Equinox フィットネスクラブで、Amazon Redshift を使用して顧客のジャーニーループを閉じる
Equinox フィットネスクラブで、Amazon Redshift を使用して顧客のジャーニーループを閉じる:
クリックストリーム分析ツールはデータをうまく処理し、一部のツールは印象的な BI インターフェイスも備えています。ただし、クリックストリームデータを単独で分析するには多くの制限があります。たとえば、顧客はウェブサイトにある商品やサービスに興味があります。そして、顧客はそれらを購入するために物理的な店舗へ行きます。クリックストリームアナリストは「製品を見た後に何が起こったか?」と質問し、コマースアナリストは「購入する前に何が起こったか?」と質問します。
クリックストリームデータが他のデータソースを強化できることは驚くことではありません。購入データとともに使用すると、放棄されたカートの決定やマーケティング支出の最適化に役立ちます。同様に、オフラインおよびオンラインの行動や、顧客がアカウントを登録する前の行動さえも分析できます。ただし、クリックストリームのデータフィードの利点が明らかになったら、すぐに新しいリクエストに対応する必要があります。
このブログ記事では、Equinox フィットネスクラブで、クリックストリームデータで遅延バインディングのビュー戦略を使用するために、どのようにしてデータを Amazon Redshift から Amazon S3 へ移行したかを説明します。Apache Spark、Apache Parquet、データレイク、ハイブパーティショニング、外部テーブルなどの楽しいものを期待してください。すべてこの記事で広く取り上げます!
初めて自社のツールから Amazon Redshift データウェアハウスへクリックストリームデータを移行し始めたときは、スピードが第一の関心事でした。私たちの最初のユースケースは、Salesforce データと Adobe Analytics データを結びつけることで、リードプロセスをよりよく理解することでした。Adobe Analytics は、どのようなチャネルやキャンペーンからユーザーが来たのか、訪問中に閲覧したページ、サイトでリードフォームを提出したかなどを教えてくれます。Salesforce は、リードが認定されたかどうか、アドバイザーに会ったかどうか、最終的にメンバーになったかどうかを教えてくれます。これらの 2 つのデータセットを結び付けることで、マーケティングをよりよく理解し、最適化するのに役立ちました。
手始めとして、Salesforce と Adobe Analytics のデータを Amazon Redshift に集中させるための手順は知っていました。ただし、Redshift で結合しても、お互いに話すための共通の識別子が必要でした。最初のステップでは、ユーザーがウェブサイトでリードフォームを提出したときに、Salesforce と Adobe Analytics の両方に同じ GUID を生成して送信しました。

次に、Salesforce のデータを Redshift に渡す必要がありました。幸いなことに、そうしたフィードはすでに存在していたので、この新しい GUID 属性をフィードに追加し、Redshift でその属性を記述することができました。
同様に、Adobe Analytics から Amazon Redshift へのデータフィードを生成する必要がありました。Adobe Analytics は、データの送信先オプションとして Amazon S3 を提供しているので、データを S3 に渡してから、Redshift に送信するジョブを作成しました。このジョブには、毎日の Adobe Analytics フィードの取得 – 数百の列と数十万の行を含むデータファイル、データのヘッダーのようなルックアップファイルのコレクション、送信されたファイルを記述するマニフェストファイルが付属しています – そして、すべてを未処理の状態で Amazon S3 に渡します。そこから、Amazon EMR を Apache Spark と共に使用してデータフィードファイルを単一の CSV ファイルに処理し、それを S3 に保存して、データを Amazon Redshift に送信する COPY コマンドを実行できるようにしました。
このジョブは数週間実行され、データをより頻繁に使用し始めるまでうまくいきました。ジョブが有効である間に、新しい列によるデータのバックデート (スキーマの進化) が発生し始めました。データの性質上、柔軟性が必要であると判断したのはそのときです。
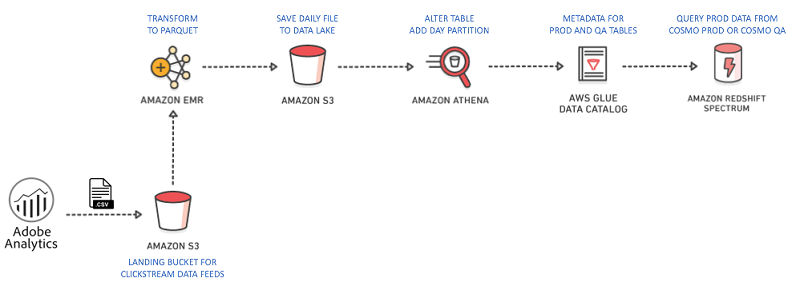
私たちは、データのスキーマとデータ自体を組み合わせた自己記述型データを利用したいと考えました。データを自己記述データに変換することで、幅広いクリックストリームデータセットを管理し、スキーマの進化に関連する課題を防ぐことができます。必要なすべての列をデータレイクファイルに抽出し、クエリで重要な列のみを使用することで処理を高速化することができます。この柔軟性を実現するために、カラムナストレージ技術のおかげで、自己記述型でありながら高速である Apache Parquet ファイル形式を使用しました。Amazon EMR で Apache Spark を使用して、CSV から Parquet に変換し、次のコードに示すように、スキャンのパフォーマンスのためにデータを分割しました。
AWS Glue データカタログを使用することで、Amazon Redshift や、Amazon Athena および Apache Spark などの他のクエリツールでクリックストリームデータを照会できるようになりました。これは、Parquet ファイルをリレーショナルスキーマにマッピングすることで実現します。AWS Glue は、ほんの数秒で追加データのクエリを可能にします。これは、スキーマの変更がリアルタイムで発生する可能性があるためです。つまり、列を削除して追加したり、列のインデックスを並べ替えたり、列のタイプを一度に変更したりすることができます。その後、スキーマを保存した直後にデータを照会することができます。さらに、Parquet 形式は、データの形状が変更されたとき、または特定の列が廃止され、データセットから削除されたときの障害を防止します。
次のクエリを使用して、Adobe Analytics ウェブサイトデータ用の最初の AWS Glue テーブルを作成しました。このクエリを、SQL Workbench の Amazon Redshift で実行しました。
このクエリを実行した後、AWS Glue インターフェイスを介してリクエストがあったときに、スキーマにさらに列を追加しました。また、パーティショニングを使用して、クエリをより迅速で安価にしました。
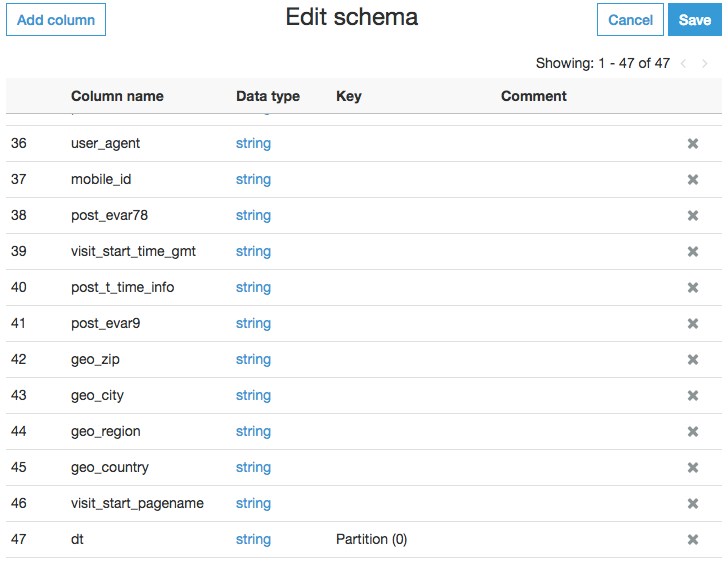
この時点で、データベースに新しいスキーマフォルダが作成されました。そのフォルダは照会できる外部テーブルを含んでいましたが、それをさらに進めたいと考えました。次のように、データにいくつかの変換を追加する必要がありました。
これで、構造化された Salesforce データと、半構造化された動的な Adobe Analytics データを組み合わせて、Amazon Redshift からクエリを実行できるようになりました。こうした変更によって、当社のデータは非常に柔軟性が高く、ストレージサイズに優しくなり、照会時には非常にパフォーマンスが向上しました。それ以来、データ品質チェック、マシンデータ、履歴データのアーカイブなどの多くのユースケースで Redshift Spectrum を使用し始め、データアナリストやサイエンティストがデータを簡単にブレンドしたりオンボードにできるようにしました。
 Ryan Kelly 氏は、Equinox のデータアーキテクトであり、データイニシアチブためのフレームワークの概要と実装を支援しています。また、彼はクリックストリームの追跡をリードし、デジタルイニシアチブについての洞察を持つ支援チームのサポートもしています。Ryan は、ビジネスインテリジェンス、分析、製品/サービスの強化のために、人々がデータにアクセスして取り込むことをより簡単にすることをとても重視しています。また、彼は Equinox での活動をどのように強化することができるかを見極めるための新しい技術の探索と検証が大好きです。
Ryan Kelly 氏は、Equinox のデータアーキテクトであり、データイニシアチブためのフレームワークの概要と実装を支援しています。また、彼はクリックストリームの追跡をリードし、デジタルイニシアチブについての洞察を持つ支援チームのサポートもしています。Ryan は、ビジネスインテリジェンス、分析、製品/サービスの強化のために、人々がデータにアクセスして取り込むことをより簡単にすることをとても重視しています。また、彼は Equinox での活動をどのように強化することができるかを見極めるための新しい技術の探索と検証が大好きです。
クリックストリーム分析ツールはデータをうまく処理し、一部のツールは印象的な BI インターフェイスも備えています。ただし、クリックストリームデータを単独で分析するには多くの制限があります。たとえば、顧客はウェブサイトにある商品やサービスに興味があります。そして、顧客はそれらを購入するために物理的な店舗へ行きます。クリックストリームアナリストは「製品を見た後に何が起こったか?」と質問し、コマースアナリストは「購入する前に何が起こったか?」と質問します。
クリックストリームデータが他のデータソースを強化できることは驚くことではありません。購入データとともに使用すると、放棄されたカートの決定やマーケティング支出の最適化に役立ちます。同様に、オフラインおよびオンラインの行動や、顧客がアカウントを登録する前の行動さえも分析できます。ただし、クリックストリームのデータフィードの利点が明らかになったら、すぐに新しいリクエストに対応する必要があります。
このブログ記事では、Equinox フィットネスクラブで、クリックストリームデータで遅延バインディングのビュー戦略を使用するために、どのようにしてデータを Amazon Redshift から Amazon S3 へ移行したかを説明します。Apache Spark、Apache Parquet、データレイク、ハイブパーティショニング、外部テーブルなどの楽しいものを期待してください。すべてこの記事で広く取り上げます!
初めて自社のツールから Amazon Redshift データウェアハウスへクリックストリームデータを移行し始めたときは、スピードが第一の関心事でした。私たちの最初のユースケースは、Salesforce データと Adobe Analytics データを結びつけることで、リードプロセスをよりよく理解することでした。Adobe Analytics は、どのようなチャネルやキャンペーンからユーザーが来たのか、訪問中に閲覧したページ、サイトでリードフォームを提出したかなどを教えてくれます。Salesforce は、リードが認定されたかどうか、アドバイザーに会ったかどうか、最終的にメンバーになったかどうかを教えてくれます。これらの 2 つのデータセットを結び付けることで、マーケティングをよりよく理解し、最適化するのに役立ちました。
手始めとして、Salesforce と Adobe Analytics のデータを Amazon Redshift に集中させるための手順は知っていました。ただし、Redshift で結合しても、お互いに話すための共通の識別子が必要でした。最初のステップでは、ユーザーがウェブサイトでリードフォームを提出したときに、Salesforce と Adobe Analytics の両方に同じ GUID を生成して送信しました。
次に、Salesforce のデータを Redshift に渡す必要がありました。幸いなことに、そうしたフィードはすでに存在していたので、この新しい GUID 属性をフィードに追加し、Redshift でその属性を記述することができました。
同様に、Adobe Analytics から Amazon Redshift へのデータフィードを生成する必要がありました。Adobe Analytics は、データの送信先オプションとして Amazon S3 を提供しているので、データを S3 に渡してから、Redshift に送信するジョブを作成しました。このジョブには、毎日の Adobe Analytics フィードの取得 – 数百の列と数十万の行を含むデータファイル、データのヘッダーのようなルックアップファイルのコレクション、送信されたファイルを記述するマニフェストファイルが付属しています – そして、すべてを未処理の状態で Amazon S3 に渡します。そこから、Amazon EMR を Apache Spark と共に使用してデータフィードファイルを単一の CSV ファイルに処理し、それを S3 に保存して、データを Amazon Redshift に送信する COPY コマンドを実行できるようにしました。
このジョブは数週間実行され、データをより頻繁に使用し始めるまでうまくいきました。ジョブが有効である間に、新しい列によるデータのバックデート (スキーマの進化) が発生し始めました。データの性質上、柔軟性が必要であると判断したのはそのときです。
データレイクによる救済
ジョブをリファクタリングすることに決めたとき、2 つのことがありました。まず、データレイクの戦略へと移行していました。次に、Redshift Spectrum が直前にリリースされていました。そのため、COPY コマンドを実行して Redshift に保存することなく、データレイク内のクリックストリームデータのフラットファイルを照会することができるようになっていました。また、クリックストリームデータを Redshift の内部に保存されている他のデータソースと効率的に結合することもできました。私たちは、データのスキーマとデータ自体を組み合わせた自己記述型データを利用したいと考えました。データを自己記述データに変換することで、幅広いクリックストリームデータセットを管理し、スキーマの進化に関連する課題を防ぐことができます。必要なすべての列をデータレイクファイルに抽出し、クエリで重要な列のみを使用することで処理を高速化することができます。この柔軟性を実現するために、カラムナストレージ技術のおかげで、自己記述型でありながら高速である Apache Parquet ファイル形式を使用しました。Amazon EMR で Apache Spark を使用して、CSV から Parquet に変換し、次のコードに示すように、スキャンのパフォーマンスのためにデータを分割しました。
from datetime import date, timedelta
from pyspark.sql.types import *
from pyspark.sql import SparkSession
import json
import argparse
# 使用方法
# spark-submit all_omniture_to_parquet.py 2017-10-31 s3a:// eqxdl-prod-l-omniture eqxios eqxdl-prod eqeqxiosprod omniture_eqxios
# python -m tasks.s2w_all_omniture_to_parquet 2017-10-31
parser = argparse.ArgumentParser()
parser.add_argument('year_month_day_arg', help='Run date (yyyy-mm-dd)', type=str, default='XXX')
parser.add_argument('s3_protocol', help='S3 protocol i.e. s3a://',type=str, default='XXX')
parser.add_argument('source_bucket', help='Omniture source data bucket',type=str, default='XXX')
parser.add_argument('source_path', help='Omniture source data path',type=str, default='XXX')
parser.add_argument('target_bucket', help='Omniture target data bucket',type=str, default='XXX')
parser.add_argument('report_suite', help='Omniture report suite ID',type=str, default='XXX')
parser.add_argument('application', help='App name for job',type=str, default='XXX')
args = parser.parse_args()
spark = SparkSession\
.builder\
.appName(args.application)\
.getOrCreate()
sc = spark.sparkContext
def manifest_toJSON(file, location):
text = sc.textFile(file).collect()
manifest = {'lookup_files': [], 'data_files': location, 'total_rows': 0}
for x in text:
if 'Lookup-File:' in x:
manifest['lookup_files'].append(location+x.split(': ')[1])
elif 'Data-File: 01' in x:
wildcard_path = x.replace('Data-File: 01','*')
manifest['data_files'] += wildcard_path
elif 'Record-Count:' in x:
manifest['total_rows'] += int(x.split(': ')[1])
return manifest
# マニフェストファイルからヘッダーファイルとデータファイルの
# ファイルパスを繋ぎ合わせてメタデータを作成する
# base_filepath = '/Users/rkelly/projects/sparkyTest/project_remodeling/ios_test_data/'
base_filepath = '{}{}/{}/'.format(args.s3_protocol, args.source_bucket, args.source_path)
manifest_filepath = base_filepath+'{}_{}.txt'.format(args.report_suite, args.year_month_day_arg)
metadata = manifest_toJSON(manifest_filepath, base_filepath)
# ファイルとそのデータのリストを作成する
# 特に column_headers.tsv データを探す
# \x00 で分割してガベージエンコーディングを削除し、ヘッダーの文字列を返す
lookup_files = sc.textFile(','.join(metadata['lookup_files'])).collect()
encoded_header = lookup_files[[idx for idx, s in enumerate(lookup_files) if 'column_headers.tsv' in s][0]].split('\x00')
header = encoded_header[[idx for idx, s in enumerate(encoded_header) if '\t' in s][0]]\
.replace('\n', '')\
.replace('(', '')\
.replace(')', '')\
.replace(' ', '-')
# タブ上で分割されたヘッダーファイルからリスト用のスキーマを作成する
# データ型の失敗を避けるために、すべてを文字列としてキャストする
schema = StructType([ StructField(field, StringType(), True) for field in header.split('\t')])
# RDD をバイパスし、データフレームとしてデータファイルを書き込む
# 次に、ヘッダーをそれぞれの値に結びつけるために parquet として保存する
df = spark.read.csv(metadata['data_files'], header=False, schema=schema, sep='\t', nullValue=None)
destination_filepath = '{}{}/{}/dt={}/'.format(args.s3_protocol, args.target_bucket, args.application, args.year_month_day_arg)
df.write.mode('overwrite').parquet(destination_filepath)
# 正常にスパークとこのファイルを終了する
sc.stop()
exit()AWS Glue データカタログを使用することで、Amazon Redshift や、Amazon Athena および Apache Spark などの他のクエリツールでクリックストリームデータを照会できるようになりました。これは、Parquet ファイルをリレーショナルスキーマにマッピングすることで実現します。AWS Glue は、ほんの数秒で追加データのクエリを可能にします。これは、スキーマの変更がリアルタイムで発生する可能性があるためです。つまり、列を削除して追加したり、列のインデックスを並べ替えたり、列のタイプを一度に変更したりすることができます。その後、スキーマを保存した直後にデータを照会することができます。さらに、Parquet 形式は、データの形状が変更されたとき、または特定の列が廃止され、データセットから削除されたときの障害を防止します。
次のクエリを使用して、Adobe Analytics ウェブサイトデータ用の最初の AWS Glue テーブルを作成しました。このクエリを、SQL Workbench の Amazon Redshift で実行しました。
--最初にスキーマを作成する
create external schema omniture_prod
from data catalog
database 'omniture'
iam_role 'arn:aws:iam:::role
--次に、「テーブル」を作成する
CREATE EXTERNAL TABLE omniture_prod.eqx_web (
date_time VARCHAR,
va_closer_id VARCHAR,
va_closer_detail VARCHAR,
va_finder_detail VARCHAR,
va_finder_id VARCHAR,
ip VARCHAR,
domain VARCHAR,
post_evar1 VARCHAR
)
STORED AS PARQUET
LOCATION 's3://eqxdl-prod/omniture/eqx_web/'
table properties ('parquet.compress'='SNAPPY');
--データベース、スキーマ、テーブルを確認する
select * from pg_catalog.svv_external_databases;
select * from pg_catalog.svv_external_schemas;
select * from pg_catalog.svv_external_tables;このクエリを実行した後、AWS Glue インターフェイスを介してリクエストがあったときに、スキーマにさらに列を追加しました。また、パーティショニングを使用して、クエリをより迅速で安価にしました。
この時点で、データベースに新しいスキーマフォルダが作成されました。そのフォルダは照会できる外部テーブルを含んでいましたが、それをさらに進めたいと考えました。次のように、データにいくつかの変換を追加する必要がありました。
- ID から文字列への名前の変更
- 値の連結
- ウェブサイトをテストするために AWS から送信したボットのトラフィックを除外した、文字列の操作
- よりユーザーフレンドリーになるような列名の変更
create view edw_t.f_omniture_web as
select
REPLACE(dt, '-', '') as hive_date_key,
va_closer_id,
va_closer_detail as last_touch_campaign,
CASE
WHEN (va_closer_id) = '1' THEN 'Paid Search'
WHEN (va_closer_id) = '2' THEN 'Natural Search'
WHEN (va_closer_id) = '3' THEN 'Display'
WHEN (va_closer_id) = '4' THEN 'Email Acq'
WHEN (va_closer_id) = '5' THEN 'Direct'
WHEN (va_closer_id) = '6' THEN 'Session Refresh'
WHEN (va_closer_id) = '7' THEN 'Social Media'
WHEN (va_closer_id) = '8' THEN 'Referring Domains'
WHEN (va_closer_id) = '9' THEN 'Email Memb'
WHEN (va_closer_id) = '10' THEN 'Social Placement'
WHEN (va_closer_id) = '11' THEN 'Other Placement'
WHEN (va_closer_id) = '12' THEN 'Partnership'
WHEN (va_closer_id) = '13' THEN 'Other Eqx Sites'
WHEN (va_closer_id) = '14' THEN 'Influencers'
ELSE NULL
END AS last_touch_channel,
va_finder_detail as first_touch_campaign,
va_finder_id as va_finder_id,
CASE
WHEN (va_finder_id) = '1' THEN 'Paid Search'
WHEN (va_finder_id) = '2' THEN 'Natural Search'
WHEN (va_finder_id) = '3' THEN 'Display'
WHEN (va_finder_id) = '4' THEN 'Email Acq'
WHEN (va_finder_id) = '5' THEN 'Direct'
WHEN (va_finder_id) = '6' THEN 'Session Refresh'
WHEN (va_finder_id) = '7' THEN 'Social Media'
WHEN (va_finder_id) = '8' THEN 'Referring Domains'
WHEN (va_finder_id) = '9' THEN 'Email Memb'
WHEN (va_finder_id) = '10' THEN 'Social Placement'
WHEN (va_finder_id) = '11' THEN 'Other Placement'
WHEN (va_finder_id) = '12' THEN 'Partnership'
WHEN (va_finder_id) = '13' THEN 'Other Eqx Sites'
WHEN (va_closer_id) = '14' THEN 'Influencers'
ELSE NULL
END AS first_touch_channel,
ip as ip_address,
domain as domain,
post_evar1 AS internal_compaign,
post_evar10 as site_subsection_nm,
post_evar11 as IOS_app_view_txt,
post_evar12 AS site_section_nm,
post_evar15 AS transaction_id,
post_evar23 as join_barcode_id,
post_evar3 AS page_nm,
post_evar32 as host_nm,
post_evar41 as class_category_id,
post_evar42 as class_id,
post_evar43 as class_instance_id,
post_evar60 AS referral_source_txt,
post_evar69 as adwords_gclid,
post_evar7 as usersec_tracking_id,
post_evar8 as facility_id,
post_event_list as post_event_list,
post_visid_low||post_visid_high as unique_adobe_id,
post_visid_type as post_visid_type,
post_page_event as hit_type,
visit_num as visit_number,
visit_start_time_gmt,
post_evar25 as login_status,
exclude_hit as exclude_hit,
hit_source as hit_source,
geo_zip,
geo_city,
geo_region,
geo_country,
post_evar64 as api_error_msg,
post_evar70 as page_load_time,
post_evar78 as join_transaction_id,
post_evar9 as page_url,
visit_start_pagename as entry_pg,
post_tnt as abtest_campaign,
post_tnt_action as abtest_experience,
user_agent as user_agent,
mobile_id as mobile_id,
cast(date_time as timestamp) as date_time,
CONVERT_TIMEZONE(
'America/New_York', -- オリジンのタイムゾーン
(cast(
case
when post_t_time_info like '%undefined%' then '0'
when post_t_time_info is null then '0'
when post_t_time_info = '' then '0'
when cast(split_part(post_t_time_info,' ',4) as int) < 0
then left(split_part(post_t_time_info,' ',4),4)
else left(split_part(post_t_time_info,' ',4),3) end as int
)/60),
cast(date_time as timestamp)
) as date_time_local,
post_t_time_info as local_timezone
from omniture_prod.eqx_web
where exclude_hit = '0'
and hit_source not in ('5','7','8','9')
and domain <> 'amazonaws.com'
and domain <> 'amazon.com'
WITH NO SCHEMA BINDING;これで、構造化された Salesforce データと、半構造化された動的な Adobe Analytics データを組み合わせて、Amazon Redshift からクエリを実行できるようになりました。こうした変更によって、当社のデータは非常に柔軟性が高く、ストレージサイズに優しくなり、照会時には非常にパフォーマンスが向上しました。それ以来、データ品質チェック、マシンデータ、履歴データのアーカイブなどの多くのユースケースで Redshift Spectrum を使用し始め、データアナリストやサイエンティストがデータを簡単にブレンドしたりオンボードにできるようにしました。
with web_leads as (
select transaction_id,last_touch_channel
from edw_t.f_omniture_web
where hive_date_key = '20170301'
and post_event_list like '%201%'
and transaction_id != '807f0cdc-80cf-42d3-8d75-e55e277a8718'
),
opp_lifecycle as (
SELECT lifecycle,weblead_transactionid
FROM edw_t.f_opportunity
where weblead_transactionid is not null
and created_date_key between '20170220'and '20170310'
)
select
web_leads.transaction_id,
coalesce(opp_lifecycle.lifecycle, 'N/A') as Lifecycle
from web_leads
left join opp_lifecycle on web_leads.transaction_id = opp_lifecycle.weblead_transactionid結論
Amazon S3 データレイクと Amazon Redshift を組み合わせることで、クリックストリームデータ用の効率的で柔軟な分析プラットフォームを設定することができました。これにより、クリックストリームデータを常にデータウェアハウスにロードする必要性がなくなり、プラットフォームは入力データのスキーマ変更にも対応できるようになりました。Redshift Spectrum を始めるための Redshift ドキュメントをお読みになり、下記の AWS Chicago Summit 2018 でのプレゼンテーションもご覧ください。その他の参考資料
この投稿が参考になった場合は、「From Data Lake to Data Warehouse: Enhancing Customer 360 with Amazon Redshift Spectrum」および「Narrativ is helping producers monetize their digital content with Amazon Redshift」もぜひご覧ください。今回のブログ投稿者について
Ryan Kelly 氏は、Equinox のデータアーキテクトであり、データイニシアチブためのフレームワークの概要と実装を支援しています。また、彼はクリックストリームの追跡をリードし、デジタルイニシアチブについての洞察を持つ支援チームのサポートもしています。Ryan は、ビジネスインテリジェンス、分析、製品/サービスの強化のために、人々がデータにアクセスして取り込むことをより簡単にすることをとても重視しています。また、彼は Equinox での活動をどのように強化することができるかを見極めるための新しい技術の探索と検証が大好きです。
コメント
コメントを投稿