謎の AI ハードウェア「Versal」
謎の AI ハードウェア「Versal」:
2018年10月、FPGAメーカのXilinx社が従来のハードウェアとは異なる革新的なプラットフォーム「ACAP」を発表した。この記事ではその製品群である「Versal」についてまとめる。
NTTドコモサービスイノベーション部 AdventCalendar2018の24日目の記事です。
ACAPは下記の3つのエンジンがNoCを経由して接続される。
まとめると下記の通り
CPUの汎用性、FPGAの柔軟性、ASICの専門性。
ACAPはこれらを併せ持つハードウェアである。
下記の6シリーズが展開される予定であり、エッジからクラウドまであらゆる用途をカバーする。
その名の通り、自動車などのエッジからクラウドデータセンターまで幅広い用途で用いられるようだ。
2018年時点ではまだ一般向けに提供されておらず、2019年後半から順次販売を始めるとのこと。
Versalの開発環境・開発フローは下記の通り。

開発言語としてPythonが挙げられているが、Pythonで記述したTensorflowやMxnetのモデルをVersal用に変換できるだけであり、Pythonで自由自在に回路を設計できるということではない。
高位合成(C/C++)やVerilogHDL/VHDLが分かる人は今まで通りVivadoで開発できそうである。
ACAPはFPGAの上位互換である。下記スライド2からわかる通り、FPGA→SoCファミリと進化して2018年のACAPに至る。
ARMプロセッサが統合されたのはZynqなどのSoCデバイスからであり、ネットワークや画像処理向けの機能追加が続く。このように進化をたどるとACAPのAdaptable、Scalarの二つのエンジンの機能は、2018年時点で既に存在していたことがわかる。
ACAPが従来と大きく違うのは Inteligent Enginesにある。
2018年はNVIDIA「Turing」、Google「TPU3.0」 など新しいHWが登場した。
これらを横並びで比較してみる。
クラウド上のDeepLearningの世界では特に競争が激しい。
特に推論用途6ではCPU・TPU・GPU・FPGAなど様々なプロセッサの導入が進み、各企業がしのぎを削っている。
ここでは行列演算に特化したユニットを見比べてみる。
詳細は不明だが多数のAIエンジン(2個で1セット)を並べることで行列演算を高速化するようだ。
現在のところデータセンターで使われるFPGA「Virtex」ではxDNNと呼ばれるTPUと同様な機能が提供されている。
Xilinx/ml-suite: Getting Started with Xilinx ML Suite
TPUはGoogleのハードウェアエンジニアが独自に開発したASICである。TPUの行列演算は下記のシストリックアレイと呼ばれる演算器で実行される。データが流れるように処理されるのが一目でわかる。
ちなみにTPUの解説はtpudemo.comのアニメーションがわかりやすいので必見。
Google Cloud Platform Japan 公式ブログ: Google の Tensor Processing Unit (TPU) で機械学習が 30 倍速くなるメカニズム
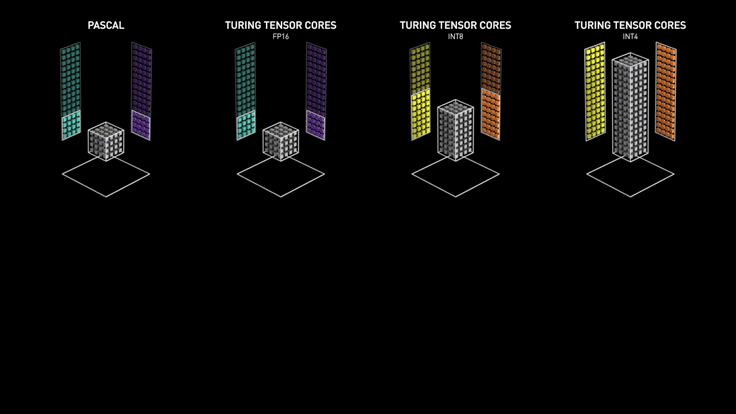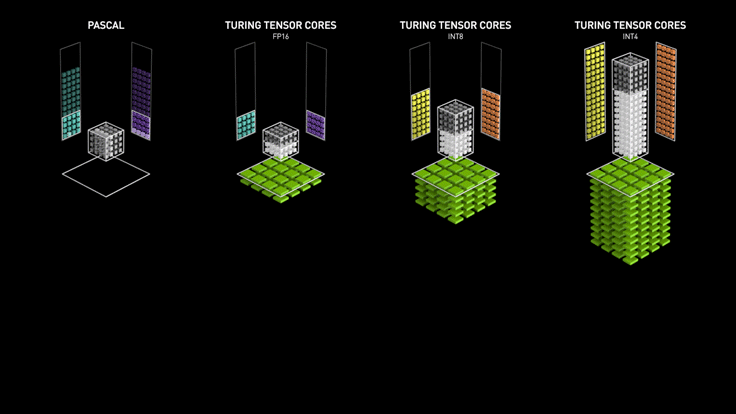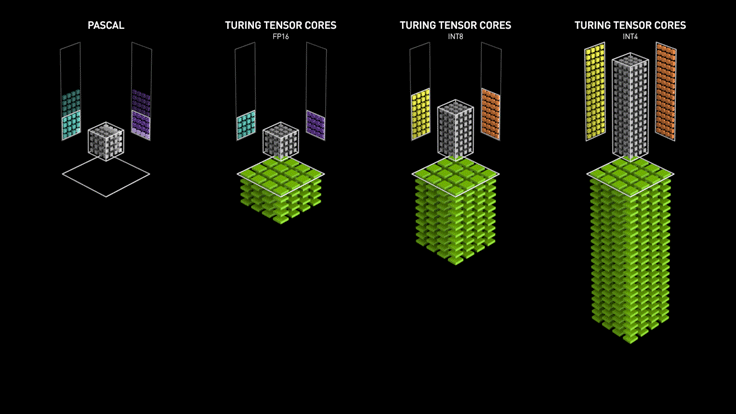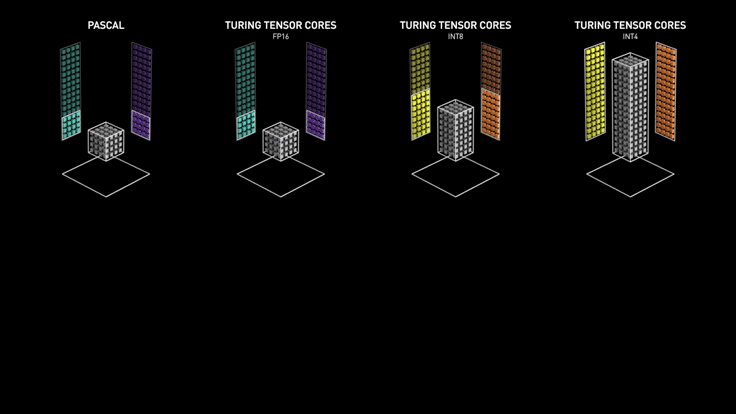
Turing/Voltaの目玉はTensorCoreと呼ばれる独自の行列演算器である。TensorCoreは4×4の行列演算(FP16)を1サイクルで実行する。TPUやVersalでも言えることだが、データ型の精度をINT8やINT4にすればさらに高速化が可能である。
NVIDIAのGPUもエッジデバイスからクラウドデータセンターまで幅広くシリーズ展開している。
記事を書いている途中でこんなニュースが飛び込んできた。
AWSのデータセンターの凄いエンジニアのJames Hamilton氏のブログにはこう記述されている。
Versal AI Coreはデータセンター向けであるが、果たしてAWSで導入されるのだろうか?
AWS Inferentia - Amazon Web Services (AWS)
2018年10月、FPGAメーカのXilinx社が従来のハードウェアとは異なる革新的なプラットフォーム「ACAP」を発表した。この記事ではその製品群である「Versal」についてまとめる。
はじめに
NTTドコモサービスイノベーション部 AdventCalendar2018の24日目の記事です。
ざっくり言うと
- 「ACAP」と呼ばれるCPUとFPGAとASICの集合体のようなハードウェアが発表された
- 「Versal」という製品シリーズとして2019年以降販売が開始される
- 機械学習、自動運転、5G通信など様々な用途に向いている
対象とする人
- GPU,TPUなど機械学習関連のプロセッサ技術に興味がある
- 2020年以降のコンピュータに興味がある
- クリスマスイブ暇すぎてQiitaに来てしまった意識高いマン
やること
- ACAP、Versalの紹介
- 従来のFPGAとの比較
- TPU/GPUとの比較
ACAPとは何か
FPGA およびハードウェア プログラマブル SoC を発明してきたザイリンクスが新たに ACAP (Adaptive Compute Acceleration Platform) という製品カテゴリを打ち出しました。適応性を備えたザイリンクスのシリコンは、高度なソフトウェアとツールを利用することで、民生機器から自動車、クラウドに至るまで幅広い業界および技術にイノベーションをもたらします。CPU、GPUといった従来のハードウェアのカテゴリに対して、新たにACAP(エーキャップ)というハードウェアが加わった。ACAPのアーキテクチャ概観はコチラ。
ザイリンクス - Adaptable. Intelligent.
3つのエンジン
ACAPは下記の3つのエンジンがNoCを経由して接続される。-
Scalar Engines
- ARMプロセッサで構成される
-
Adaptable Engines
- 最新のプログラマブルロジックとメモリセルで構成される
- プログラマブルロジック:ユーザが設計可能な集積回路
- 従来の設計との互換性もサポート
- タスクによって動的にメモリ構成を最適化可能
- 最新のプログラマブルロジックとメモリセルで構成される
-
Intelligent Engines
まとめると下記の通り
| 種別 | 構成要素 | 回路設計 | 用途 | 処理単位 |
|---|---|---|---|---|
| Scalar Engines | ARMプロセッサ | 固定 | 汎用 | 逐次処理 |
| Adaptable Engines | プログラマブルロジック、メモリセル | 再構成可能 | ドメイン特化 | 並列処理 |
| Intelligent Engines | VLIW/SIMDプロセッサ、メモリ | 固定 | ドメイン特化 | 並列処理 |
ACAPはこれらを併せ持つハードウェアである。
Versalとは何か
業界初のACAP(Adaptive Compute Acceleration Platform)であるVersalデバイスは、適応性のあるプロセッシングおよびアクセラレータエンジンとプログラマブルロジック、コンフィギュレーション可能なコネクティビティを兼ね備え、データセンター、オートモーティブ、5G無線通信、有線通信、防衛分野の幅広いアプリケーション向けにカスタマイズされたヘテロジニアスハードソリューションを可能にします。ACAPデバイスは、1つの統合されたシリコンホストインターコネクトシェルと、AIおよびDSPインテリジェントエンジン、適応型エンジン、そしてスカラーエンジンといった大きく様変わりした機能を特長とし、従来のFPGAおよびGPUを上回るワットあたり性能を提供します。VersalとはACAPというデバイスの製品シリーズ1であり、その名は「Versatile(多用途)+Universal(普遍的)」に由来する。
Versal
下記の6シリーズが展開される予定であり、エッジからクラウドまであらゆる用途をカバーする。
| シリーズ名 | 主な用途 | 特徴 |
|---|---|---|
| Versal AI Core | データセンター、無線通信 | 最高性能の演算処理エンジン |
| Versal AI Edge | 自動車(ADAS)、無線通信、 放送、航空宇宙・防衛 |
省エネ演算処理エンジン(5W以下) |
| Versal AI RF | 無線通信、航空宇宙・防衛、有線通信 | ダイレクト無線変換器と ソフトウェア定義の誤り訂正 |
| Versal Prime | データセンター、有線通信 | シェル付属の基本的プラットフォーム |
| Versal Premium | 有線通信、試験測定 | 112Gシャード、600GのIP付属の プレミアムプラットフォーム |
| Versal HBM | データセンター、有線通信、試験測定 | HBM付属のプレミアムプラットフォーム |
2018年時点ではまだ一般向けに提供されておらず、2019年後半から順次販売を始めるとのこと。
開発環境
Versalの開発環境・開発フローは下記の通り。開発言語としてPythonが挙げられているが、Pythonで記述したTensorflowやMxnetのモデルをVersal用に変換できるだけであり、Pythonで自由自在に回路を設計できるということではない。
高位合成(C/C++)やVerilogHDL/VHDLが分かる人は今まで通りVivadoで開発できそうである。
比較① 従来のFPGAとの違い
ACAPはFPGAの上位互換である。下記スライド2からわかる通り、FPGA→SoCファミリと進化して2018年のACAPに至る。| 年代 | デバイス | 主な機能・アップデート |
|---|---|---|
| 1980's | FPGA | FPGA の歴史 |
| 20113 | SoC(System on Chip)4 | ARMプロセッサ統合 |
| 2015 | MPSoC(Multi Proccessing SoC) | リアルタイム処理・グラフィックス機能 |
| 2017 | RFSoC(Radio Frequency SoC) | 高周波データコンバータ統合 |
| 2019 | ACAP | AIエンジン統合 |
ACAPが従来と大きく違うのは Inteligent Enginesにある。
比較② 他のハードウェアとの違い
2018年はNVIDIA「Turing」、Google「TPU3.0」 など新しいHWが登場した。これらを横並びで比較してみる。
- どのデバイスもArray状の行列演算に特化した部分を持つ
- TPUはTensorFlowからそのまま呼び出せるため開発がラク
- VersalもTuringもDeepLearningのフレームワークが対応すれば5Pythonで利用することが可能
- クラウド、エッジの2つの戦場がある
- Versalがクラウドで提供されるとしたらAWSやAlibaba Cloudなどが有力
-
Amazon EC2 F1 インスタンスなど既にFPGAが導入されている
-
- GoogleはGCP/TensorFlow/TPUとソフトからハードまで一気通貫にサービス提供している
- NVIDIAはコンテナを活かしたNVIDIA GPU CLOUDというフレームワークを提供している
- Versalがクラウドで提供されるとしたらAWSやAlibaba Cloudなどが有力
The DeepLearning Hardware Battle
クラウド上のDeepLearningの世界では特に競争が激しい。特に推論用途6ではCPU・TPU・GPU・FPGAなど様々なプロセッサの導入が進み、各企業がしのぎを削っている。
ここでは行列演算に特化したユニットを見比べてみる。
��Versalの「AIエンジン」
詳細は不明だが多数のAIエンジン(2個で1セット)を並べることで行列演算を高速化するようだ。現在のところデータセンターで使われるFPGA「Virtex」ではxDNNと呼ばれるTPUと同様な機能が提供されている。
Xilinx/ml-suite: Getting Started with Xilinx ML Suite
��TPUの心臓「シストリックアレイ」
TPUはGoogleのハードウェアエンジニアが独自に開発したASICである。TPUの行列演算は下記のシストリックアレイと呼ばれる演算器で実行される。データが流れるように処理されるのが一目でわかる。ちなみにTPUの解説はtpudemo.comのアニメーションがわかりやすいので必見。
Google Cloud Platform Japan 公式ブログ: Google の Tensor Processing Unit (TPU) で機械学習が 30 倍速くなるメカニズム
��Turing「Tensor Cores」
Turing/Voltaの目玉はTensorCoreと呼ばれる独自の行列演算器である。TensorCoreは4×4の行列演算(FP16)を1サイクルで実行する。TPUやVersalでも言えることだが、データ型の精度をINT8やINT4にすればさらに高速化が可能である。NVIDIAのGPUもエッジデバイスからクラウドデータセンターまで幅広くシリーズ展開している。
��AWSのASIC「Inferentia」
記事を書いている途中でこんなニュースが飛び込んできた。ご参考までにAWSは2015年にAnnapurna Labsと呼ばれるイスラエルの企業を買収し、ネットワーク向けのASICを独自に設計していた。その開発力を活かして、2018年のre:InventではARMベースの自社製CPU「AWS Graviton Proccessor」とディープラーニング推論向けASIC「Inferentia」を発表した。
▼[速報]AWS、独自の機械学習用プロセッサ「AWS Inferentia」発表。高速な推論処理に特化。A…https://t.co/5g6hJveYOJ#deeplearning
— 人工知能,機械学習関係ニュース研究所 (@AI_m_lab) 2018年11月28日
AWSのデータセンターの凄いエンジニアのJames Hamilton氏のブログにはこう記述されている。
We support the frameworks customers are using, and have AWS hardware-optimized versions of the important ML frameworks including MxNet, PyTorch, and TensorFlow. In fact, 85% of cloud-hosted TensorFlow workloads are running on AWS.TensorFlowが圧倒的に重要なのはAWSも把握している。今回の「Graviton」と「Inferentia」の発表はTPUをかなり強く意識しているのは間違いない。
AWS Inferentia Machine Learning Processor – Perspectives
Versal AI Coreはデータセンター向けであるが、果たしてAWSで導入されるのだろうか?
AWS Inferentia - Amazon Web Services (AWS)
個人的な所感
- Turingはどちらかというと画像処理で進化した部分が大きい。今後GPUはVR分野で力を発揮しそう。
- DeepLearningのフレームワークではTensorFlowの力が強く、その影響はハードウェアの世界にも及ぶ
- GoogleColaboratoryでいつでもTPUが使えるのも強い
- ACAPはネットワーク処理まで統合している点、回路をカスタマイズできる点が他との大きく違う。
- 特にIoTデバイスでは省エネ、ストリーミング処理など力を発揮できそう。
- AWSが自社開発のInferentiaを発表したことで、クラウド推論はTPUなどのASICがメインになりそう。
コメント
コメントを投稿