AWS Schema Conversion Tool で仮想パーティション分割を使用する
AWS Schema Conversion Tool で仮想パーティション分割を使用する:
AWS Schema Conversion Tool (AWS SCT) は、データベースエンジンタイプ間の移行を支援する汎用ツールです。たとえば、AWS SCT を使用して Oracle スキーマを Amazon Aurora PostgreSQL に移行できます。AWS SCT は AWS ウェブサイトで無料でダウンロードできます。AWS SCT は、ソースデータベースとターゲットデータベースにアクセスできる Windows、Fedora、macOS や Ubuntu サーバーにインストールできます。
データウェアハウスの移行では、AWS SCT はデータベーススキーマを Amazon Redshift に移行するだけでなく、データを移行することもできます。AWS SCT データエクストラクタにより、Oracle、Microsoft SQL Server、Teradata、IBM Netezza、Greenplum や Vertica データウェアハウスからデータを抽出し、それを Amazon S3 または Amazon Redshift にアップロードします。AWS SCT データエクストラクタは無料でダウンロードでき、AWS SCT 同様どのプラットフォームにもインストールできます。
この記事では、仮想パーティション分割を使用して AWS SCT でデータウェアハウスの移行を最適化する方法について検討します。仮想パーティション分割は、並列処理を使用することで大きなテーブルからのデータ抽出作業を高速化します。それは、データウェアハウスの移行で推奨されるベストプラクティスです。
したがって、パフォーマンスの観点からは、大きなテーブルを並列に移行できる小さなチャンクに分割する方がいいでしょう。AWS SCT には、これを達成するための 2 つのメカニズムがあります。(たとえば、Oracle データベースで範囲パーティション分割を使用して) テーブルが物理的にソース内でパーティション化されている場合、AWS SCT は UNION ALL VIEW システムオプションを使用してテーブルをパーティション単位で自動的に移行します。
ソーステーブルがパーティション化されていない場合は、AWS SCT を使用して仮想パーティションを作成できます。仮想パーティションは、大きなソーステーブルの抽出を並列化することで、移行のタイムラインを短縮します。簡単に言えば、仮想パーティション分割は、大きなテーブルを移行するために分割して対処するアプローチです。パーティションは並行して移行することができ、データ抽出の失敗はテーブル全体ではなく単一のパーティションに限定されます。仮想パーティション分割を使用することは、AWS SCT エクストラクタを使用したデータウェアハウスを移行する際に推奨されるベストプラクティスです。
「舞台裏」で何が起こっているか、興味があるでしょうか。 AWS SCT は、物理パーティションまたは仮想パーティションに関係なく、各テーブルパーティションに対してサブタスクを作成します。次に、移行を実行する際は、AWS SCT はサブタスクを使用可能なデータ抽出プログラムに割り当てて実行します。本質的に、AWS SCT がどのサブタスクをどのエクストラクタで実行するかを調整することで、移行中、すべてのエクストラクタをできる限りビジー状態に保ちます。
多くのテクノロジーと同様に、機能を効果的に使用するためには、機能がどのように機能し、その固有のトレードオフを理解することが役立ちます。この記事の残りの部分では、仮想パーティション分割の仕組みを説明するためにいくつかの例を紹介します。次に、テーブルのパーティションキーを選択するために用いることができる方法について説明します。
その前に、仮想パーティション分割の概要とその機能の使用方法を簡単に見ていきましょう。
たとえば、次のスクリーンショットは、AWS SCT の CUSTOMER_ID 属性に適用されるリストパーティション分割を示しています。
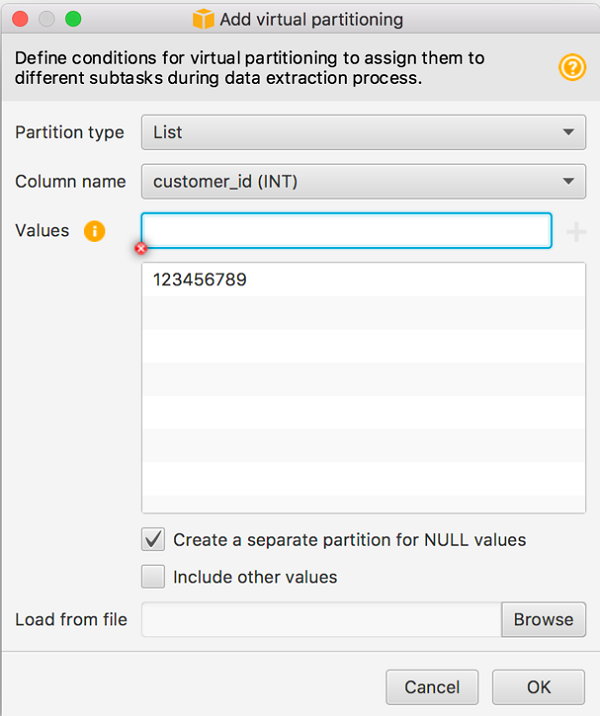
AWS SCT の仮想パーティションタブに切り替えて、生成されたパーティションを確認することができます。上部中央のペインでテーブル名を選択して、パーティションを表示します。

ここで留意すべきは、CUSTOMER_ID = 123456789のレコードに対してパーティションが作成されることです。[Create a separate partition for NULL values (NULL 値用に別のパーティションを作成する)] チェックボックスを選択したため、これらの行をキャプチャするために 2 番目のパーティションが作成されます。これらの条件のいずれとも合致しない行は、移行から除外されます。これは、リストパーティション分割の利点の 1 つです。データのあるサブセットのみをターゲットに移行したい場合に使えます。
それ以外の場合は、Include other values (その他の値を含める) チェックボックスを選択して、キャッチオールパーティションを作成できます。
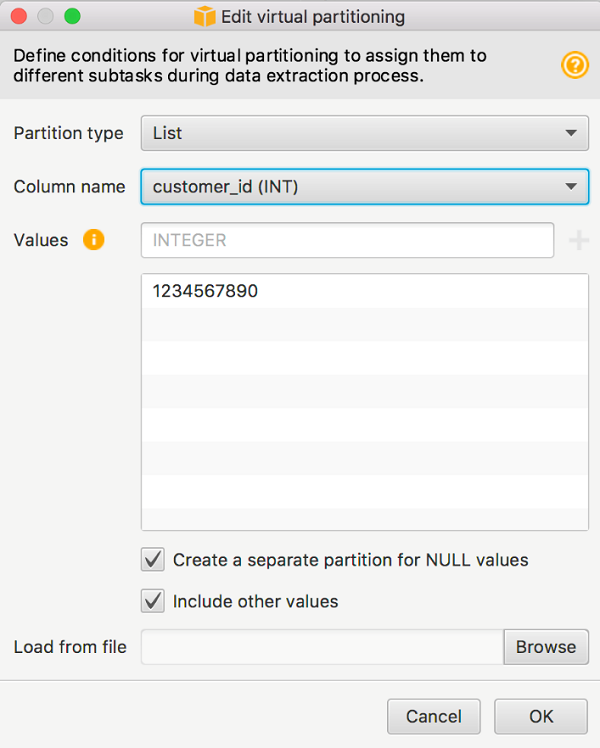
キャッチオールパーティションは NOT IN 条件を使用して作成します。AWS SCT の仮想パーティションタブに切り替えると、パーティションを表示できます。
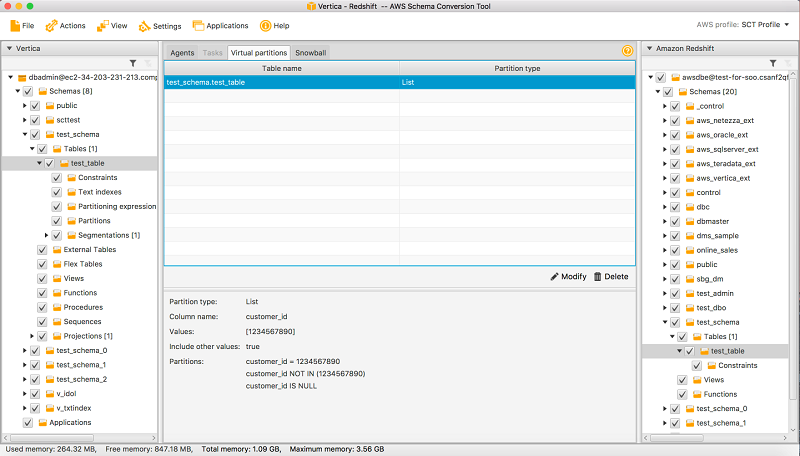
前述のように、テーブルを移行すると、3 つのサブタスクが作成されます (パーティションごとに 1 つ)。

[Load from file (ファイルからロード)] フィールドに示されているように、パーティション値がファイルからロードされたことがわかります。これは、特に数十または数百の値を持つような大きなリストの場合に、パーティション値を作成する便利な方法です。ファイルからのロードは、リストパーティションタイプと範囲パーティションタイプの両方で使用できます。前述のように、[Create a separate partition for NULL values] チェックボックスをオンにすることによって、パーティション属性で NULL 値を持つ行をキャプチャできます。
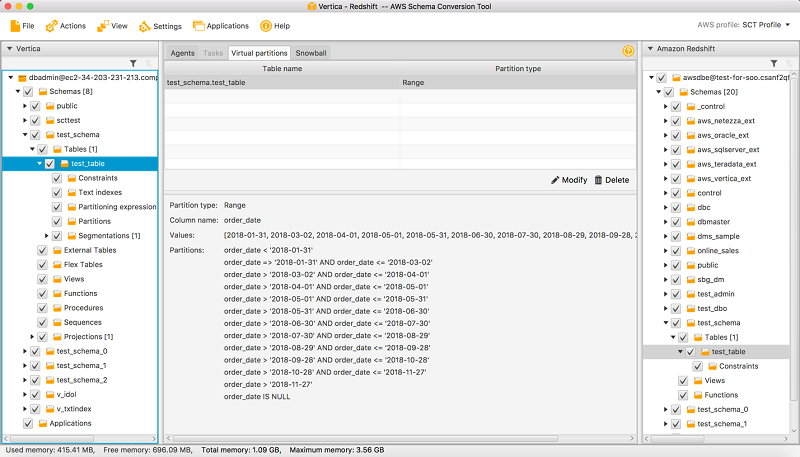
範囲パーティション分割の場合、AWS SCT はデフォルトで、指定されたパーティション値の「両端」にキャッチオールパーティションを作成します。範囲パーティション分割では、すべてのソースデータがターゲットに移行します。リストパーティション分割ではできたようにデータをフィルタリングすることはできません。
通常、日付フィールドが範囲パーティション分割に適しています。
たとえば、自動分割を使用して、次のように週単位のパーティションを作成できます。

上記のように、[仮想パーティション] タブで生成されたパーティションを確認できます。
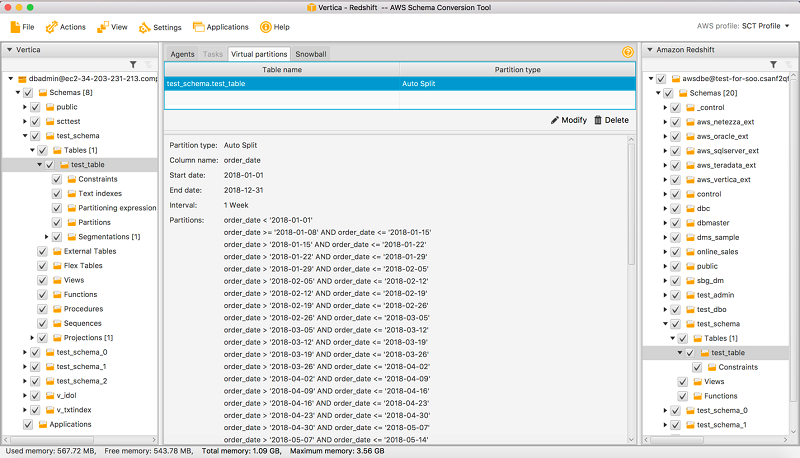
自動分割は、範囲パーティションの作成に伴う多くの作業を自動化します。自動分割と範囲パーティションの使用の間のトレードオフは、パーティション境界上でどれだけの制御が必要かの点にあります。自動分割は、常に等しいサイズ (均一) の範囲を作成します。範囲パーティション分割を使用して各範囲のサイズを変更できます。たとえば、特定のデータ配信に必要な範囲として、日単位、週単位、隔週単位、月単位などがあります。違いは他に、自動分割には常に NULL 値用のパーティションが含まれていることですが、範囲パーティション分割ではこのオプションを特に選択する必要があります。
仮想パーティション分割の日付/時刻属性を選択する際のデフォルトの選択は、自動パーティション分割です。個々のパーティション境界を指定する必要性を排除することで、範囲パーティション分割プロセスを簡略化します。ただし、パーティションサイズの粒度は一様なので、パーティション分割を意のままに行えなくなる部分もあります。たとえば、前述の order テーブルを参照してください。販売数量が季節により異なり、年の第 4 四半期にピークを迎えると、自動分割はパーティションの粒度に関係なくデータの歪みの一部を保持します。
ほとんどの移行では、範囲パーティション分割と自動パーティション分割が好ましいパーティション分割方法です。これは、大部分の大規模なテーブルはトランザクションテーブルである傾向があり、したがってパーティション化属性として使用できるタイムスタンプまたは日付スタンプがあるためです。または、使用できるシーケンスベースのキー値を持つ大きな次元のテーブルです。
この記事の残りの部分では、範囲パーティション分割に焦点を当てて具体的に見ていきます。自動パーティション分割は、一定サイズの範囲パーティションを作成するためのショートカットであるため、自動パーティション分割にも同じことが言えます。
他の関連するデータ分布を次の 2 つの図に示します。次の表は、顧客の注文数を示しています。
次の図は、歪んだ属性の分布を示しています。この図では、注文量は季節により変化し、Q1 で最も活動が低く、Q4 で活動がピークに達しています。
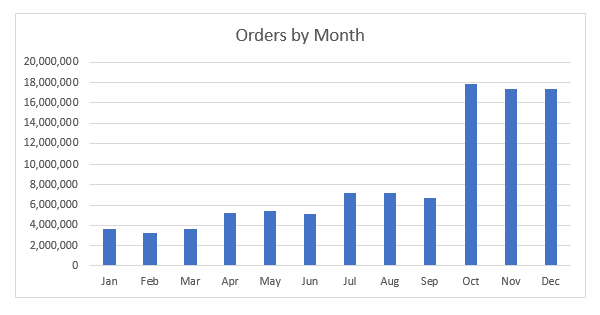
このような歪んだデータは、仮想パーティション分割の設定によっては移行パフォーマンスに悪影響を及ぼす可能性があります。たとえば、単純な月単位のパーティションが使用されている場合、その年の最後の 3 か月間が全体の移行パフォーマンスを支配します。次のセクションでは、データの歪みの影響を緩和するためのベストプラクティスについて説明します。
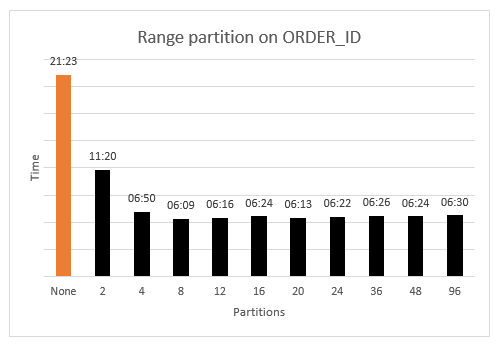
ベンチマーク「no-partitions」のタイミングはオレンジ色で表示されています (一番左側)。黒いバーは、パーティションの粒度を増やすタイミングを示しています。グラフに示されているように、パーティションなしの場合と比べてパーティション分割は有益です。2 つのパーティションでも、最悪の場合の性能はほぼ半減します (21:23 に対して 11:20)。
もう一つの注目点は、かなり低い数のパーティション (8~12) でほぼ最適なパフォーマンスが達成されていることです。この粒度を超えると、パフォーマンスは本質的に一定であり、AWS SCT 内でのタスク管理のため、高めのパーティションではわずかに増加します。
ORDER_ID データはデータドメイン (0~1 億の間の整数) に均一に分布しているため、各パーティションはほぼ同じサイズになることが保証されています。均一な分布を持つ属性は、範囲パーティション分割の優れた候補です。効率的なパーティション分割をかなり細かく行うことができます。この場合、データを過度に細かく分割する必要はありません。均一なデータに関しては、パフォーマンスと予備的なデータ分析とのバランスをとる「スイートスポット」を見つけるには、低/中の粒度のパーティションで実験を行うだけで十分です。
歪みなしのパーティション属性がある場合はそれを選択することでこれを回避できますが、そうでない場合もよくあります。歪んだデータ分布を使用する必要がある場合、目標はデータの歪みの影響を最小限に抑えることです。このセクションでは、仮想パーティション分割を使用してこれを達成する 2 つの方法を紹介します。
最初のテストでは、上記で ORDER_ID フィールドに対して行ったように、ORDER_DATE フィールドに均一なサイズのパーティションを生成しました。次の図は、ORDER_ID と ORDER_DATE の測定値を比較したものを示しています (均一なデータ分割と歪んだデータ分割の比較)。黒いバーは、前の図に示されているものと同じ一連の結果を示しています。明るい青色のバーは、ORDER_DATE パーティション分割の新しい測定値です。一定の測定値は、すべてのパーティションサイズが所定の粒度で同じであるという点で最良のケースを表すため、歪んだ測定値を均一な測定値と比較します。
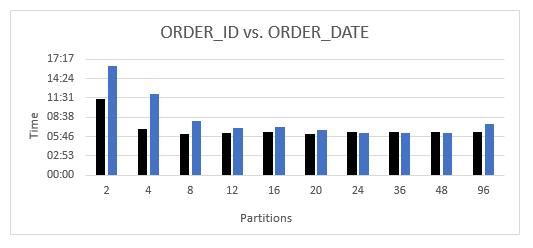
予想どおり、歪んだ属性を使用してパーティションを作成するのは、一般的に、均一な属性を使用してパーティションを作成する方法よりも劣った方法です。これは、低いパーティションの粒度 (2 つ、4 つ、または 8 つのパーティション) に特に当てはまります。ただし、パーティションが 24~48 パーティションの十分な粒度に達すると、データの歪みの影響はあまりはっきりとは表れません。パーティションの粒度は、データの歪みの影響がデータエクストラクタの処理オーバーヘッドによって隠されるほど十分に細かいものです。
明らかとなった結論は、均一に分布した属性を利用できる場合は、それをパーティション分割カラムとして使用することです。歪んだ属性に必要なより高い粒度と比べて、比較的低い粒度ではほぼ最適なパフォーマンスで均一なパーティション分割を行うことができます。均一な分布が得られない場合は、歪んだ属性で効果的なパーティション分割を見つけるために、もう少し分析が必要です。
別の方法は、歪んだデータ範囲を十分な粒度で分割して、データの歪みを緩和することです。この例では、このアプローチにより Q4 の時間枠により多くのパーティションを作成します。次の図で 2 つのアプローチを比較します。
上記同様、オレンジ色のバー (左端) は、パーティション分割を行わない移行のベンチマークタイミングを示しています。チャートの中央にある青色の 10 本のバーは、均一な範囲での単純な範囲パーティション分割を示しています。(これは、ORDER_ID と ORDER_DATE を比較した、前の図と同じ青色のバーデータです)。 最後に、3 つの緑色のバーは、最初の 9 か月間を単純に四半期分割したものを示し、次に第 4 四半期の隔週 (2 週間に 1 回)、週 1 回、週 2 回 (3 日または 4 日ごとに 1 回) のパーティション分割を示しています。
青色のバーは、パーティションの粒度が十分に高い場合、均一なサイズのパーティションによって歪んだデータに関わるパフォーマンスへの影響を克服できることを示しています。この「スイートスポット」(前の例では 24~48 パーティション) を見つけるために一連の実験を実行する必要があるでしょう。しかし、パーティション分割は均一であるため、パーティション境界を簡単にスクリプト化することができ、発見するプロセスが簡素化されます。
3 つの緑色のバーは、「労働集約型」パーティション分割のパフォーマンスを示しています。これにより、歪んだ Q4 データに対するパーティション分割の細かさが増加します。このパーティション分割は、十分な細かさに達したときの均一なパーティション分割とパフォーマンスの点で本質的に同等です。ただし、これらのパーティションを作成するには、実際のデータ分布を検討し、歪みの領域を特定し、それに応じてパーティションを調整する必要があるため、ドメインの知識が必要です。
では、2 つのうちどちらの戦略を採用した方が良いでしょうか? どちらを選択するかは、アプリケーションに関するドメイン知識の程度によります。データに精通し、潜在的なデータの歪みに関する知識を持っている場合は、2 番目のアプローチがより好ましく、非常に効果的です。また、データの分布に精通していない場合は、一連の均一なパーティション範囲を試すことで、最小限の労力で最適に近いパーティション分割に「照準を合わる」ことができます。どのような場合でも、パーティション分割を行わないよりは、いずれかの方法でパーティション分割を行った方が良いでしょう。
ビジネスルールやプラクティス、技術環境、利用できる人員とリソースが異なるため、1 つとして同じ移行はありません。この記事のガイドラインを使用して移行計画を立てましょう。仮想パーティション分割をどう使えば最適な移行が行えるかは、あなたのユースケース次第です。移行がうまくいきますように!
 Michael Soo はアマゾン ウェブ サービスの AWS DMS と AWS SCT チームのデータベースエンジニアです。
Michael Soo はアマゾン ウェブ サービスの AWS DMS と AWS SCT チームのデータベースエンジニアです。
AWS Schema Conversion Tool (AWS SCT) は、データベースエンジンタイプ間の移行を支援する汎用ツールです。たとえば、AWS SCT を使用して Oracle スキーマを Amazon Aurora PostgreSQL に移行できます。AWS SCT は AWS ウェブサイトで無料でダウンロードできます。AWS SCT は、ソースデータベースとターゲットデータベースにアクセスできる Windows、Fedora、macOS や Ubuntu サーバーにインストールできます。
データウェアハウスの移行では、AWS SCT はデータベーススキーマを Amazon Redshift に移行するだけでなく、データを移行することもできます。AWS SCT データエクストラクタにより、Oracle、Microsoft SQL Server、Teradata、IBM Netezza、Greenplum や Vertica データウェアハウスからデータを抽出し、それを Amazon S3 または Amazon Redshift にアップロードします。AWS SCT データエクストラクタは無料でダウンロードでき、AWS SCT 同様どのプラットフォームにもインストールできます。
この記事では、仮想パーティション分割を使用して AWS SCT でデータウェアハウスの移行を最適化する方法について検討します。仮想パーティション分割は、並列処理を使用することで大きなテーブルからのデータ抽出作業を高速化します。それは、データウェアハウスの移行で推奨されるベストプラクティスです。
AWS SCT のデータ移行戦略
お客様から、AWS SCT データ抽出ツールをどのように調整すればデータベースの移行を高速化できるのか、という質問をよく受けます。アーカイブ情報を含むことができるデータウェアハウス環境では、テーブルのサイズに大きな違いがある可能性があります (大きいものから小さいものまで。多くはその間のサイズ)。その際、複数の AWS SCT エクストラクタを設定することができます。各エクストラクタは、複数のテーブルを並列に抽出して読み込むことができます。ただし、ソースデータベース内の最大のテーブルは、全体の移行タイムラインを引き続き支配します。したがって、パフォーマンスの観点からは、大きなテーブルを並列に移行できる小さなチャンクに分割する方がいいでしょう。AWS SCT には、これを達成するための 2 つのメカニズムがあります。(たとえば、Oracle データベースで範囲パーティション分割を使用して) テーブルが物理的にソース内でパーティション化されている場合、AWS SCT は UNION ALL VIEW システムオプションを使用してテーブルをパーティション単位で自動的に移行します。
ソーステーブルがパーティション化されていない場合は、AWS SCT を使用して仮想パーティションを作成できます。仮想パーティションは、大きなソーステーブルの抽出を並列化することで、移行のタイムラインを短縮します。簡単に言えば、仮想パーティション分割は、大きなテーブルを移行するために分割して対処するアプローチです。パーティションは並行して移行することができ、データ抽出の失敗はテーブル全体ではなく単一のパーティションに限定されます。仮想パーティション分割を使用することは、AWS SCT エクストラクタを使用したデータウェアハウスを移行する際に推奨されるベストプラクティスです。
「舞台裏」で何が起こっているか、興味があるでしょうか。 AWS SCT は、物理パーティションまたは仮想パーティションに関係なく、各テーブルパーティションに対してサブタスクを作成します。次に、移行を実行する際は、AWS SCT はサブタスクを使用可能なデータ抽出プログラムに割り当てて実行します。本質的に、AWS SCT がどのサブタスクをどのエクストラクタで実行するかを調整することで、移行中、すべてのエクストラクタをできる限りビジー状態に保ちます。
多くのテクノロジーと同様に、機能を効果的に使用するためには、機能がどのように機能し、その固有のトレードオフを理解することが役立ちます。この記事の残りの部分では、仮想パーティション分割の仕組みを説明するためにいくつかの例を紹介します。次に、テーブルのパーティションキーを選択するために用いることができる方法について説明します。
その前に、仮想パーティション分割の概要とその機能の使用方法を簡単に見ていきましょう。
仮想パーティション分割の種類
AWS SCT には、リスト、範囲、自動分割の 3 種類の仮想パーティション分割があります。このセクションでは、各タイプのパーティション分割について説明します。ここでは例として、次の Vertica ソーステーブルを使用します。リストパーティション分割
リストパーティション分割は、指定した値のセットに基づいてパーティションを作成します。各値に対して 1 つのパーティションが作成されます。選択すると、AWS SCT は、リストされた値でカバーされていないすべての行に対してキャッチオールパーティションを作成することもできます。たとえば、次のスクリーンショットは、AWS SCT の CUSTOMER_ID 属性に適用されるリストパーティション分割を示しています。
AWS SCT の仮想パーティションタブに切り替えて、生成されたパーティションを確認することができます。上部中央のペインでテーブル名を選択して、パーティションを表示します。
ここで留意すべきは、CUSTOMER_ID = 123456789のレコードに対してパーティションが作成されることです。[Create a separate partition for NULL values (NULL 値用に別のパーティションを作成する)] チェックボックスを選択したため、これらの行をキャプチャするために 2 番目のパーティションが作成されます。これらの条件のいずれとも合致しない行は、移行から除外されます。これは、リストパーティション分割の利点の 1 つです。データのあるサブセットのみをターゲットに移行したい場合に使えます。
それ以外の場合は、Include other values (その他の値を含める) チェックボックスを選択して、キャッチオールパーティションを作成できます。
キャッチオールパーティションは NOT IN 条件を使用して作成します。AWS SCT の仮想パーティションタブに切り替えると、パーティションを表示できます。
前述のように、テーブルを移行すると、3 つのサブタスクが作成されます (パーティションごとに 1 つ)。
範囲パーティション分割
範囲パーティション分割は、値の範囲に対応するパーティションを作成します。値のリストを指定すると、AWS SCT はそれらの値をソートし、隣接する値に基づいてパーティションを作成します。たとえば、範囲パーティション分割を使用して、次のように ORDER_DATE にパーティションを作成できます。[Load from file (ファイルからロード)] フィールドに示されているように、パーティション値がファイルからロードされたことがわかります。これは、特に数十または数百の値を持つような大きなリストの場合に、パーティション値を作成する便利な方法です。ファイルからのロードは、リストパーティションタイプと範囲パーティションタイプの両方で使用できます。前述のように、[Create a separate partition for NULL values] チェックボックスをオンにすることによって、パーティション属性で NULL 値を持つ行をキャプチャできます。
範囲パーティション分割の場合、AWS SCT はデフォルトで、指定されたパーティション値の「両端」にキャッチオールパーティションを作成します。範囲パーティション分割では、すべてのソースデータがターゲットに移行します。リストパーティション分割ではできたようにデータをフィルタリングすることはできません。
通常、日付フィールドが範囲パーティション分割に適しています。
自動パーティション分割
自動パーティション分割は、範囲パーティションを自動的に生成する方法です。自動分割では、パーティション属性、開始位置と終了位置、値の範囲をどれくらい大きくすべきかを AWS SCT に伝えます。AWS SCT はパーティション値を自動的に計算します。たとえば、自動分割を使用して、次のように週単位のパーティションを作成できます。
上記のように、[仮想パーティション] タブで生成されたパーティションを確認できます。
自動分割は、範囲パーティションの作成に伴う多くの作業を自動化します。自動分割と範囲パーティションの使用の間のトレードオフは、パーティション境界上でどれだけの制御が必要かの点にあります。自動分割は、常に等しいサイズ (均一) の範囲を作成します。範囲パーティション分割を使用して各範囲のサイズを変更できます。たとえば、特定のデータ配信に必要な範囲として、日単位、週単位、隔週単位、月単位などがあります。違いは他に、自動分割には常に NULL 値用のパーティションが含まれていることですが、範囲パーティション分割ではこのオプションを特に選択する必要があります。
仮想パーティション分割の日付/時刻属性を選択する際のデフォルトの選択は、自動パーティション分割です。個々のパーティション境界を指定する必要性を排除することで、範囲パーティション分割プロセスを簡略化します。ただし、パーティションサイズの粒度は一様なので、パーティション分割を意のままに行えなくなる部分もあります。たとえば、前述の order テーブルを参照してください。販売数量が季節により異なり、年の第 4 四半期にピークを迎えると、自動分割はパーティションの粒度に関係なくデータの歪みの一部を保持します。
ほとんどの移行では、範囲パーティション分割と自動パーティション分割が好ましいパーティション分割方法です。これは、大部分の大規模なテーブルはトランザクションテーブルである傾向があり、したがってパーティション化属性として使用できるタイムスタンプまたは日付スタンプがあるためです。または、使用できるシーケンスベースのキー値を持つ大きな次元のテーブルです。
この記事の残りの部分では、範囲パーティション分割に焦点を当てて具体的に見ていきます。自動パーティション分割は、一定サイズの範囲パーティションを作成するためのショートカットであるため、自動パーティション分割にも同じことが言えます。
テスト環境
前述した test_table をサンプルテーブルとして使用します。このテーブルを単一ノード Vertica 9 データベースに作成し、1 億のレコードをロードしました。ORDER_ID フィールドが、[0~1 億] の範囲でシーケンス生成整数として設定されました。別の言い方をすれば、ORDER_ID フィールドには一定の値の範囲内で均一な分布があります。他の関連するデータ分布を次の 2 つの図に示します。次の表は、顧客の注文数を示しています。
| 顧客数 | 注文数 |
| 475973 | 0~100 |
| 428816 | 101~150 |
| 23645 | 151~200 |
| 21574 | 201~250 |
| 756 | 251~300 |
| 763 | 301~350 |
| 30 | 351~400 |
| 24 | 401~450 |
| 2 | 451~500 |
| 1 | 501~550 |
このような歪んだデータは、仮想パーティション分割の設定によっては移行パフォーマンスに悪影響を及ぼす可能性があります。たとえば、単純な月単位のパーティションが使用されている場合、その年の最後の 3 か月間が全体の移行パフォーマンスを支配します。次のセクションでは、データの歪みの影響を緩和するためのベストプラクティスについて説明します。
範囲パーティション分割の使用
仮想パーティション分割を実証するために、最初にパーティション分割なしでベンチマークタイミングを生成し、次に粒度をより細かくしたパーティション分割で一連の移行を実行してみました。パーティション値は、Python プログラムを使用して生成したもので、それを前述の Load from file 機能を使用して AWS SCT にロードしました。すべてのテストで、「抽出のみ」のタスクを作成しました。つまり、タスクは、Vertica からローカルストレージへのデータ抽出に加えて、ファイルのチャンク化と圧縮を含むファイル操作を実行しました。タスクは Amazon S3 へのアップロードや Amazon Redshift への COPY などのダウンストリーム操作は実行しませんでした。均一なデータ分布
最初に、均一に分布したデータに対して範囲パーティション分割がどのように実行されるかを見ていきます。これは、いくつかの点で「最良のケース」のシナリオです。結果を次の図に示します。ベンチマーク「no-partitions」のタイミングはオレンジ色で表示されています (一番左側)。黒いバーは、パーティションの粒度を増やすタイミングを示しています。グラフに示されているように、パーティションなしの場合と比べてパーティション分割は有益です。2 つのパーティションでも、最悪の場合の性能はほぼ半減します (21:23 に対して 11:20)。
もう一つの注目点は、かなり低い数のパーティション (8~12) でほぼ最適なパフォーマンスが達成されていることです。この粒度を超えると、パフォーマンスは本質的に一定であり、AWS SCT 内でのタスク管理のため、高めのパーティションではわずかに増加します。
ORDER_ID データはデータドメイン (0~1 億の間の整数) に均一に分布しているため、各パーティションはほぼ同じサイズになることが保証されています。均一な分布を持つ属性は、範囲パーティション分割の優れた候補です。効率的なパーティション分割をかなり細かく行うことができます。この場合、データを過度に細かく分割する必要はありません。均一なデータに関しては、パフォーマンスと予備的なデータ分析とのバランスをとる「スイートスポット」を見つけるには、低/中の粒度のパーティションで実験を行うだけで十分です。
歪んだデータ分布
先に述べたように、テーブルサイズに偏差 (歪み) があると、より大きなテーブルが全体の移行時間を支配します。同様に、歪んだデータ分布を持つ属性を使用してテーブルをパーティション分割すると、大きなパーティションがそのテーブルの全体的な移行時間を支配する可能性があります。歪みなしのパーティション属性がある場合はそれを選択することでこれを回避できますが、そうでない場合もよくあります。歪んだデータ分布を使用する必要がある場合、目標はデータの歪みの影響を最小限に抑えることです。このセクションでは、仮想パーティション分割を使用してこれを達成する 2 つの方法を紹介します。
最初のテストでは、上記で ORDER_ID フィールドに対して行ったように、ORDER_DATE フィールドに均一なサイズのパーティションを生成しました。次の図は、ORDER_ID と ORDER_DATE の測定値を比較したものを示しています (均一なデータ分割と歪んだデータ分割の比較)。黒いバーは、前の図に示されているものと同じ一連の結果を示しています。明るい青色のバーは、ORDER_DATE パーティション分割の新しい測定値です。一定の測定値は、すべてのパーティションサイズが所定の粒度で同じであるという点で最良のケースを表すため、歪んだ測定値を均一な測定値と比較します。
予想どおり、歪んだ属性を使用してパーティションを作成するのは、一般的に、均一な属性を使用してパーティションを作成する方法よりも劣った方法です。これは、低いパーティションの粒度 (2 つ、4 つ、または 8 つのパーティション) に特に当てはまります。ただし、パーティションが 24~48 パーティションの十分な粒度に達すると、データの歪みの影響はあまりはっきりとは表れません。パーティションの粒度は、データの歪みの影響がデータエクストラクタの処理オーバーヘッドによって隠されるほど十分に細かいものです。
明らかとなった結論は、均一に分布した属性を利用できる場合は、それをパーティション分割カラムとして使用することです。歪んだ属性に必要なより高い粒度と比べて、比較的低い粒度ではほぼ最適なパフォーマンスで均一なパーティション分割を行うことができます。均一な分布が得られない場合は、歪んだ属性で効果的なパーティション分割を見つけるために、もう少し分析が必要です。
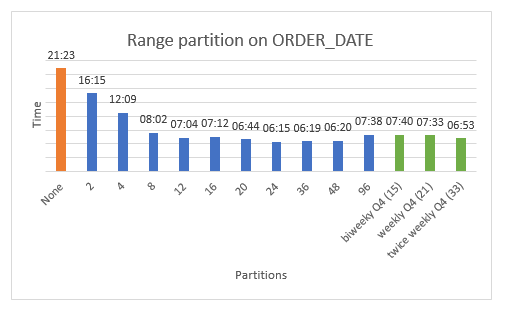
別の方法は、歪んだデータ範囲を十分な粒度で分割して、データの歪みを緩和することです。この例では、このアプローチにより Q4 の時間枠により多くのパーティションを作成します。次の図で 2 つのアプローチを比較します。
上記同様、オレンジ色のバー (左端) は、パーティション分割を行わない移行のベンチマークタイミングを示しています。チャートの中央にある青色の 10 本のバーは、均一な範囲での単純な範囲パーティション分割を示しています。(これは、ORDER_ID と ORDER_DATE を比較した、前の図と同じ青色のバーデータです)。 最後に、3 つの緑色のバーは、最初の 9 か月間を単純に四半期分割したものを示し、次に第 4 四半期の隔週 (2 週間に 1 回)、週 1 回、週 2 回 (3 日または 4 日ごとに 1 回) のパーティション分割を示しています。
青色のバーは、パーティションの粒度が十分に高い場合、均一なサイズのパーティションによって歪んだデータに関わるパフォーマンスへの影響を克服できることを示しています。この「スイートスポット」(前の例では 24~48 パーティション) を見つけるために一連の実験を実行する必要があるでしょう。しかし、パーティション分割は均一であるため、パーティション境界を簡単にスクリプト化することができ、発見するプロセスが簡素化されます。
3 つの緑色のバーは、「労働集約型」パーティション分割のパフォーマンスを示しています。これにより、歪んだ Q4 データに対するパーティション分割の細かさが増加します。このパーティション分割は、十分な細かさに達したときの均一なパーティション分割とパフォーマンスの点で本質的に同等です。ただし、これらのパーティションを作成するには、実際のデータ分布を検討し、歪みの領域を特定し、それに応じてパーティションを調整する必要があるため、ドメインの知識が必要です。
では、2 つのうちどちらの戦略を採用した方が良いでしょうか? どちらを選択するかは、アプリケーションに関するドメイン知識の程度によります。データに精通し、潜在的なデータの歪みに関する知識を持っている場合は、2 番目のアプローチがより好ましく、非常に効果的です。また、データの分布に精通していない場合は、一連の均一なパーティション範囲を試すことで、最小限の労力で最適に近いパーティション分割に「照準を合わる」ことができます。どのような場合でも、パーティション分割を行わないよりは、いずれかの方法でパーティション分割を行った方が良いでしょう。
方法論
得られた観測結果を要約すると、以下のベストプラクティスが導き出されます。- 重複しない値がいくつかある場合、またはソースデータをフィルタリングする必要がある場合は、リストパーティション分割を使用します。
- 範囲パーティション分割を使用する場合は、できる限り次の手順を実行します。
- 均一に分布した属性を選択する。
- 自動パーティション分割を使用する。
- 歪んだ分布の属性を使用しなければならない場合は、次の手順を実行します。
- パフォーマンスのために、小さいものから大きいものまで、さまざまなパーティション粒度をテストします。非常に細かい粒度で最適なパフォーマンスに近いものが見つかるかもしれません。
- それ以外の場合は、ドメインの知識を活かして、歪んだデータに粒度のより細かいパーティションを作成します。
- いずれにしても、過度に細かく分割したい気持ちは抑えましょう。それを行っても、必要な分析を行うのに使った時間を相殺するだけのパフォーマンスの向上は期待できない可能性があるためです。
結論
データウェアハウスを AWS Cloud に移行する際に直面するタスクの多くを自動化するために、AWS SCT データエクストラクタが開発されました。このブログ記事では、データウェアハウスの移行のための AWS SCT のベストプラクティスである仮想パーティション分割の使用方法について説明しました。パーティション化されていない大規模なソーステーブルの移行を高速化するためには、仮想パーティションを使用するのが良いでしょう。 この記事では、AWS SCT でサポートされている仮想パーティション分割の種類、それらを使用するタイミング、最も一般的なユースケースでパフォーマンスにどのような影響があるかについて見てきました。ビジネスルールやプラクティス、技術環境、利用できる人員とリソースが異なるため、1 つとして同じ移行はありません。この記事のガイドラインを使用して移行計画を立てましょう。仮想パーティション分割をどう使えば最適な移行が行えるかは、あなたのユースケース次第です。移行がうまくいきますように!
著者について
Michael Soo はアマゾン ウェブ サービスの AWS DMS と AWS SCT チームのデータベースエンジニアです。
コメント
コメントを投稿