースについて説明します。これらのユースケースではデータを繰り返し照会する必要があると想定して、より小さく、より最適なデータセットを照会して、より迅速に結果を取得できるようになりました。
Amazon Athena CTAS の使用
使い慣れた CREATE TABLE ステートメントは、空のテーブルを作成します。対照的に、CTAS ステートメントは SELECT クエリの結果を含む新しいテーブルを作成します。新しいテーブルのメタデータは、自動的に AWS Glue データカタログに追加されます。データファイルは、指定された場所の Amazon S3 に保存されます。CTAS を使用して新しいテーブルを作成する場合、WITH ステートメントを含めて、ファイル形式、圧縮、パーティション列などのテーブル固有のパラメータを定義することができます。使用できるパラメータの詳細については、Creating a Table from Query Results (CTAS) を参照してください。開始する前に: Athena で照会するために CloudTrail を設定する
Athena を使用して AWS CloudTrail データを照会していない場合は、これを設定することをお勧めします。手順は、次のとおりです。- CloudTrail コンソールを開きます。
- コンソールの左側で、[Event History] を選択します。
- ウィンドウの上部で、[Run advanced queries in Amazon Athena] を選択します。
- セットアップウィザードに従って、Athena テーブルを作成します。
この記事では、CloudTrail テーブルの名前が「cloudtrail_logs」であり、そのテーブルが default データベースに存在することを前提としています。
ユースケース 1: データセットのサイズを減らして繰り返しクエリを最適化する
他の AWS のサービスと同様に、Athena は AWS CloudTrail を使用して API コールを追跡します。このユースケースでは、CloudTrail を使用して Athena の使用状況を把握します。CloudTrail は、自動的に JSON 形式のデータを S3 に公開します。ここでは CTAS ステートメントを使用して、30 日間の Athena API イベントだけを含むテーブルを作成し、考慮しない他の API イベントをすべて削除します。 これにより、テーブルサイズが小さくなり、後続のクエリが改善されます。次のクエリは、最近 30 日間の Athena イベントを使用します。「athena_30_days」と呼ばれる新しいテーブルを作成し、データファイルを Parquet 形式で保存します。
CREATE TABLE athena_30_days
AS
SELECT
date(from_iso8601_timestamp(eventtime)) AS dt,
*
FROM cloudtrail_logs
WHERE eventsource = 'athena.amazonaws.com'
AND
date(from_iso8601_timestamp(eventtime))
BETWEEN current_date - interval '30' day AND current_dateこれで、複数のクエリを実行したり、縮小したデータセットでダッシュボードを構築することができます。
たとえば、次のクエリは、それぞれの Athena API の合計数を集計し、結果を IAM ユーザー、日付、API イベント名でグループ化します。 このクエリは、わずか 1.8 秒で完了しました。
SELECT
dt,
eventname,
count(eventname) as event_count,
split_part(useridentity.arn, ':', 6) as user
FROM athena_30_days
GROUP BY 1,2,4
ORDER BY event_count DESCユースケース 2: より少ない数の列を選択する
このユースケースでは、CloudTrail テーブルを S3 インベントリテーブルと結合させ、分析に関連する特定の列だけを選択します。 CTAS を使用して結果からテーブルを生成します。CREATE TABLE athena_s3_30_days
AS
SELECT
json_extract_scalar(ct.requestparameters, '$.bucketName') AS bucket,
json_extract_scalar(ct.requestparameters, '$.key') AS key,
ct.useridentity.username AS username,
ct.eventname,
cast (from_iso8601_timestamp(ct.eventtime) as timestamp) as ts,
s3.storage_class,
s3.size
FROM cloudtrail_logs ct
JOIN s3inventory s3
ON json_extract_scalar(ct.requestparameters, '$.bucketName') = s3.bucket
AND json_extract_scalar(ct.requestparameters, '$.key') = s3.key
AND date(from_iso8601_timestamp(ct.eventtime)) = date(s3.last_modified_date)
WHERE ct.eventsource = 's3.amazonaws.com'
AND ct.eventname = 'GetObject'
AND ct.useridentity.invokedby LIKE '%athena%'
AND date(from_iso8601_timestamp(eventtime))
BETWEEN current_date - interval '30' day AND current_date次に、たとえば、Athena が各キーにアクセスした回数を数え、小から大へと回数に基づいて結果を並べ替えることができます。 これは、スキャンしているファイルのサイズと頻度を示します。これを知ることで、それらのキーで圧縮を実行して最適化する必要があるかどうかを判断するのに役立ちます。
SELECT
bucket,
size,
key,
count(key) AS key_count
FROM athena_s3_30_days
GROUP BY 1,2,3
ORDER BY key_count DESCユースケース 3: 既存のテーブルの再分割
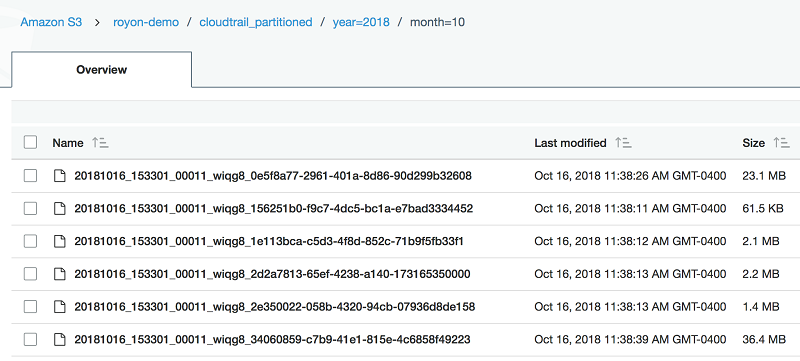
CTAS が価値がある場所を強調したい 3 番目のユースケースは、既存の最適化されていないデータセットを Apache ORC に変換し、それを分割して繰り返しクエリを最適化することです。 最近 100 日間の CloudTrail イベントを取得し、日付別に分割します。CREATE TABLE cloudtrail_partitioned
WITH (
partitioned_by = ARRAY['year', 'month'],
format = 'orc',
external_location = 's3://royon-demo/cloudtrail_partitioned'
)
AS
SELECT
*,
year(date(from_iso8601_timestamp(eventtime))) as year,
month(date(from_iso8601_timestamp(eventtime))) as month
FROM cloudtrail_logs結果として得られる S3 宛先バケットは、次の例のようになります。
Athena CTAS でサポートされている追加の最適化はバケット化です。 パーティショニングは、特定の列に基づいて同様のタイプのデータをグループ化するために使用されます。 バケット化は、通常、パーティション内のデータを多数の等しいグループまたはファイルに結合するために使用されます。 したがって、カーディナリティが低い列にはパーティショニングが最適であり、カーディナリティが高い列にはバケット化が最適です。 詳細については、Bucketing vs Partitioningを参照してください。
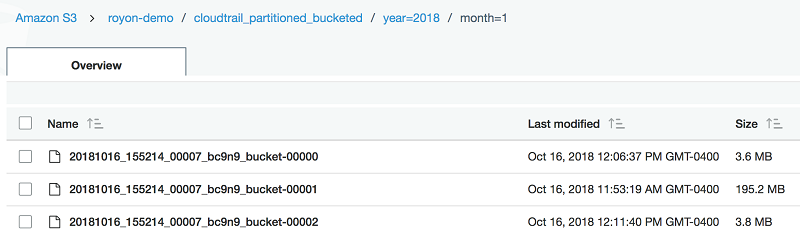
それでは、以前の CTAS の例で、バケット化を追加しましょう。
CREATE TABLE cloudtrail_partitioned_bucketed
WITH (
partitioned_by = ARRAY['year', 'month'],
bucketed_by = ARRAY['eventname'],
bucket_count = 3,
format = 'orc',
external_location = 's3://royon-demo/cloudtrail_partitioned'
)
AS
SELECT
*,
year(date(from_iso8601_timestamp(eventtime))) as year,
month(date(from_iso8601_timestamp(eventtime))) as month
FROM cloudtrail_logsそして、S3 では次のように表示されます。
以下に、パーティショニングされたテーブルと、パーティショニングおよびバケット化されたテーブルの両方のクエリの例を示します。 速度は似ていますが、バケット化のクエリはより少ないデータしかスキャンしていないことが分かります。
パーティショニングされたテーブル:
パーティショニングおよびバケット化されたテーブル:
結論
この記事では、Amazon Athena に CREATE TABLE AS SELECT (CTAS) を導入しました。CTAS を使用すると、SELECT クエリの結果から新しいテーブルを作成できます。この新しいテーブルは、Parquet、ORC、Avro、JSON、および TEXTFILE 形式で保存できます。さらに、新しいテーブルをパーティショニングおよびバケット化して、パフォーマンスを向上させることができます。CTAS が、どのようにして次の 3 つの一般的なユースケースに役立つかを見てきました。- 大きなデータセットを、より小さく、より効率的なデータセットに縮小する。
- 列と行のサブセットを選択して、データの消費者が本当に必要とするものだけを提供する。
- 現在最適化されていないデータセットのパーティショニングおよびバケット化によって、パフォーマンスを向上させ、コストを削減する。
その他の参考資料
この記事が参考になった場合は、「How Realtor.com Monitors Amazon Athena Usage with AWS CloudTrail and Amazon QuickSight」もぜひご覧ください。今回のブログ投稿者について
Roy Hasson は、AWS Analytics のグローバルビジネス開発マネージャーです。彼は世界中の顧客と協力して、データ処理、分析、ビジネスインテリジェンスのニーズを満たすソリューションを設計しています。Roy は、マンチェスターユナイテッドの大ファンであり、家族とともにチームを応援しています。
コメント
コメントを投稿