Google ColabのTPUで対GPUの最速に挑戦する
Google ColabのTPUで対GPUの最速に挑戦する:
前回の記事が思わぬ反響で驚愕していますが、今回はColabのTPUを限界まで試してみたいと思います。特殊な条件にするとColabのTPUは、GPU比で20倍以上速くなることがわかりました。しかも無料です。それを見ていきましょう。
前回の結果からTPUがGPUと比べて速くなる条件は2つあることがわかりました。
またGPUで行ったフレームワーク別の調査をTPUに適用したところ、TPUではモデル(ResNet)が小さすぎて、層を深くしてもほぼ計算時間が変わらないという現象がありました1。
これはTPUが速すぎるというよりも、計算量が少なすぎて他のボトルネックのほうが支配的になっているから、と考えることができます。つまり、CNNだとGPUよりTPUのほうが速くなりやすいというよりも、パラメーター(計算量)が物凄い多いCNNだとGPUよりTPUのほうがより相対的に速くなるというほうが適切であるかのように思われます。
CNNのパラメーター数と計算量はおおよそ比例するので、要はパラメーターの多いCNNを作ればTPUの本気が見れるということにもなります。ただし、ここには1つ失敗例があってあまりに深い(パラメーター数84.9M、レイヤー数1000以上)NASNet Largeを使って学習させたところ、TPUの重みの初期設定で失敗してハングアップするという現象がありました。ちなみにNASNet LargeはGPUでバッチサイズ1024にしても訓練できます2。詳しくはこちらに書きました。どこまでいけるのかは試していませんが、あまりにも深いモデルはダメということでしょうか。
パラメーターが多くする必要があるので、今回WideResNetを改造して作りました。ちなみにオリジナルのWideResNetのCIFARの構成は以下のとおりです。
ここでkはチャンネルの大きさ(モデルの厚み)、Nは層の深さ(モデルの深さ)を表します。今回は極端に深くしたくないので、k=7, N=4としました。そして今回の大きな変更点は、オリジナルでは3x3の畳み込みを7x7の畳み込みに変更したことです。これでパラメーター数が49÷9≒5.4倍ぐらいになります。あくまで実験用にパラメーター数を増やすためのテクニックなので、通常はカーネルサイズを7x7にする必要はまずないです。
モデル生成のKerasのコードは以下の通りです。
TPUとGPU両方対応させるために、tensorflow.kerasで定義しました。summaryを見てみます。長いので全体はこちら。総パラメーター数は103Mと1億超えです。
これを使ってColabのGPUとTPU両方で訓練時間を比較していきます。
また、デバイス、バッチサイズ別に以下の8パターンを試します。また、各パターンについて、(Validationデータを使うか, DataAugmentationを使うか, データをストレージから読ませるか)の順でTuple形式で条件を略して表記します。
この8パターンを、デバイスバッチサイズごと(9パターン)に計72ケース測定します。
コードはこちらにあります。https://github.com/koshian2/TPU-Benchmark
8パターンのうち最もデバイス、バッチサイズ間の差が大きかったパターン3(T, T, F)を示します。全体の結果はこちら
実測値ベースでは、同一バッチサイズで比較するとTPU-256はGPU-256の3.07倍速く、異なるバッチサイズでの比較を許容するとTPU-4096はGPU-64の21.93倍速い結果となりました。
また、GPU・TPUとも1エポック目のみ遅く(TPUは特に顕著)、2エポック目以降はより短い時間で安定的に訓練が進むという傾向があるので、エポック数が多くなれば、全体の訓練時間の比は2エポック目以降のエポックあたりの時間の比に収束します。この「ep.2~平均」で比較すると、同一バッチサイズならTPU-256はGPU-256の3.17倍速く、異なるバッチサイズならTPU-4096はGPU-64の24.33倍速いという結果になりました。
ただ、異なるバッチサイズでの比較を許容するのなら、TPU-64はGPU-256の1.14倍遅いというのも言えるため、必ずしもTPUが対GPUで最速であるということを保証できるものではありません。しかし、トップ差でTPUはGPUの20倍以上速くなるという結果も同様に出ているので、その点はしっかり受け止めるべきではないかと思います。
この時間の差を体感するために、エポック数を変えて訓練した場合の総時間を推定してみました。計算式は「[訓練前]+[ep.1]+[ep.2平均]×([エポック数]-1)」です。実践的に(T, T, T)で並列数1=パターン6での一覧です。
GPU-64というのが極端な値だとしてもバッチサイズを大きくできれば、仮に2000エポックも訓練させる場合は、18~25日(430時間~630時間)vs2日前後という大きな差が生まれます。正直2000エポックも訓練させるのにColabを使うのは本来の使い方ではありませんが、クラウド版TPUもあるので3TPUで長時間訓練させることが不可能ではありません。
機械学習自体が反復のプロセスなので、1つのモデルを訓練するのに1ヶ月近くかかるのと2日で終わるのでは、時間あたりの反復回数が全然変わってきます。それはつまりより多くのアイディアを試せることになるので、結果的には時間あたりの生産性を増やしたり、精度を向上できる可能性が大きくなることを意味します。「速さは正義」なのです。
また、最近(2018年9月)にState of the Artを達成したBigGANというモデルによれば、バッチサイズを大きくすることがGANの安定化に寄与するという研究があります。これはGANの場合ですが、バッチサイズを大きくすることによって訓練速度以外のメリットを享受できるという明確な証拠でもあります。一般的にはバッチサイズを変えることはハイパーパラメータをチューニングし直す必要があり、面倒に感じるかもしれませんが、これから新規でモデルを作る場合は、もしメモリの要件が許すのならバッチサイズを大きくして作ったほうがいいのかもしれません。ちなみにこのBigGANはTPUで訓練しているとのことです。
次に細かく条件を分けて見ていきます。
バッチサイズ別の2エポック目以降のエポックあたりの平均秒をグラフで示したものです。(F, F, F)のパターン1で比較しました。バッチサイズを大きくするとTPUは非常に速くなるのは確認の通りです。
グラフの縦軸を対数スケールにしてみました。
これを見ると、TPUは対数スケールではほぼ直線的に速くなっているのがわかります。GPUは3ケースなのでなんとも言えませんが、256あたりで頭打ち感が否めません。TPUも4096あたりは若干頭打ちな印象はありますね。
次にエポックの最後にValidationデータを入れることで訓練時間がどの程度変わるかを見ます。CIFAR-100のテストデータをValidationとして入れたため、Validationの有無でデータ数が5万と6万の違いがあります。これは(F, F, F)のパターン1と、(T, F, F)のパターン2を比較したものですが、データ数が1万増えているので、Validationを入れたほうが遅くなるのは当たり前と言えるでしょう。
しかし、データ数が1.2倍の割にはそこまで処理時間は増えていないように見えます。(T, F, F)の時間を(F, F, F)の時間で割って、Validationの有無による時間比を求めてみます。
Validationを入れたほうが時間が増えるのはそうだとしても、データ数が1.2倍になっているのに処理時間は1.2倍までなっていませんね。おそらくですがValidationだとBack Propagationを計算しないため速い4のでしょう。Validationのデータ数は訓練データよりもずっと少ないことが多いので、これだったらGPU/TPU問わずどんどんValidationを入れたほうがいいように思えます。モデルのチェックポイント作ったり何かと有用なので。
(T, F, F)のパターン2と(T, T, F)のパターン3を比較しました。予想に反してDataAugmentationをしたほうが速くなるという結果が出ました。
DataAugmentationをしたパターン(T, T, F)をしなかったパターン(T, F, F)で割ったものが以下のとおりです。DataAugmentationをしたほうが最大で1割近く速くなっているという奇妙な結果となりました。
これには2つ理由が考えられると思います。
常識的には「メモリから読み込むと速い、ストレージ(HHD,SSD)から読み込むと遅い」ということは考えられますが、ストレージからデータを読み込ませた場合どの程度速度の変化が現れるのでしょうか。(F, F, F)のパターン1と(F, F, T)のパターン4を比較してみます。
これも意外な結果になって、「ストレージから読み込ませると速い」という結果になりました。
ただ、よく考えてみると、これもDataAugmentationの場合とほぼ同じで、結局はfitとfit_generatorの差だよなという印象は拭えません。ストレージから読み込む場合は、ImageDataGeneratorのflow_from_directoryを用いました。
本来はUnixBenchを動かしてストレージの読み込み速度を見るべきですが、上手く動かなかったので諦めました。一般的にはストレージの読み込み速度を見ると、シーケンシャルリードがHDDで150MB/s、SSDで500MB/s(あくまで大雑把な目安で物によって全然違う)ぐらいなので、おそらくCIFAR程度だとストレージからの読み込みがボトルネックにならないのかと思います。CIFAR-100の6万枚をpngファイルに書き出してtar.gzで固めたところ126MBでしたので、1周50秒で訓練させたとしてもこのケースではまだまだストレージ側は余裕があるはずです。
自然に考えると「並列化したほうが速い」と思われますがどうでしょうか。並列化をする場合は、model.fit/fit_generatorの「workers=4, use_multiprocessing=True」としました。(T, T, T)で並列数1(パターン6)と並列数4(パターン8)を比較しました。
GPU-256の並列数1がすごく遅くなっていますが、多分環境の調子が悪かったのだと思います。これだけ2エポック目以降の時間の標準偏差が他の50倍近くあるので。
これは並列数4の時間を並列数1で割ったものです。この数字が小さくなるほど並列化の効果が出ることになります。GPUやTPUの少ないバッチ数(~1024)ではある程度は並列化の効果はあるものの、TPUでバッチサイズが大きくなったときに並列化すると逆に遅くなるというのが確認できました。
ここで1つ大きな疑問がわきます。DataAugmentationとストレージのところであった、「実はこれらが高速化に寄与しているのではなくてfit_generatorが速いからでは」という疑問です。そこで次の3つのモードを定義して追試することにしました。
1,2,3のところは2エポック目以降の平均時間を記したもの、2÷1はモード2の時間をモード1で割ったもの、3÷1はモード3をモード1で割ったものです。
これらを見ると、先程の仮説はどちらも正しいということが言えそうです。つまり、
とても長くなってしまいましたが、結論をまとめましょう
最後にKerasの作者のFrançois Cholletさんの言葉で締めくくりたいと思います。
前回の記事が思わぬ反響で驚愕していますが、今回はColabのTPUを限界まで試してみたいと思います。特殊な条件にするとColabのTPUは、GPU比で20倍以上速くなることがわかりました。しかも無料です。それを見ていきましょう。
TPUがGPUと比べて速くなる条件とは
前回の結果からTPUがGPUと比べて速くなる条件は2つあることがわかりました。- 多層パーセプトロン(MLP)よりも畳み込みニューラルネットワーク(CNN)であること
- バッチサイズを大きくできること
またGPUで行ったフレームワーク別の調査をTPUに適用したところ、TPUではモデル(ResNet)が小さすぎて、層を深くしてもほぼ計算時間が変わらないという現象がありました1。
これはTPUが速すぎるというよりも、計算量が少なすぎて他のボトルネックのほうが支配的になっているから、と考えることができます。つまり、CNNだとGPUよりTPUのほうが速くなりやすいというよりも、パラメーター(計算量)が物凄い多いCNNだとGPUよりTPUのほうがより相対的に速くなるというほうが適切であるかのように思われます。
CNNのパラメーター数と計算量はおおよそ比例するので、要はパラメーターの多いCNNを作ればTPUの本気が見れるということにもなります。ただし、ここには1つ失敗例があってあまりに深い(パラメーター数84.9M、レイヤー数1000以上)NASNet Largeを使って学習させたところ、TPUの重みの初期設定で失敗してハングアップするという現象がありました。ちなみにNASNet LargeはGPUでバッチサイズ1024にしても訓練できます2。詳しくはこちらに書きました。どこまでいけるのかは試していませんが、あまりにも深いモデルはダメということでしょうか。
パラメーター1億オーバーのWideResNet
パラメーターが多くする必要があるので、今回WideResNetを改造して作りました。ちなみにオリジナルのWideResNetのCIFARの構成は以下のとおりです。ここでkはチャンネルの大きさ(モデルの厚み)、Nは層の深さ(モデルの深さ)を表します。今回は極端に深くしたくないので、k=7, N=4としました。そして今回の大きな変更点は、オリジナルでは3x3の畳み込みを7x7の畳み込みに変更したことです。これでパラメーター数が49÷9≒5.4倍ぐらいになります。あくまで実験用にパラメーター数を増やすためのテクニックなので、通常はカーネルサイズを7x7にする必要はまずないです。
モデル生成のKerasのコードは以下の通りです。
import tensorflow as tf
from tensorflow.contrib.tpu.python.tpu import keras_support
from tensorflow.keras.layers import Input, Conv2D, BatchNormalization, Activation, Add, AveragePooling2D, GlobalAveragePooling2D, Dense
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.models import Model
def create_residual_blocks(input_tensor, base_ch, k, N):
start_tensor = input_tensor
for i in range(N):
x = Conv2D(base_ch*k, 7, padding="same")(start_tensor)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = Conv2D(base_ch*k, 7, padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = Add()([start_tensor, x])
start_tensor = x
return x
# WideResNet
def create_wideresnet(k, N, use_tpu):
input = Input(shape=(32, 32, 3))
# conv1 : 32x32
x = Conv2D(16*k, 1)(input)
x = create_residual_blocks(x, 16, k, N)
# downsampling 32->16
x = AveragePooling2D(2)(x)
x = Conv2D(32*k, 1)(x)
# conv2 : 16x16
x = create_residual_blocks(x, 32, k, N)
# downsampling 16->8
x = AveragePooling2D(2)(x)
x = Conv2D(64*k, 1)(x)
# conv4 : 8x8
x = create_residual_blocks(x, 64, k, N)
x = GlobalAveragePooling2D()(x)
x = Dense(100, activation="softmax")(x)
model = Model(input, x)
model.compile(Adam(), loss="categorical_crossentropy", metrics=["acc"])
if use_tpu:
tpu_grpc_url = "grpc://"+os.environ["COLAB_TPU_ADDR"]
tpu_cluster_resolver = tf.contrib.cluster_resolver.TPUClusterResolver(tpu_grpc_url)
strategy = keras_support.TPUDistributionStrategy(tpu_cluster_resolver)
model = tf.contrib.tpu.keras_to_tpu_model(model, strategy=strategy)
return model
WideResNet
__________________________________________________________________________________________________ Layer (type) Output Shape Param # Connected to ================================================================================================== input_1 (InputLayer) (None, 32, 32, 3) 0 __________________________________________________________________________________________________ ##### # 中略 ##### global_average_pooling2d (Globa (None, 448) 0 add_11[0][0] __________________________________________________________________________________________________ dense (Dense) (None, 100) 44900 global_average_pooling2d[0][0] ================================================================================================== Total params: 103,465,028 Trainable params: 103,452,484 Non-trainable params: 12,544
実験設定
- CIFAR-100をパラメーター103MのWideResNetで分類
- 変える条件はデバイス(GPU,TPU)、バッチサイズ、Validationデータを使うか、DataAugmentationを使うか、データをどこから読ませるか(メモリorストレージ)、並列化するか(worker=1,4)
- DataAugmentationはImageDataGeneratorでできる、ランダムクロップ+水平反転という基本的なもの
- ストレージから読み込む場合は、一度バイナリのCIFARを1枚1枚のpngファイルに書き出し(詳しい方法はこちら参照)、それをImageDataGeneratorのflow_from_directoryで読ませる。DataAugmentationなしでストレージから読み込む場合は、0.0~1.0のスケール変更のみ入れる。
- 20エポック訓練させて、2エポック目以降のエポックあたりの時間の平均を取る
- それ以外のパラメーターはだいたいデフォルト
- GPU:64, 128, 256
- TPU: 64, 128, 256, 1024, 2048, 4096
また、デバイス、バッチサイズ別に以下の8パターンを試します。また、各パターンについて、(Validationデータを使うか, DataAugmentationを使うか, データをストレージから読ませるか)の順でTuple形式で条件を略して表記します。
| パターン | Val | Aug | ストレージ | 表記 | 並列 |
|---|---|---|---|---|---|
| 1 | ☓ | ☓ | ☓ | (F, F, F) | 1 |
| 2 | ○ | ☓ | ☓ | (T, F, F) | 1 |
| 3 | ○ | ○ | ☓ | (T, T, F) | 1 |
| 4 | ☓ | ☓ | ○ | (F, F, T) | 1 |
| 5 | ○ | ☓ | ○ | (T, F, T) | 1 |
| 6 | ○ | ○ | ○ | (T, T, T) | 1 |
| 7 | ☓ | ☓ | ○ | (F, F, T) | 4 |
| 8 | ○ | ○ | ○ | (T, T, T) | 4 |
コードはこちらにあります。https://github.com/koshian2/TPU-Benchmark
サマリー
8パターンのうち最もデバイス、バッチサイズ間の差が大きかったパターン3(T, T, F)を示します。全体の結果はこちら| デバイス | バッチサイズ | 訓練前 | ep.1 | ep.2- 平均 | ep.2- 標準偏差 | 20eps(実測) |
|---|---|---|---|---|---|---|
| gpu | 64 | 0.5 | 1130.8 | 1108.4 | 0.9 | 6:09:52 |
| gpu | 128 | 0.6 | 852.2 | 821.3 | 2.6 | 4:34:17 |
| gpu | 256 | 0.5 | 769.7 | 742.9 | 1.3 | 4:08:05 |
| tpu | 64 | 0.8 | 907.5 | 844.3 | 6.9 | 4:42:30 |
| tpu | 128 | 0.6 | 507.0 | 421.7 | 2.6 | 2:22:00 |
| tpu | 256 | 0.9 | 394.3 | 234.6 | 1.6 | 1:20:52 |
| tpu | 512 | 0.4 | 297.5 | 136.9 | 0.8 | 0:48:19 |
| tpu | 1024 | 0.4 | 247.2 | 80.3 | 0.2 | 0:29:34 |
| tpu | 2048 | 0.8 | 162.2 | 58.1 | 0.8 | 0:21:06 |
| tpu | 4096 | 0.7 | 145.5 | 45.6 | 1.7 | 0:16:52 |
また、GPU・TPUとも1エポック目のみ遅く(TPUは特に顕著)、2エポック目以降はより短い時間で安定的に訓練が進むという傾向があるので、エポック数が多くなれば、全体の訓練時間の比は2エポック目以降のエポックあたりの時間の比に収束します。この「ep.2~平均」で比較すると、同一バッチサイズならTPU-256はGPU-256の3.17倍速く、異なるバッチサイズならTPU-4096はGPU-64の24.33倍速いという結果になりました。
ただ、異なるバッチサイズでの比較を許容するのなら、TPU-64はGPU-256の1.14倍遅いというのも言えるため、必ずしもTPUが対GPUで最速であるということを保証できるものではありません。しかし、トップ差でTPUはGPUの20倍以上速くなるという結果も同様に出ているので、その点はしっかり受け止めるべきではないかと思います。
この時間の差を体感するために、エポック数を変えて訓練した場合の総時間を推定してみました。計算式は「[訓練前]+[ep.1]+[ep.2平均]×([エポック数]-1)」です。実践的に(T, T, T)で並列数1=パターン6での一覧です。
| デバイス | batch | 10 eps | 20(実測) | 50 eps | 100 eps | 200 eps | 500 eps | 1000 eps | 2000 eps |
|---|---|---|---|---|---|---|---|---|---|
| gpu | 64 | 3:10:20 | 6:20:15 | 15:50:02 | 31:39:40 | 63:18:55 | 158:16:41 | 316:32:58 | 633:05:32 |
| gpu | 128 | 2:22:04 | 4:43:50 | 11:49:11 | 23:38:04 | 47:15:52 | 118:09:15 | 236:18:14 | 472:36:11 |
| gpu | 256 | 2:09:58 | 4:19:20 | 10:47:29 | 21:34:23 | 43:08:11 | 107:49:34 | 215:38:34 | 431:16:32 |
| tpu | 64 | 2:14:30 | 4:27:24 | 11:06:07 | 22:10:39 | 44:19:43 | 110:46:54 | 221:32:13 | 443:02:51 |
| tpu | 128 | 1:10:11 | 2:18:33 | 5:43:39 | 11:25:29 | 22:49:10 | 57:00:12 | 113:58:35 | 227:55:21 |
| tpu | 256 | 0:47:12 | 1:27:15 | 3:27:23 | 6:47:35 | 13:28:01 | 33:29:19 | 66:51:29 | 133:35:48 |
| tpu | 512 | 0:30:28 | 0:53:25 | 2:02:16 | 3:57:01 | 7:46:31 | 19:15:03 | 38:22:34 | 76:37:38 |
| tpu | 1024 | 0:20:55 | 0:35:02 | 1:17:23 | 2:27:57 | 4:49:07 | 11:52:36 | 23:38:24 | 47:10:00 |
| tpu | 2048 | 0:13:20 | 0:24:30 | 0:57:59 | 1:53:47 | 3:45:22 | 9:20:10 | 18:38:09 | 37:14:07 |
| tpu | 4096 | 0:12:21 | 0:22:17 | 0:52:06 | 1:41:47 | 3:21:09 | 8:19:15 | 16:36:06 | 33:09:47 |
機械学習自体が反復のプロセスなので、1つのモデルを訓練するのに1ヶ月近くかかるのと2日で終わるのでは、時間あたりの反復回数が全然変わってきます。それはつまりより多くのアイディアを試せることになるので、結果的には時間あたりの生産性を増やしたり、精度を向上できる可能性が大きくなることを意味します。「速さは正義」なのです。
また、最近(2018年9月)にState of the Artを達成したBigGANというモデルによれば、バッチサイズを大きくすることがGANの安定化に寄与するという研究があります。これはGANの場合ですが、バッチサイズを大きくすることによって訓練速度以外のメリットを享受できるという明確な証拠でもあります。一般的にはバッチサイズを変えることはハイパーパラメータをチューニングし直す必要があり、面倒に感じるかもしれませんが、これから新規でモデルを作る場合は、もしメモリの要件が許すのならバッチサイズを大きくして作ったほうがいいのかもしれません。ちなみにこのBigGANはTPUで訓練しているとのことです。
次に細かく条件を分けて見ていきます。
詳細な結果
1.バッチサイズ別
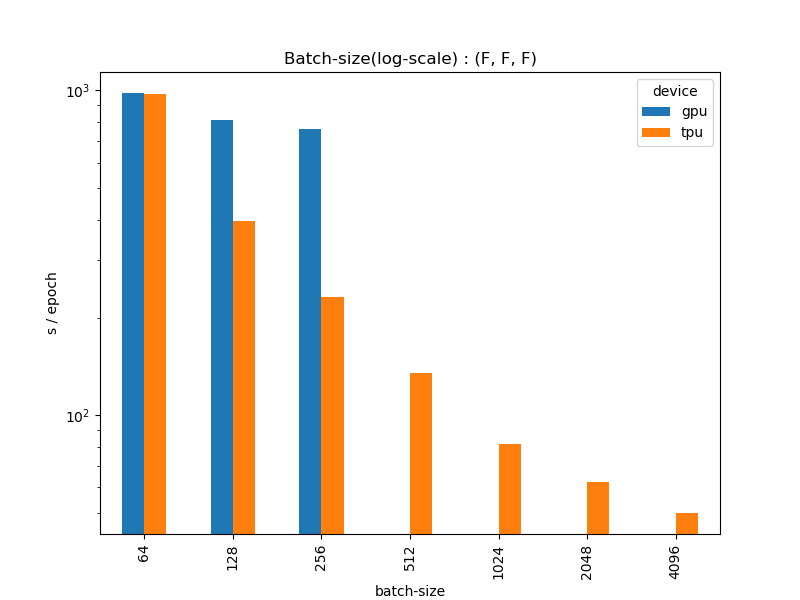
バッチサイズ別の2エポック目以降のエポックあたりの平均秒をグラフで示したものです。(F, F, F)のパターン1で比較しました。バッチサイズを大きくするとTPUは非常に速くなるのは確認の通りです。グラフの縦軸を対数スケールにしてみました。
これを見ると、TPUは対数スケールではほぼ直線的に速くなっているのがわかります。GPUは3ケースなのでなんとも言えませんが、256あたりで頭打ち感が否めません。TPUも4096あたりは若干頭打ちな印象はありますね。
2.Validationの有無
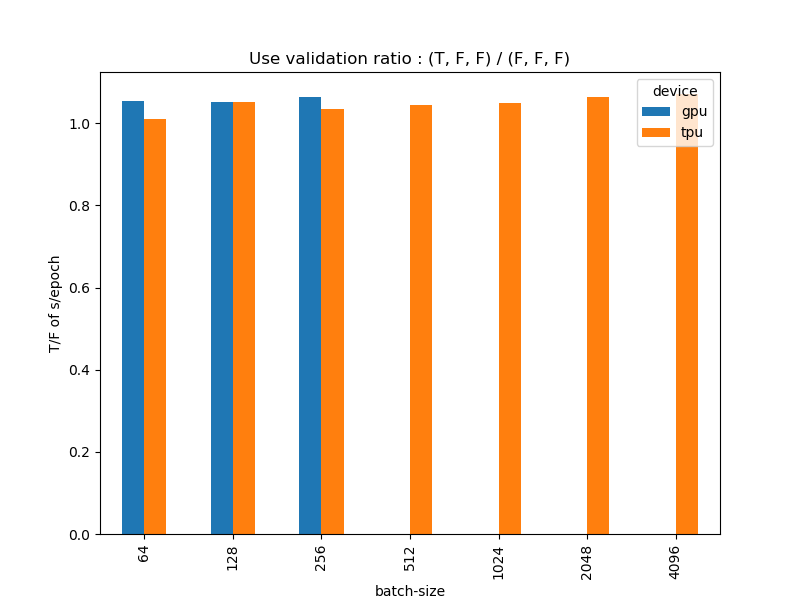
次にエポックの最後にValidationデータを入れることで訓練時間がどの程度変わるかを見ます。CIFAR-100のテストデータをValidationとして入れたため、Validationの有無でデータ数が5万と6万の違いがあります。これは(F, F, F)のパターン1と、(T, F, F)のパターン2を比較したものですが、データ数が1万増えているので、Validationを入れたほうが遅くなるのは当たり前と言えるでしょう。しかし、データ数が1.2倍の割にはそこまで処理時間は増えていないように見えます。(T, F, F)の時間を(F, F, F)の時間で割って、Validationの有無による時間比を求めてみます。
Validationを入れたほうが時間が増えるのはそうだとしても、データ数が1.2倍になっているのに処理時間は1.2倍までなっていませんね。おそらくですがValidationだとBack Propagationを計算しないため速い4のでしょう。Validationのデータ数は訓練データよりもずっと少ないことが多いので、これだったらGPU/TPU問わずどんどんValidationを入れたほうがいいように思えます。モデルのチェックポイント作ったり何かと有用なので。
3.DataAugmentationの有無
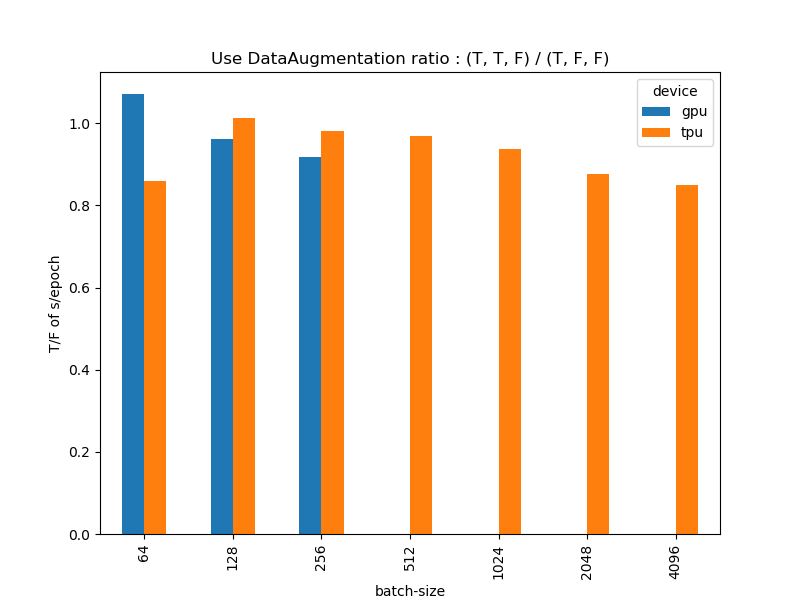
(T, F, F)のパターン2と(T, T, F)のパターン3を比較しました。予想に反してDataAugmentationをしたほうが速くなるという結果が出ました。DataAugmentationをしたパターン(T, T, F)をしなかったパターン(T, F, F)で割ったものが以下のとおりです。DataAugmentationをしたほうが最大で1割近く速くなっているという奇妙な結果となりました。
これには2つ理由が考えられると思います。
- DataAugmentationを用いる際はImageDataGeneratorを使い、model.fitではなくmodel.fit_generatorを使っているためDataAugmentationが速いのではなくfit_generatorが速い(fitが遅い)説
-
fit_generatorではバッチサイズの端数(例えばバッチサイズが4096だったら、4096×12=49152個のサンプルを使い、残りの848個のサンプル)を捨てているため速い説
4.ストレージから読み込むかどうか
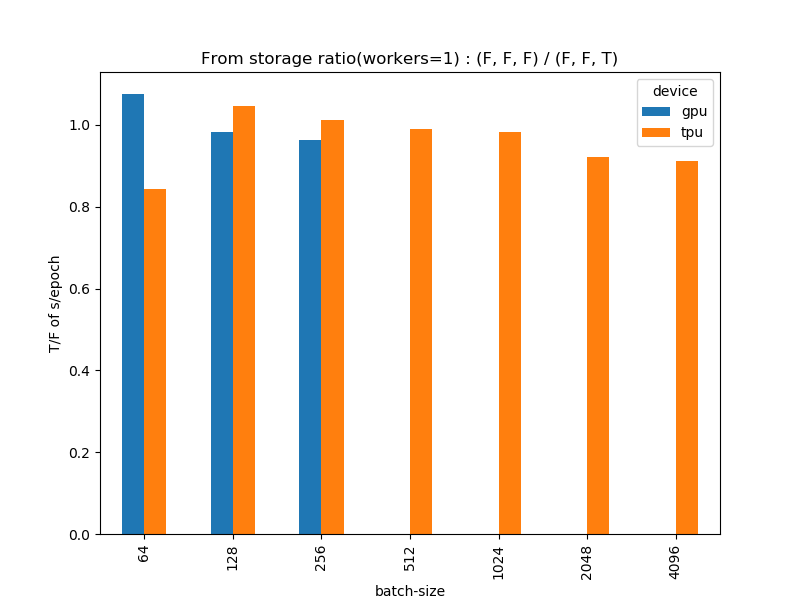
常識的には「メモリから読み込むと速い、ストレージ(HHD,SSD)から読み込むと遅い」ということは考えられますが、ストレージからデータを読み込ませた場合どの程度速度の変化が現れるのでしょうか。(F, F, F)のパターン1と(F, F, T)のパターン4を比較してみます。これも意外な結果になって、「ストレージから読み込ませると速い」という結果になりました。
ただ、よく考えてみると、これもDataAugmentationの場合とほぼ同じで、結局はfitとfit_generatorの差だよなという印象は拭えません。ストレージから読み込む場合は、ImageDataGeneratorのflow_from_directoryを用いました。
本来はUnixBenchを動かしてストレージの読み込み速度を見るべきですが、上手く動かなかったので諦めました。一般的にはストレージの読み込み速度を見ると、シーケンシャルリードがHDDで150MB/s、SSDで500MB/s(あくまで大雑把な目安で物によって全然違う)ぐらいなので、おそらくCIFAR程度だとストレージからの読み込みがボトルネックにならないのかと思います。CIFAR-100の6万枚をpngファイルに書き出してtar.gzで固めたところ126MBでしたので、1周50秒で訓練させたとしてもこのケースではまだまだストレージ側は余裕があるはずです。
5.並列化をするとどうか
自然に考えると「並列化したほうが速い」と思われますがどうでしょうか。並列化をする場合は、model.fit/fit_generatorの「workers=4, use_multiprocessing=True」としました。(T, T, T)で並列数1(パターン6)と並列数4(パターン8)を比較しました。GPU-256の並列数1がすごく遅くなっていますが、多分環境の調子が悪かったのだと思います。これだけ2エポック目以降の時間の標準偏差が他の50倍近くあるので。
これは並列数4の時間を並列数1で割ったものです。この数字が小さくなるほど並列化の効果が出ることになります。GPUやTPUの少ないバッチ数(~1024)ではある程度は並列化の効果はあるものの、TPUでバッチサイズが大きくなったときに並列化すると逆に遅くなるというのが確認できました。
追試:fit vs fit_generator
ここで1つ大きな疑問がわきます。DataAugmentationとストレージのところであった、「実はこれらが高速化に寄与しているのではなくてfit_generatorが速いからでは」という疑問です。そこで次の3つのモードを定義して追試することにしました。- 訓練データ数5万のままfit
- 訓練データ数をバッチサイズの倍数になるように切り詰めてfit(例:バッチサイズ4096なら12×4096=49152とする)
- fit_generatorを使う
| batch/mode | 1 | 2 | 3 | 2÷1 | 3÷1 |
|---|---|---|---|---|---|
| 256 | 219.9 | 221.0 | 219.8 | 1.005 | 0.999 |
| 512 | 131.3 | 131.6 | 128.3 | 1.002 | 0.978 |
| 1024 | 80.1 | 81.6 | 79.7 | 1.018 | 0.995 |
| 2048 | 61.2 | 60.1 | 58.2 | 0.982 | 0.951 |
| 4096 | 50.9 | 48.7 | 46.0 | 0.956 | 0.903 |
これらを見ると、先程の仮説はどちらも正しいということが言えそうです。つまり、
- fitをそのまま使うよりも、バッチサイズの倍数になるようにサンプル数を切り詰めてfitを使ったほうが若干速い
- fit_generatorを使うともっと速くなる
まとめ
とても長くなってしまいましたが、結論をまとめましょう- 1億パラメーターのCNNでColabのTPUvsGPUを比較したところ、異なるバッチサイズ間の比較を許容すればTPUはGPUより20倍以上速くなる(24.33倍)
- 機械学習は反復のプロセスなので「速さは正義」
-
速度を最も決定づけるのがバッチサイズで、バッチサイズを大きくできればTPUは指数関数的に計算性能が強くなる(時間ベースでは対数関数的に減少)。またBigGANではバッチサイズを大きくすることで訓練を安定化しているので、バッチサイズを大きくすることには速度面以外のメリットもあることが確認されている。 - Validationはデータ数が増えるため若干遅く(5万:1万で数%)はなるが、Back Propがないためそこまで遅くならない。入れるのをためらう必要はない。
- model.fitよりも、データ数をバッチサイズの倍数になるようにしてfitさせる、fit_generatorを使うほうが若干高速化する
- DataAugmentationやデータの読み込み元(メモリorストレージ)の条件は、今回の場合TPUのボトルネックとなることはなかった
- 並列化はバッチサイズが大きい場合は逆効果になることもある
最後にKerasの作者のFrançois Cholletさんの言葉で締めくくりたいと思います。
You can start training Keras models on TPUs, from the comfort of your browser, in a few seconds. Try it: https://t.co/G95rxp7U7P「私は、業界規模の大規模な学習ワークフローが今後数年間でGPUからTPUに移行することを期待しています。(Google翻訳による)」とのことです。
I expect that most industry-scale deep learning workflows will move from GPUs to TPUs over the next couple of years. pic.twitter.com/WG63DHbuzD
— François Chollet (@fchollet) 2018年10月4日
コメント
コメントを投稿