Amazon SageMaker に機械学習実験を加速する新機能が登場
Amazon SageMaker に機械学習実験を加速する新機能が登場:
データサイエンティストおよび開発者は、Amazon SageMaker Search で機械学習 (ML) モデルトレーニングの実験を、素早く簡単に整理、追跡、評価できるようになりました。当社が導入する新しい Amazon SageMaker Search 機能を使用すると、Amazon SageMaker の数百から数千に及ぶモデルトレーニングジョブの中から、最も関連性の高いモデルトレーニング実行を発見して評価することができます。これにより、モデルの開発と実験のフェーズをスピードアップし、データサイエンティストと開発者の生産性を高め、機械学習ベースのソリューションを市場に投入するまでの全体的な時間を短縮できます。AWS マネジメントコンソールと AWS SDK API for Amazon SageMaker の両方で、新しい検索機能のベータ版を利用できます。新機能のベータ版は、現在 Amazon SageMaker の利用が可能な 13 の AWS リージョンで、追加料金なしで提供されています。
機械学習モデルを開発するには、継続的な実験と観察が必要です。たとえば、新しい学習アルゴリズムを試したり、モデルのハイパーパラメータをチューニングしたりする場合、そのような増分変更がモデルのパフォーマンスと精度に及ぼす影響を観察する必要があります。この反復型最適化の訓練は、数百のモデルトレーニング実験とモデルバージョンでデータ爆発を招くことがよくあります。それにより、「成功した」モデルの収束と発見が遅くなる可能性があります。また、情報の爆発が起こると、本番環境にデプロイされたモデルバージョンの先行モデルを遡って追跡するのにも手間がかかります。このようなモデル系統の追跡の難しさは、モデルの監査やコンプライアンスの検証、モデルのライブ予測パフォーマンスの低下原因のデバッグ、新しいモデルの再トレーニング実験の設定などを行う妨げとなります。
Amazon SageMaker Search を使用すれば、ビジネスユースケースに対応するうえで最も関連性の高いモデルトレーニング実行を迅速に特定できます。採用された学習アルゴリズム、ハイパーパラメータ設定、使用されているトレーニングデータセット、さらにはモデルトレーニングジョブに自分で追加しておいたタグなど、あらゆる定義属性を検索できます。タグを検索すると、特定のビジネスプロジェクト、研究ラボ、データサイエンスチームに関連付けられたモデルトレーニング実行をすばやく見つけられます。これは、モデルトレーニング実行をわかりやすく分類してカタログ化するのに役立ちます。関連するモデルトレーニング実行を 1 か所で集中的に追跡および整理できるだけでなく、トレーニングの損失や検証の精度などのパフォーマンス指標に基づいて、トレーニング実行をすばやく比較してランク付けできます。これにより、「成功した」モデルを選んで本番環境にデプロイするためのスコアボードを作成することができます。さらに、Amazon SageMaker Search では、ライブ環境にデプロイされたモデルの系統を迅速に追跡して、モデルのトレーニングや検証に使用されたデータセットまで遡ることができます。AWS マネジメントコンソールで 1 回クリックするか、または 1 行の簡単な API 呼び出しを実行するだけで、特定のトレーニング実行にアクセスして、最初のモデル作成時に組み込まれたすべての要素まで参照できるようになったのです。
次に、Amazon SageMaker Search を使用してモデルトレーニング実験を効率的に管理する方法を、手順に沿って紹介します。この新機能はベータ版で提供されているため、本番環境では注意してご使用ください。
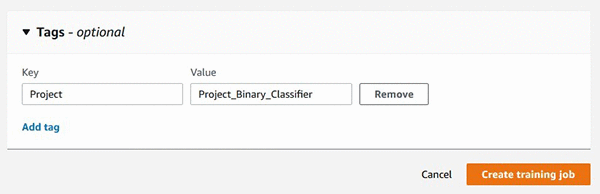
SageMaker estimator を使用したトレーニングジョブの作成中にも、Amazon SageMaker Python SDK API を使用してタグを追加することができます。
実行する 3 つのモデルトレーニングには、同じ一意のラベルを付けているため、同じプロジェクト内でグループにまとめることができます。次のステップでは、Amazon SageMaker Search を使用して、“Project” タグでラベル付けされたすべてのモデルトレーニングの実行をクエリして整理する方法を説明します。
タグを検索して、ステップ 2 で実行した 3 つのモデルトレーニングの実行をすべて検索できます。

テーブル内のすべてのラベル付きのトレーニングの実行がリストされます。
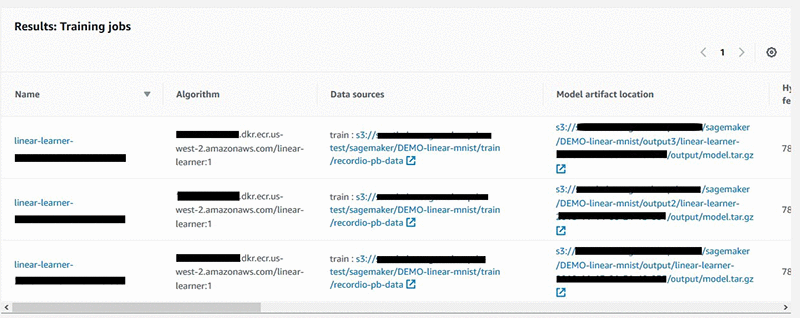
AWS SDK API for Amazon SageMaker Search を使用して検索することもできます。
ここではタグによる検索を紹介しましたが、新しい Amazon SageMaker Search では、使用する学習アルゴリズム、トレーニングデータセットの URI、ハイパーパラメータおよびモデルトレーニングメトリクスの数値範囲など、モデルトレーニング実行のメタデータの検索をサポートしています。
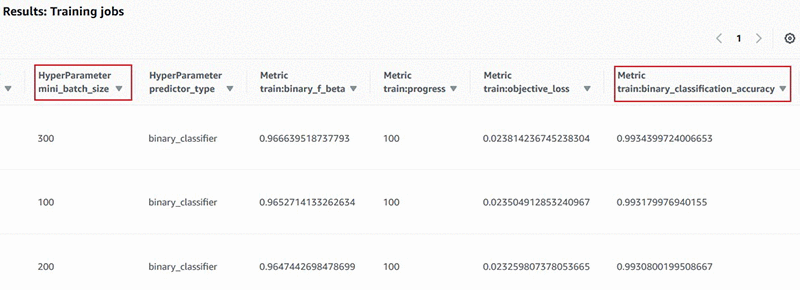
Amazon SageMaker Jupyter ノートブックで、リーダーボードにインラインで書き込むこともできます。以下にコードの例を示します。
ステップ 3 で示したように、並べ替え条件はすでに “

300 の batch_size と最高の分類精度 0.99344 で成功モデルが判明したので、このモデルを稼働中のエンドポイントにデプロイできるようになりました。サンプルノートブックには、Amazon SageMaker エンドポイントをデプロイする方法についてステップバイステップの説明が記載されています。
 Sumit Thakur は AWS Machine Learning プラットフォームのシニアプロダクトマネージャーで、クラウドで容易に機械学習を開始できる製品を開発することに情熱を燃やしています。彼は、Amazon SageMaker と AWS Deep Learning AMI のプロダクトマネージャーです。余暇には、自然との触れ合いや SF テレビドラマの視聴を楽しんでいます。
Sumit Thakur は AWS Machine Learning プラットフォームのシニアプロダクトマネージャーで、クラウドで容易に機械学習を開始できる製品を開発することに情熱を燃やしています。彼は、Amazon SageMaker と AWS Deep Learning AMI のプロダクトマネージャーです。余暇には、自然との触れ合いや SF テレビドラマの視聴を楽しんでいます。
データサイエンティストおよび開発者は、Amazon SageMaker Search で機械学習 (ML) モデルトレーニングの実験を、素早く簡単に整理、追跡、評価できるようになりました。当社が導入する新しい Amazon SageMaker Search 機能を使用すると、Amazon SageMaker の数百から数千に及ぶモデルトレーニングジョブの中から、最も関連性の高いモデルトレーニング実行を発見して評価することができます。これにより、モデルの開発と実験のフェーズをスピードアップし、データサイエンティストと開発者の生産性を高め、機械学習ベースのソリューションを市場に投入するまでの全体的な時間を短縮できます。AWS マネジメントコンソールと AWS SDK API for Amazon SageMaker の両方で、新しい検索機能のベータ版を利用できます。新機能のベータ版は、現在 Amazon SageMaker の利用が可能な 13 の AWS リージョンで、追加料金なしで提供されています。
機械学習モデルを開発するには、継続的な実験と観察が必要です。たとえば、新しい学習アルゴリズムを試したり、モデルのハイパーパラメータをチューニングしたりする場合、そのような増分変更がモデルのパフォーマンスと精度に及ぼす影響を観察する必要があります。この反復型最適化の訓練は、数百のモデルトレーニング実験とモデルバージョンでデータ爆発を招くことがよくあります。それにより、「成功した」モデルの収束と発見が遅くなる可能性があります。また、情報の爆発が起こると、本番環境にデプロイされたモデルバージョンの先行モデルを遡って追跡するのにも手間がかかります。このようなモデル系統の追跡の難しさは、モデルの監査やコンプライアンスの検証、モデルのライブ予測パフォーマンスの低下原因のデバッグ、新しいモデルの再トレーニング実験の設定などを行う妨げとなります。
Amazon SageMaker Search を使用すれば、ビジネスユースケースに対応するうえで最も関連性の高いモデルトレーニング実行を迅速に特定できます。採用された学習アルゴリズム、ハイパーパラメータ設定、使用されているトレーニングデータセット、さらにはモデルトレーニングジョブに自分で追加しておいたタグなど、あらゆる定義属性を検索できます。タグを検索すると、特定のビジネスプロジェクト、研究ラボ、データサイエンスチームに関連付けられたモデルトレーニング実行をすばやく見つけられます。これは、モデルトレーニング実行をわかりやすく分類してカタログ化するのに役立ちます。関連するモデルトレーニング実行を 1 か所で集中的に追跡および整理できるだけでなく、トレーニングの損失や検証の精度などのパフォーマンス指標に基づいて、トレーニング実行をすばやく比較してランク付けできます。これにより、「成功した」モデルを選んで本番環境にデプロイするためのスコアボードを作成することができます。さらに、Amazon SageMaker Search では、ライブ環境にデプロイされたモデルの系統を迅速に追跡して、モデルのトレーニングや検証に使用されたデータセットまで遡ることができます。AWS マネジメントコンソールで 1 回クリックするか、または 1 行の簡単な API 呼び出しを実行するだけで、特定のトレーニング実行にアクセスして、最初のモデル作成時に組み込まれたすべての要素まで参照できるようになったのです。
次に、Amazon SageMaker Search を使用してモデルトレーニング実験を効率的に管理する方法を、手順に沿って紹介します。この新機能はベータ版で提供されているため、本番環境では注意してご使用ください。
Amazon SageMaker Search によるモデルトレーニング実験の整理、追跡、評価
以下の例では、Amazon SageMaker 線形学習アルゴリズムを使用して、MNIST データセットで単純な 2 項分類モデルをトレーニングします。このモデルは、与えられた画像が数字の 0 か、それ以外かを予測します。mini_batch_size などの線形学習アルゴリズムのハイパーパラメーターをチューニングして実験すると同時に、モデルによる予測の精度を測定する binary_classification_accuracy メトリクスを最適化していきます。この例のサンプルノートブックはこちらからご覧いただけます。ステップ 1: すべてのモデルトレーニングの実行にタグ付けする一意のラベルを選択して、実験の追跡をセットアップする
モデルトレーニングジョブの作成中にタグを追加できます。AWS マネジメントコンソールを開いて Amazon SageMaker コンソールに移動します。SageMaker estimator を使用したトレーニングジョブの作成中にも、Amazon SageMaker Python SDK API を使用してタグを追加することができます。
linear_1 = sagemaker.estimator.Estimator(
linear_learner_container, role,
train_instance_count=1, train_instance_type = 'ml.c4.xlarge',
output_path=<you model output S3 path URI>,
tags=[{"Key":"Project", "Value":"Project_Binary_Classifier"}],
sagemaker_session=sess)ステップ 2: 毎回新しいハイパーパラメータを設定して、複数のモデルトレーニングを実行する
デモンストレーションの目的で、100、200、300 の 3 つの異なるバッチサイズを試してみます。以下にコードの例を示します。linear_1.set_hyperparameters(feature_dim=784,predictor_type='binary_classifier', mini_batch_size=100)
linear_1.fit({'train': <your training dataset S3 URI>})ステップ 3: さらなる評価のために、関連する実験を集中化した 1 か所で検索して整理する
検索は Amazon SageMaker コンソールのベータ版で利用できます。タグを検索して、ステップ 2 で実行した 3 つのモデルトレーニングの実行をすべて検索できます。
テーブル内のすべてのラベル付きのトレーニングの実行がリストされます。
AWS SDK API for Amazon SageMaker Search を使用して検索することもできます。
………………
search_params={
"MaxResults": 10,
"Resource": "TrainingJob",
"SearchExpression": {
"Filters": [{
"Name": "Tags.Project",
"Operator": "Equals",
"Value": "Project_Binary_Classifier"
}]},
"SortBy": "Metrics.train:binary_classification_accuracy",
"SortOrder": "Descending"
}
smclient = boto3.client(service_name='sagemaker')
results = smclient.search(**search_params)
ステップ4: 選択した目標パフォーマンスメトリクスでソートして、成功モデルを特定する
ステップ 3 で Amazon SageMaker Search によって返されたモデルトレーニングジョブは、リーダーボードのようにテーブルに表示されます。すべてのハイパーパラメータとモデルトレーニングのメトリクスが並べ替え可能な列に表示されます。列ヘッダーを選択して、リーダーボードを選択した目標パフォーマンスメトリクスでランク付けします。ここではbinary_classification_accuracy を選択します。Amazon SageMaker Jupyter ノートブックで、リーダーボードにインラインで書き込むこともできます。以下にコードの例を示します。
import pandas
headers=["Training Job Name", "Training Job Status", "Batch Size", "Binary Classification Accuracy"]
rows=[]
for result in results['Results']:
trainingJob = result['TrainingJob']
metrics = trainingJob['FinalMetricDataList']
rows.append([trainingJob['TrainingJobName'],
trainingJob['TrainingJobStatus'],
trainingJob['HyperParameters']['mini_batch_size'],
metrics[[x['MetricName'] for x in
metrics].index('train:binary_classification_accuracy')]['Value']
])
df = pandas.DataFrame(data=rows,columns=headers)
from IPython.display import display, HTML
display(HTML(df.to_html()))SortBy“: “Metrics.train:binary_classification_accuracy” および “SortOrder“: “Descending” として search() API コールで指定されているため、ここで指定されたメトリクスを基準にして並べ替えられた結果が返ってきます。前述のサンプルコードは JSON レスポンスを解析し、下図のようにリーダーボード形式で結果を提示します。300 の batch_size と最高の分類精度 0.99344 で成功モデルが判明したので、このモデルを稼働中のエンドポイントにデプロイできるようになりました。サンプルノートブックには、Amazon SageMaker エンドポイントをデプロイする方法についてステップバイステップの説明が記載されています。
Amazon SageMaker でモデルの出自を遡る
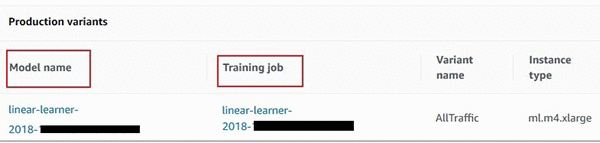
ここからの例では、予測エンドポイントを選択して、そのエンドポイントでデプロイ済みのモデルの作成に使用されたモデルトレーニングに、すばやく遡る方法を見ていきます。Amazon SageMaker コンソールでシングルクリックを使用する
Amazon SageMaker の左側にあるナビゲーションペインで [エンドポイント] を選択し、デプロイしたすべてのエンドポイントの一覧から、関連するエンドポイントを選択します。そのエンドポイントでデプロイしたすべてのモデルのバージョンを一覧できる [Endpoint Configuration Settings] までスクロールします。最初にそのモデルを作成したモデルトレーニングジョブへの追加のハイパーリンクを確認できます。AWS SDK for Amazon SageMaker Search を使用する
モデルの出自をすばやく遡るには、簡単な 1 行の API コールをいくつか使用する方法もあります。#first get the endpoint config for the relevant endpoint
endpoint_config = smclient.describe_endpoint_config(EndpointConfigName=endpointName)
#now get the model name for the model deployed at the endpoint.
model_name = endpoint_config['ProductionVariants'][0]['ModelName']
#now look up the S3 URI of the model artifacts
model = smclient.describe_model(ModelName=model_name)
modelURI = model['PrimaryContainer']['ModelDataUrl']
#search for the training job that created the model artifacts at above S3 URI location
search_params={
"MaxResults": 1,
"Resource": "TrainingJob",
"SearchExpression": {
"Filters": [
{
"Name": "ModelArtifacts.S3ModelArtifacts",
"Operator": "Equals",
"Value": modelURI
}]}
}
results = smclient.search(**search_params)さらに多くの例と開発者用サポートを利用して開始する
新機能 Amazon SageMaker Search を使用した、機械学習実験プロセスの効果的な管理法およびモデルの出自の確認法の例を見てきました。ぜひサンプルノートブックをお試しください。その他の例は開発者ガイドを参照してください。ご質問は Discussion Forums にお寄せください。よい実験を!著者について
Sumit Thakur は AWS Machine Learning プラットフォームのシニアプロダクトマネージャーで、クラウドで容易に機械学習を開始できる製品を開発することに情熱を燃やしています。彼は、Amazon SageMaker と AWS Deep Learning AMI のプロダクトマネージャーです。余暇には、自然との触れ合いや SF テレビドラマの視聴を楽しんでいます。
コメント
コメントを投稿