Amazon Aurora PostgreSQL によるフェイルオーバー
Amazon Aurora PostgreSQL によるフェイルオーバー:
レプリケーション、フェイルオーバー、レジリエンス、災害対策、バックアップ—従来の、または非クラウドベースのアーキテクチャでは、これらの一部またはすべてを実現するのはとても困難です。さらに、時にはかなりのリエンジニアリング作業が必要になることがあります。関係する実装やインフラストラクチャのコストが高いため、一部の企業では最も重要なアプリケーションのみが適切に保護されるようにアプリケーションを階層化せざるを得ません。
こうした懸念は、Amazon Aurora for PostgreSQL に移行すること軽減できます。AWS は、Oracle、MySQL、PostgreSQL、Aurora を含む (ただしこれらに限定されない) 幅広い種類のリレーショナルデータベースエンジンを提供しています。PostgreSQL の場合、AWS は Amazon EC2 インスタンスでの PostgreSQL、Amazon RDS for PostgreSQL、Amazon Aurora with PostgreSQL compatibility を含むさまざなバリエーションをサポートしています。適切なバージョンの PostgreSQL を選択するための多くの指標の中で、以下のいくつかが重要です。
高可用性: HA は、Aurora PostgreSQL のアーキテクチャに組み込まれており、3 つのアベイラビリティーゾーンにわたって 6 つのデータコピーが維持されています。つまり、アベイラビリティーゾーンごとに 2 つのコピーがあることになり、いずれかのアベイラビリティーゾーン全体がダウンしてもわずかな中断で済むことから可用性が向上します。さらに、データベースは Amazon S3 に継続的にバックアップされるため、S3 の高耐久性 (99.999999999) をバックアップで利用できます。Aurora PostgreSQL は、ポイントインタイムリカバリもサポートしています。
パフォーマンス: Amazon Aurora PostgreSQL は、Amazon EC2 での PostgreSQL と比較して最大 3 倍のパフォーマンスを提供します。ベンチマークテストの詳細については、「Amazon Aurora PostgreSQL-compatible Edition Benchmarking Guide」をダウンロードしてください。さらに、Performance Insights を使うと、データベースの分析やトラブルシューティングが容易になります。
管理容易性: Amazon Aurora PostgreSQL は、プロビジョニング、パッチ適用、バックアップ、リカバリ、障害検出、修復などの日常的なデータベースタスクを処理することで管理を簡素化します。Aurora のストレージは、自動的にスケーリングされ、フリート全体の I/O を拡張および再調整して、一貫したパフォーマンスを提供します。
この記事では、Amazon Aurora のクラスターとエンドポイントの概要と、設定の変更を最小限に抑えて読み込みのフェイルオーバーとロードバランシングを実現する方法について説明します。Aurora クラスターでフェイルオーバーがどのように機能するかを示す例を紹介し、フェイルオーバーを透過的にする方法について説明します。この記事では主に Amazon Aurora PostgreSQL について説明しますが、ほとんどの概念は Amazon Aurora MySQL に適用することもできます。
Amazon Aurora Replicas は、ソースインスタンスと同じ基本ストレージを共有し、コストを削減し、レプリカノードにデータをコピーする必要性を回避します。Amazon RDS for PostgreSQL リードレプリカは、物理的コピーです。ソースデータベースインスタンスに変更があるたびに、非同期のレプリケーション方法を使用してリードレプリカを更新します。また、RDS for PostgreSQL では、データベースソースインスタンスごとに 5 つのリードレプリカに制限されますが、Aurora クラスターは 1 つのプライマリ (マスターまたは読み取り/書き込み) インスタンスと最大 15 のリードレプリカをサポートします。
次の図は、マスターと 3 つのリードレプリカを備えた Aurora PostgreSQL のアーキテクチャを示しています。

Aurora のアーキテクチャの詳細については、AWS データベースブログの記事「Introducing the Aurora Storage Engine」を参照してください。
インスタンスレベルでは、インスタンスごとに 1 つのエンドポイントが作成されます。インスタンスエンドポイントでは、従来の接続のようにインスタンスに直接接続します。インスタンスエンドポイントのみを使用する (クラスターエンドポイントなし) ことは、正当な理由がない場合はお勧めできません。インスタンスエンドポイントとともにクラスターエンドポイントを使用することで、読み取りクエリの手動ロードバランシングを行うことができます。
次の図は、エンドポイントの仕組みを示しています。
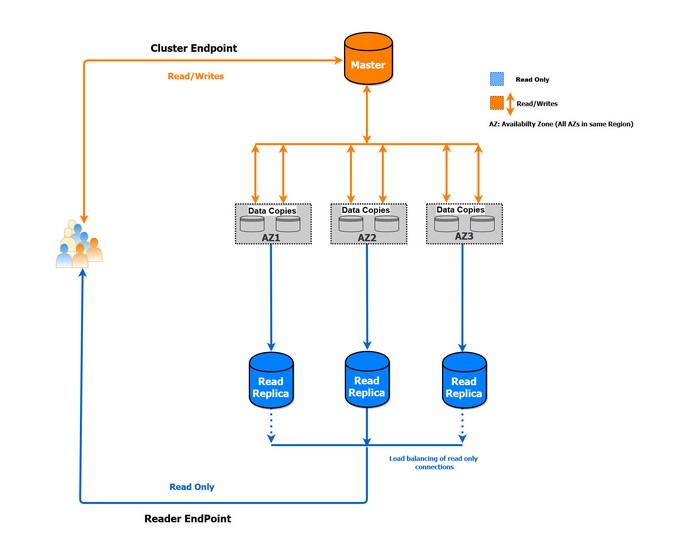
注意: DB クラスターの名前を変更すると、クラスターエンドポイントおよびリーダーエンドポイントが変更されます。
Amazon RDS コンソールで、ナビゲーションペインの [Clusters] を選択して、クラスターエンドポイントとリーダーエンドポイントを見つけることができます。

クラスターエンドポイントを使用して接続し、接続リトライロジックを実装すると、アプリケーションはサービスの中断を最小限に抑えることができます。フェイルオーバー中、AWS は、新しく作成/昇格された DB インスタンスを指すようにクラスターエンドポイントを変更します。適切に設計されたアプリケーションは自動的に再接続します。フェイルオーバー時のダウンタイムは、正常なリードレプリカの存在によって異なります。リードレプリカが設定されていないか、既存のリードレプリカが正常でない場合、新しいインスタンスを作成するためにダウンタイムが長くなることがあります。
この図は、

次のコードは、クラスターエンドポイントを使用したポート 5432 でのデータベース
次のコードは、リーダーエンドポイントを使用するリードレプリカインスタンスへの接続と、失敗したトランザクションを示しています。
予期したとおり、読み取り専用レプリカは書き込み可能なトランザクションをサポートしていないため、エラーが発生します。

手動フェイルオーバーを実行するには、コンソールでプライマリインスタンス名を選択し、[Instance actions] メニューで [Failover] を選択します。
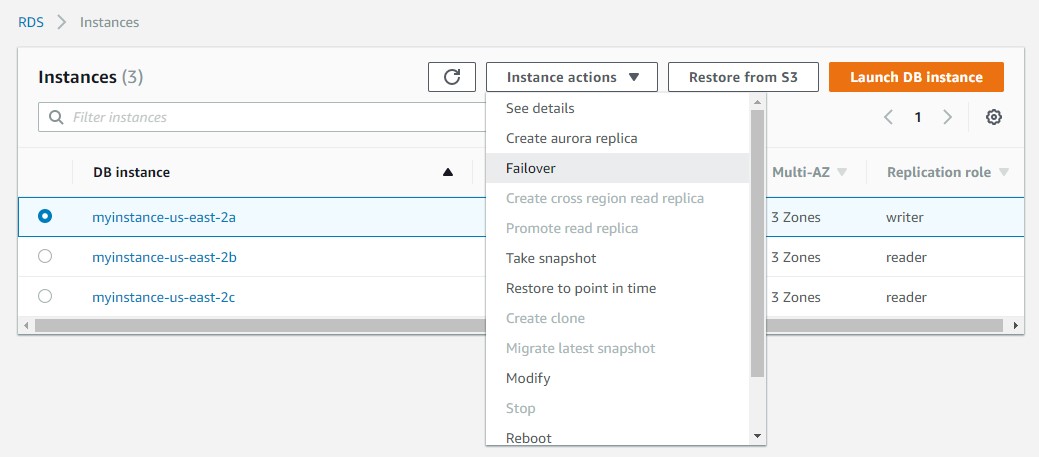
その後、[Failover] ウィンドウで確認します:

手動フェイルオーバーが完了すると、
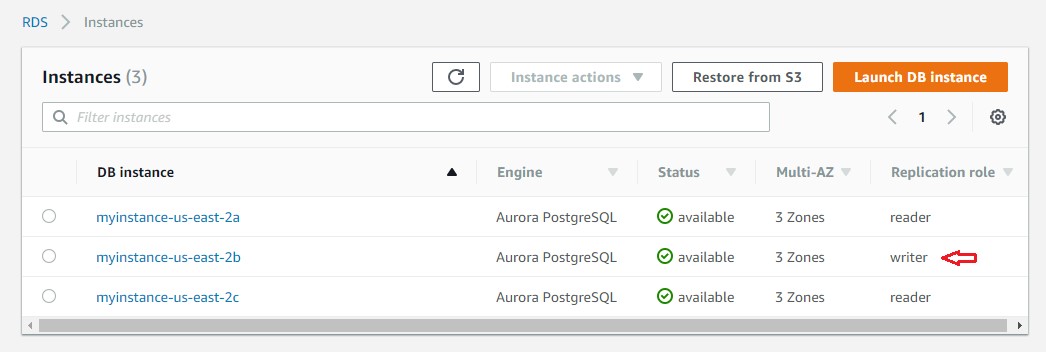
次のスクリーンショットは、リードレプリカが RDS コンソールで新しいプライマリになることを示しています:
上のコードが示すように、接続はエンドポイントを変更せずに成功します。アプリケーション接続リトライロジックを追加することで、フェールオーバーを透過的にすることができます。
クラスターエンドポイントとともに、積極的な TCP キープアライブ設定や JDBC 接続設定、または
アプリケーションがフェイルオーバーに対応する方法はたくさんありますが、クラスターエンドポイントとリーダーエンドポイントを使用すると、設定変更を最小限に抑えてフェイルオーバーと負荷分散を実現できます。また、次の TCP キープアライブおよび JDBC のベストプラクティスとともにクラスターエンドポイントを使用することで、高速フェイルオーバーと高可用性を実現できます。インスタンスエンドポイントをプライマリエンドポイントとして使用することはお勧めしません。ただし、読み込みの手動ロードバランシングをサポートするために使用することはできます。さらに、自動リトライ機能をアプリケーションに追加することで、フェイルオーバーを透過的にすることができます。
 Shan Nawaz は、アマゾン ウェブ サービスのビッグデータコンサルタントです。 彼は、AWS を使用している場合にソリューションの価値を向上させる手助けとなるために、AWS の顧客と協力してデータベースおよびビッグデータのプロジェクトに関する指導や技術支援を行っています。
Shan Nawaz は、アマゾン ウェブ サービスのビッグデータコンサルタントです。 彼は、AWS を使用している場合にソリューションの価値を向上させる手助けとなるために、AWS の顧客と協力してデータベースおよびビッグデータのプロジェクトに関する指導や技術支援を行っています。
レプリケーション、フェイルオーバー、レジリエンス、災害対策、バックアップ—従来の、または非クラウドベースのアーキテクチャでは、これらの一部またはすべてを実現するのはとても困難です。さらに、時にはかなりのリエンジニアリング作業が必要になることがあります。関係する実装やインフラストラクチャのコストが高いため、一部の企業では最も重要なアプリケーションのみが適切に保護されるようにアプリケーションを階層化せざるを得ません。
こうした懸念は、Amazon Aurora for PostgreSQL に移行すること軽減できます。AWS は、Oracle、MySQL、PostgreSQL、Aurora を含む (ただしこれらに限定されない) 幅広い種類のリレーショナルデータベースエンジンを提供しています。PostgreSQL の場合、AWS は Amazon EC2 インスタンスでの PostgreSQL、Amazon RDS for PostgreSQL、Amazon Aurora with PostgreSQL compatibility を含むさまざなバリエーションをサポートしています。適切なバージョンの PostgreSQL を選択するための多くの指標の中で、以下のいくつかが重要です。
- 高可用性 (HA)
- パフォーマンス
- 管理のしやすさ
高可用性: HA は、Aurora PostgreSQL のアーキテクチャに組み込まれており、3 つのアベイラビリティーゾーンにわたって 6 つのデータコピーが維持されています。つまり、アベイラビリティーゾーンごとに 2 つのコピーがあることになり、いずれかのアベイラビリティーゾーン全体がダウンしてもわずかな中断で済むことから可用性が向上します。さらに、データベースは Amazon S3 に継続的にバックアップされるため、S3 の高耐久性 (99.999999999) をバックアップで利用できます。Aurora PostgreSQL は、ポイントインタイムリカバリもサポートしています。
パフォーマンス: Amazon Aurora PostgreSQL は、Amazon EC2 での PostgreSQL と比較して最大 3 倍のパフォーマンスを提供します。ベンチマークテストの詳細については、「Amazon Aurora PostgreSQL-compatible Edition Benchmarking Guide」をダウンロードしてください。さらに、Performance Insights を使うと、データベースの分析やトラブルシューティングが容易になります。
管理容易性: Amazon Aurora PostgreSQL は、プロビジョニング、パッチ適用、バックアップ、リカバリ、障害検出、修復などの日常的なデータベースタスクを処理することで管理を簡素化します。Aurora のストレージは、自動的にスケーリングされ、フリート全体の I/O を拡張および再調整して、一貫したパフォーマンスを提供します。
この記事では、Amazon Aurora のクラスターとエンドポイントの概要と、設定の変更を最小限に抑えて読み込みのフェイルオーバーとロードバランシングを実現する方法について説明します。Aurora クラスターでフェイルオーバーがどのように機能するかを示す例を紹介し、フェイルオーバーを透過的にする方法について説明します。この記事では主に Amazon Aurora PostgreSQL について説明しますが、ほとんどの概念は Amazon Aurora MySQL に適用することもできます。
Aurora クラスターの概要
Amazon EC2 での PostgreSQL や Amazon RDS for PostgreSQL とは異なり、Aurora PostgreSQL DB インスタンスを作成すると、実際にはデータベースクラスターが作成されます。Aurora PostgreSQL では、DB クラスタは 1 つの読み取り/書き込みインスタンスと最大 15 の読み取りインスタンスのコレクション、ならびに複数のアベイラビリティーゾーンにまたがるデータストレージ (クラスターボリューム) です。それぞれのアベイラビリティーゾーンは、DB クラスターデータの 2 つのコピーを保持します。Amazon Aurora Replicas は、ソースインスタンスと同じ基本ストレージを共有し、コストを削減し、レプリカノードにデータをコピーする必要性を回避します。Amazon RDS for PostgreSQL リードレプリカは、物理的コピーです。ソースデータベースインスタンスに変更があるたびに、非同期のレプリケーション方法を使用してリードレプリカを更新します。また、RDS for PostgreSQL では、データベースソースインスタンスごとに 5 つのリードレプリカに制限されますが、Aurora クラスターは 1 つのプライマリ (マスターまたは読み取り/書き込み) インスタンスと最大 15 のリードレプリカをサポートします。
次の図は、マスターと 3 つのリードレプリカを備えた Aurora PostgreSQL のアーキテクチャを示しています。
Aurora のアーキテクチャの詳細については、AWS データベースブログの記事「Introducing the Aurora Storage Engine」を参照してください。
エンドポイント
Aurora PostgreSQL インスタンスへの接続は、エンドポイントを使用して行われます。エンドポイントとは、コロンで区切られたホストアドレスとポートを含む URL です。Aurora PostgreSQL インスタンスを作成すると、AWS はクラスターレベルとインスタンスレベルでエンドポイントを作成します。クラスターレベルでは、読み取り/書き込み操作 (クラスターエンドポイントと呼ばれる) 用と読み取り専用操作用 (リーダーエンドポイントと呼ばれる) の 2 つのエンドポイントが作成されます。フェイルオーバーはクラスターエンドポイントを通じて可能になりますが、複数のリードレプリカ間での読み取り専用接続の負荷分散はリーダーエンドポイントを通じて実現されます。また、クラスターにリードレプリカがない場合、リーダーエンドポイントはプライマリインスタンスへの接続を提供します。インスタンスレベルでは、インスタンスごとに 1 つのエンドポイントが作成されます。インスタンスエンドポイントでは、従来の接続のようにインスタンスに直接接続します。インスタンスエンドポイントのみを使用する (クラスターエンドポイントなし) ことは、正当な理由がない場合はお勧めできません。インスタンスエンドポイントとともにクラスターエンドポイントを使用することで、読み取りクエリの手動ロードバランシングを行うことができます。
次の図は、エンドポイントの仕組みを示しています。
注意: DB クラスターの名前を変更すると、クラスターエンドポイントおよびリーダーエンドポイントが変更されます。
Amazon RDS コンソールで、ナビゲーションペインの [Clusters] を選択して、クラスターエンドポイントとリーダーエンドポイントを見つけることができます。
フェイルオーバーの仕組み
DB クラスターのプライマリインスタンスに障害が発生すると、Aurora は自動的に次の順序でフェイルオーバーします。- Aurora のリードレプリカが使用可能な場合は、既存のリードレプリカを新しいプライマリインスタンスに昇格させます。
- リードレプリカが使用可能でない場合は、新しいプライマリインスタンスを作成します。
クラスターエンドポイントを使用して接続し、接続リトライロジックを実装すると、アプリケーションはサービスの中断を最小限に抑えることができます。フェイルオーバー中、AWS は、新しく作成/昇格された DB インスタンスを指すようにクラスターエンドポイントを変更します。適切に設計されたアプリケーションは自動的に再接続します。フェイルオーバー時のダウンタイムは、正常なリードレプリカの存在によって異なります。リードレプリカが設定されていないか、既存のリードレプリカが正常でない場合、新しいインスタンスを作成するためにダウンタイムが長くなることがあります。
Aurora クラスターのフェイルオーバーの例
それでは、Amazon Aurora クラスターのフェイルオーバーの例を見てみましょう。次のテーブルに、マスターと 2 つのリードレプリカを備えたクラスターの詳細を示します。| クラスター名 | pgcluster |
| マスターインスタンス | myinstance-us-east-2a |
| リードレプリカ | myinstance-us-east-2b (優先順位 0) |
| リードレプリカ | myinstance-us-east-2c (優先順位 1) |
| クラスターエンドポイント | pgcluster.cluster-xxxxxxxxxx.us-east-2.rds.amazonaws.com |
| リーダーエンドポイント | pgcluster.cluster-ro-xxxxxxxxxx.us-east-2.rds.amazonaws.com |
pgcluster という名前の Aurora PostgreSQL クラスターを表しています。クラスターエンドポイント pgcluster.cluster-xxxxxxxxxx.us-east-2.rds.amazonaws.com は、現在インスタンス myinstance-us-east-2a を指していることに注意してください。次のコードは、クラスターエンドポイントを使用したポート 5432 でのデータベース
pgdb への接続を示しています。このイラストの一部として、この例では failover という名前のテーブルを作成し、テーブルに 1 つの行を挿入します。psql -h pgcluster.cluster-xxxxxxxxxx.us-east-2.rds.amazonaws.com -d pgdb -p 5432 -U pgadmin
--マスターインスタンスの名前をリストする
pgdb=> select server_id from aurora_replica_status() where session_id='MASTER_SESSION_ID';
server_id
-----------------------
myinstance-us-east-2a
(1 row)
pgdb=> CREATE TABLE FAILOVER(FAILOVERNAME VARCHAR(20), FAILOVERTYPE INTEGER);
CREATE TABLE
pgdb=>
pgdb=> INSERT INTO FAILOVER VALUES ('TEST-1',1 );
INSERT 0 1
pgdb=>
pgdb=> SELECT * FROM FAILOVER;
failovername | failovertype
-----------------+--------------
TEST-1 | 1
(1 row)failover テーブルが、リーダーエンドポイントを介してリードレプリカからアクセスされ、同期を検証します。psql -h pgcluster.cluster-ro-xxxxxxxxxx.us-east-2.rds.amazonaws.com -d pgdb -p 5432 -U pgadmin
--マスターインスタンスの名前をリストする
pgdb=> select server_id from aurora_replica_status() where session_id='MASTER_SESSION_ID';
server_id
-----------------------
myinstance-us-east-2a
(1 row)
pgdb=> SELECT * FROM FAILOVER;
failovername | failovertype
-----------------+--------------
TEST-1 | 1
(1 row)
pgdb=> INSERT INTO FAILOVER VALUES (‘TEST-2’, 1 );
ERROR: cannot execute INSERT in a read-only transaction
手動フェイルオーバー
次のスクリーンショットは、Amazon RDS コンソールの現在のプライマリmyinstance-us-east-2a を示しています:手動フェイルオーバーを実行するには、コンソールでプライマリインスタンス名を選択し、[Instance actions] メニューで [Failover] を選択します。
その後、[Failover] ウィンドウで確認します:
手動フェイルオーバーが完了すると、
myinstance-us-east-2b インスタンスが新しいプライマリに昇格し、myinstance-us-east-2a インスタンスのロールが「リードレプリカ」に変わります。また、クラスターエンドポイントは myinstance-us-east-2b を指しますが、myinstance-us-east-2a はリーダーエンドポイントを介して使用可能です。次のスクリーンショットは、リードレプリカが RDS コンソールで新しいプライマリになることを示しています:
インスタンスの再接続
これで、同じクラスタエンドポイントを使用して再接続できます。psql -h pgcluster.cluster-xxxxxxxxxx.us-east-2.rds.amazonaws.com -d pgdb -p 5432 -U pgadmin
--フェイルオーバー後のマスターインスタンスの名前をリストする
pgdb=> select server_id from aurora_replica_status() where session_id='MASTER_SESSION_ID';
server_id
-----------------------
myinstance-us-east-2b
(1 row)
pgdb=> INSERT INTO FAILOVER VALUES (‘TEST-2’, 1 );
INSERT 0 1
pgdb=> SELECT * FROM FAILOVER;
failovername | failovertype
--------------------+--------------
TEST-1 | 1
TEST-2 | 1
(2 rows)クラスターエンドポイントとともに、積極的な TCP キープアライブ設定や JDBC 接続設定、または
PGConn クラスをアプリケーションレベルで設定することで、フェイルオーバーにより迅速に対応することもできます。詳細については、「Best Practices with Amazon Aurora PostgreSQL」を参照してください。結論
組織のための稼働時間のサービスレベルアグリーメント (SLA) を達成するには、無人復旧の処理が非常に重要です。Aurora PostgreSQL は革新的なフェイルオーバーアーキテクチャを採用しているため、可用性と信頼性の向上だけでなく、読み取りのスケーラビリティによるパフォーマンスの向上も実現します。アプリケーションがフェイルオーバーに対応する方法はたくさんありますが、クラスターエンドポイントとリーダーエンドポイントを使用すると、設定変更を最小限に抑えてフェイルオーバーと負荷分散を実現できます。また、次の TCP キープアライブおよび JDBC のベストプラクティスとともにクラスターエンドポイントを使用することで、高速フェイルオーバーと高可用性を実現できます。インスタンスエンドポイントをプライマリエンドポイントとして使用することはお勧めしません。ただし、読み込みの手動ロードバランシングをサポートするために使用することはできます。さらに、自動リトライ機能をアプリケーションに追加することで、フェイルオーバーを透過的にすることができます。
著者について
Shan Nawaz は、アマゾン ウェブ サービスのビッグデータコンサルタントです。 彼は、AWS を使用している場合にソリューションの価値を向上させる手助けとなるために、AWS の顧客と協力してデータベースおよびビッグデータのプロジェクトに関する指導や技術支援を行っています。
コメント
コメントを投稿