新発表 – Amazon Kinesis Data Analytics for Java
新発表 – Amazon Kinesis Data Analytics for Java:
お客様は、リアルタイムなストリーミングデータを収集・処理・分析するために、Amazon Kinesisを活用しています。これによって、みなさまのビジネスやインフラストラクチャ、顧客から得られる情報に対して、迅速に反応することができます。例えば、Epic Gamesの人気オンラインゲーム『フォートナイト』では、1秒間に150万を超えるゲームイベントを取り込んでいます。
Amazon Kinesis Data Analyticsを活用すれば、標準SQLでリアルタイムなデータ処理を行うことができます。SQLは、新しいフレームワークや言語を学ぶ必要なしに、大規模なストリーミングデータに対して迅速にクエリをかける簡易な手段を提供します。一方で多くのお客様は、汎用的なプログラミング言語を使用して、より複雑なデータ処理を実装することも求めています。
この機能を利用するためには、あらゆる規模でデータの整理・変換・集計・分析を行う共通的なデータ処理機能ための組込み演算子を含むオープンソースのライブラリを使用して、アプリケーションを実装します。これらのライブラリはどちらもオープンソースであり、どこでも実行することが出来ます。
まず、2つのKinesis Data Streamsのストリームを作成します。
こちらがWord Countを実装したJavaアプリケーションのソースコードです。Kinesis Data Streamsからのデータの読み出しと書き出しのために、Apache FlinkプロジェクトによるKinesis Connectorを使用しています。
JavaアプリケーションはMavenを使用して実装し、アプリケーションをデプロイしたいリージョンにあるAmazon Simple Storage Service (S3) バケットに作成したJARファイルをアップロードします。Kinesis Data Analyticsのコンソールで、新規アプリケーションを作成してランタイムとして”Flink”を選択します。
そして、自分のS3バケット上にあるコード(JARファイル)をアプリケーションに指定します。このコンソールでは、アプリケーションがコードの読み取り権限を持つようにIAMロールを更新しています。
オプションとして、キー・バリュー型の設定パラメータ(Properties)をアプリケーションに追加できます。これらの設定パラメータはアプリケーションの中で読み込むことが出来るので、デプロイのタイミングでカスタマイズ設定を加えることができます。
モニタリングの設定では、デフォルトのメトリクスを残しています。Amazon CloudWatchへのログ出力を、Errorレベルのみ有効化しています。
コンソール上で作成されたIAMロールに、Kinesis Data Analyticsアプリケーションが入力ストリームと出力ストリームに読み書きするための権限を追加するのを忘れないようにして下さい。今回の場合は、TextInputStreamとWordCountOutputStreamに対してです。
ここまでくれば、”Run”ボタンからアプリケーションを起動できます。アプリケーションが起動されたら、準備していたスクリプトを使用してテキスト(今回はAmazon Kinesisプラットフォームの説明文を使用することにします)を入力ストリームに送信します。
出力ストリームを読み取るために、Pythonで書かれたLambda関数を使用します。ここでは、Kinesis Record Aggregation & Deaggregation Modules for AWS Lambdaを使用して、Amazon Kinesis Producer Library (KPL) によって集約されたレコードを自動的に”集約解除”します。
期待していた通り、CloudWatch Logsのコンソールに単語とその出現回数が出力され、5秒おきにLambda関数によって更新されます。
Javaアプリケーションでは、アプリケーションごとにAmazon Kinesis Processing Unit (KPU) が一つだけ追加で課金されます。このKPUはアプリケーションのオーケストレーションに使用されます。Javaアプリケーションでは、起動しているアプリケーションのストレージと耐久性を持たせるためのバックアップに対しても料金が発生します。アプリケーションのストレージは、Amazon Kinesis Data Analyticsがステートフルな処理を行うために使用され、GB-月あたりで課金されます。耐久性を持たせるためのバックアップはオプションであり、アプリケーションのポイントインタイムリカバリに使用され、GB-月あたりで課金されます。
例えば、米国東部(バージニア北部)リージョンでは、1KPUが1時間あたり$0.11の価格で、起動しているアプリケーションのストレージ(GB-月あたり$0.10)と、耐久性を持たせるためのバックアップ(GB-月あたり$0.023)にも料金が発生します。
私は、Amazon Kinesis Data AnalyticsがJavaをサポートすることで可能になるストリーム処理の表面をなぞったにすぎませんが、これは新しいユースケースを可能にするパワフルなツールだと思っています。Amazon Kinesis Data Analytics for Javaを使って皆さんが構築したいことを、是非教えてください!
翻訳はソリューションアーキテクトの山﨑が担当しました。原文はこちら。
お客様は、リアルタイムなストリーミングデータを収集・処理・分析するために、Amazon Kinesisを活用しています。これによって、みなさまのビジネスやインフラストラクチャ、顧客から得られる情報に対して、迅速に反応することができます。例えば、Epic Gamesの人気オンラインゲーム『フォートナイト』では、1秒間に150万を超えるゲームイベントを取り込んでいます。
Amazon Kinesis Data Analyticsを活用すれば、標準SQLでリアルタイムなデータ処理を行うことができます。SQLは、新しいフレームワークや言語を学ぶ必要なしに、大規模なストリーミングデータに対して迅速にクエリをかける簡易な手段を提供します。一方で多くのお客様は、汎用的なプログラミング言語を使用して、より複雑なデータ処理を実装することも求めています。
Amazon Kinesis Data AnalyticsでJavaを活用
2018年11月27日、私たちはAmazon Kinesis Data AnalyticsでJavaをサポートすることを発表します。これによって、開発者はJavaで書かれた独自のコードを使用して、強力なリアルタイム処理アプリケーションを実装することが出来ます。アプリケーションでは、ストリーミングデータを連続的に変換してデータレイクに取り込んだり、リアルタイムにゲームのリーダーボードを更新したり、IoTデバイスから取得したデータストリームに機械学習モデルを適用して推論を実行したりと、様々な処理を行えます。この機能を利用するためには、あらゆる規模でデータの整理・変換・集計・分析を行う共通的なデータ処理機能ための組込み演算子を含むオープンソースのライブラリを使用して、アプリケーションを実装します。これらのライブラリはどちらもオープンソースであり、どこでも実行することが出来ます。
- Apache Flink:データストリームを処理するためのオープンソースのフレームワークおよび処理エンジン
- AWS SDK for Java:様々なAWSサービスのJava APIを提供するSDK
- ストリーミングデータの送信元(ソース):Amazon Kinesis Data Streams
- ストリーミングデータの送信先(ディスティネーション):Amazon S3、Amazon DynamoDB、Amazon Kinesis Data Streams、Amazon Kinesis Data Firehose
Kinesis Data Streams Javaアプリケーションの実装
ここでデータ処理の例として、”お決まりの” Word Count(単語の集計)を実装したシンプルなJavaアプリケーションを準備してみました。いくつかの文章のパラグラフを入力として送信すると、5秒毎にそれぞれの単語が使用された回数が出力されます。まず、2つのKinesis Data Streamsのストリームを作成します。
- TextInputStream:入力レコードを送信するストリーム
- WordCountOutputStream:Javaアプリケーションの出力を読み取るためのストリーム

こちらがWord Countを実装したJavaアプリケーションのソースコードです。Kinesis Data Streamsからのデータの読み出しと書き出しのために、Apache FlinkプロジェクトによるKinesis Connectorを使用しています。
public class StreamingJob {
private static final String region = "us-east-1";
private static final String inputStreamName = "TextInputStream";
private static final String outputStreamName = "WordCountOutputStream";
private static DataStream<String> createSourceFromStaticConfig(
StreamExecutionEnvironment env) {
Properties inputProperties = new Properties();
inputProperties.setProperty(ConsumerConfigConstants.AWS_REGION
inputProperties.setProperty(ConsumerConfigConstants.STREAM_INITIAL_"LATEST");
return env.addSource(new FlinkKinesisConsumer<>(inputStreamName
new SimpleStringSchema(), inputProperties));
}
private static FlinkKinesisProducer<String> createSinkFromStaticConfig
Properties outputProperties = new Properties();
outputProperties.setProperty(ConsumerConfigConstants.AWS_REGION
FlinkKinesisProducer<String> sink = new FlinkKinesisProducer
SimpleStringSchema(), outputProperties);
sink.setDefaultStream(outputStreamName);
sink.setDefaultPartition("0");
return sink;
}
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> input = createSourceFromStaticConfig(env)
input.flatMap(new Tokenizer())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
.map(new MapFunction<Tuple2<String, Integer>, String>()
@Override
public String map(Tuple2<String, Integer> value) throws
return value.f0 + "," + value.f1.toString();
}
})
.addSink(createSinkFromStaticConfig());
env.execute("Word Count");
}
public static final class Tokenizer
implements FlatMapFunction<String, Tuple2<String, Integer>>
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer
String[] tokens = value.toLowerCase().split("\\W+");
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}
- 入力ストリームから得られるString型のDataStreamオブジェクトから処理を始めます。
- FlatMapの中でTokenizerを使用して文章を”単語”に分割します。それぞれの単語は”1″を値として持ちます。
- KeyBy演算子を適用して、ストリームを”単語”ごとの論理的なパーティションに分割します。
- 5秒毎のタンブリングウィンドウを適用します。
- ウィンドウに含まれる値を集計し、それぞれの単語が持つ”1″の値の合計値を計算して単語数をカウントします。
- レコード毎に単語の集計した合計値をカンマ区切り(CSV)形式のStringにしてシンプルなMapを作成し、出力ストリームに送信します。
JavaアプリケーションはMavenを使用して実装し、アプリケーションをデプロイしたいリージョンにあるAmazon Simple Storage Service (S3) バケットに作成したJARファイルをアップロードします。Kinesis Data Analyticsのコンソールで、新規アプリケーションを作成してランタイムとして”Flink”を選択します。
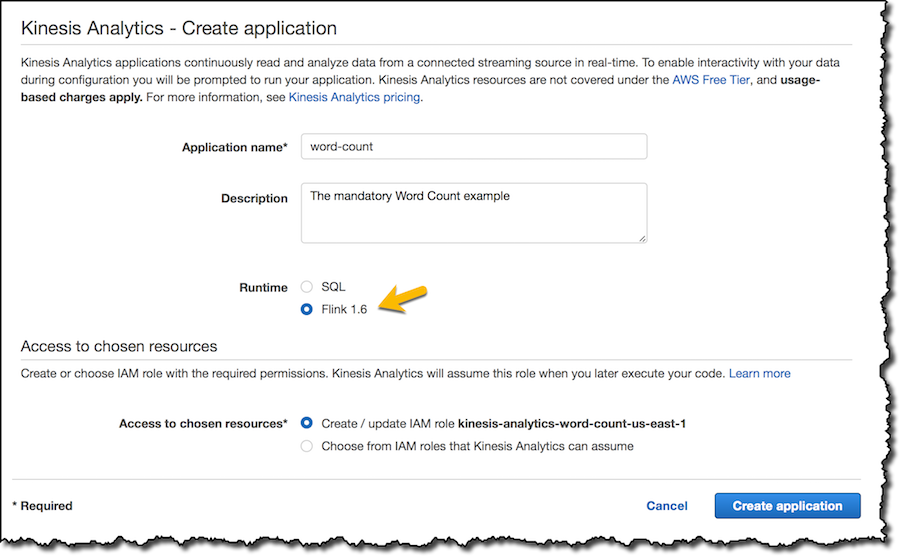
そして、自分のS3バケット上にあるコード(JARファイル)をアプリケーションに指定します。このコンソールでは、アプリケーションがコードの読み取り権限を持つようにIAMロールを更新しています。

オプションとして、キー・バリュー型の設定パラメータ(Properties)をアプリケーションに追加できます。これらの設定パラメータはアプリケーションの中で読み込むことが出来るので、デプロイのタイミングでカスタマイズ設定を加えることができます。
モニタリングの設定では、デフォルトのメトリクスを残しています。Amazon CloudWatchへのログ出力を、Errorレベルのみ有効化しています。

コンソール上で作成されたIAMロールに、Kinesis Data Analyticsアプリケーションが入力ストリームと出力ストリームに読み書きするための権限を追加するのを忘れないようにして下さい。今回の場合は、TextInputStreamとWordCountOutputStreamに対してです。
ここまでくれば、”Run”ボタンからアプリケーションを起動できます。アプリケーションが起動されたら、準備していたスクリプトを使用してテキスト(今回はAmazon Kinesisプラットフォームの説明文を使用することにします)を入力ストリームに送信します。
$ python put_records.py TextInputStream Amazon Kinesis makes it easy to collect, process, and analyze real-time, streaming data...アプリケーションの構成は、コンソール上のApplication Graphと呼ばれる演算子と中間結果からなるデータフローを視覚的に表現する場所に表示されます(より複雑なアプリケーションや、複数のストリームを扱うようなアプリケーションでは、さらに興味深いグラフになるでしょう)。

出力ストリームを読み取るために、Pythonで書かれたLambda関数を使用します。ここでは、Kinesis Record Aggregation & Deaggregation Modules for AWS Lambdaを使用して、Amazon Kinesis Producer Library (KPL) によって集約されたレコードを自動的に”集約解除”します。
期待していた通り、CloudWatch Logsのコンソールに単語とその出現回数が出力され、5秒おきにLambda関数によって更新されます。

価格と可用性
Amazon Kinesis Data Analytics for Javaでは、使用した分だけの料金がかかります。料金体系は、Amazon Kinesis Data Analytics for SQLと似ていますが、少しだけ違いがあります。Javaアプリケーションでは、アプリケーションごとにAmazon Kinesis Processing Unit (KPU) が一つだけ追加で課金されます。このKPUはアプリケーションのオーケストレーションに使用されます。Javaアプリケーションでは、起動しているアプリケーションのストレージと耐久性を持たせるためのバックアップに対しても料金が発生します。アプリケーションのストレージは、Amazon Kinesis Data Analyticsがステートフルな処理を行うために使用され、GB-月あたりで課金されます。耐久性を持たせるためのバックアップはオプションであり、アプリケーションのポイントインタイムリカバリに使用され、GB-月あたりで課金されます。
例えば、米国東部(バージニア北部)リージョンでは、1KPUが1時間あたり$0.11の価格で、起動しているアプリケーションのストレージ(GB-月あたり$0.10)と、耐久性を持たせるためのバックアップ(GB-月あたり$0.023)にも料金が発生します。
今すぐ利用可能
Amazon Kinesis Data Analytics for Javaは、米国東部(バージニア北部)、米国西部(オレゴン)、EU(アイルランド)の各リージョンで、本日2018年11月27日からご利用頂けます。私は、Amazon Kinesis Data AnalyticsがJavaをサポートすることで可能になるストリーム処理の表面をなぞったにすぎませんが、これは新しいユースケースを可能にするパワフルなツールだと思っています。Amazon Kinesis Data Analytics for Javaを使って皆さんが構築したいことを、是非教えてください!
翻訳はソリューションアーキテクトの山﨑が担当しました。原文はこちら。
コメント
コメントを投稿