Amazon Comprehend カスタムエンティティの利用を開始する
Amazon Comprehend カスタムエンティティの利用を開始する:
プライベートなカスタムエンティティタイプのサポートを可能にする Amazon Comprehend の更新をリリースしました。お客様は、完全に自動で特定の用語を抽出できる、最先端のエンティティ認識モデルのトレーニングをすることができます。機械学習の経験は必要ありません。このサービスにより、お客様は ML の入力と出力を学習しなくても、すでにお持ちのデータを使用してカスタムモデルを作成することができます。お客様はこの機能を使用して、保険証券番号、部品コード、シリアル番号などの組織のニーズに合ったカスタムエンティティを抽出するモデルを簡単に構築できます。
カスタムエンティティタイプを学習するためにサービスをトレーニングすることは、エンティティのセットや、それを含む現実のドキュメントのセットを提供するのと同じくらい簡単です。開始するには、エンティティの一覧をまとめます。製品データベースや、会社が経営計画に使っているエクセルファイルからエンティティを収集します。このブログ記事では、カスタムエンティティタイプをトレーニングして、財務書類から主要な財務用語を抽出します。
CSV 形式では、カラムヘッダとして「Text」と「Type」を必要とします。エンティティとタイプを含む文字列が、作成しようとしているエンティティタイプの名前です。
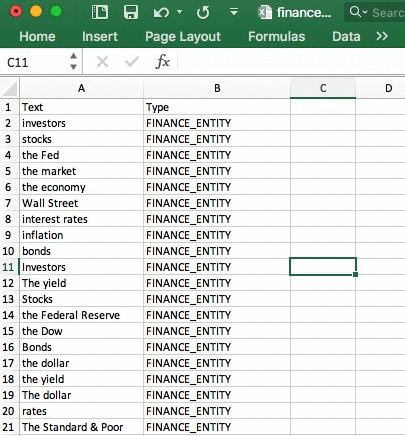
次に、それらのエンティティがどのように使われているかという観点から、エンティティを含むドキュメントのセットを集めます。このサービスでは、一覧のエンティティを少なくとも 1 つ以上含むドキュメントが、最低 1000 は必要です。
次に、1 つのフォルダからエンティティの一覧の CSV を読み込み、別のフォルダからすべてのドキュメントを含むテキストファイル (1 行に 1 つ) を読み込むようにトレーニングジョブを設定します。
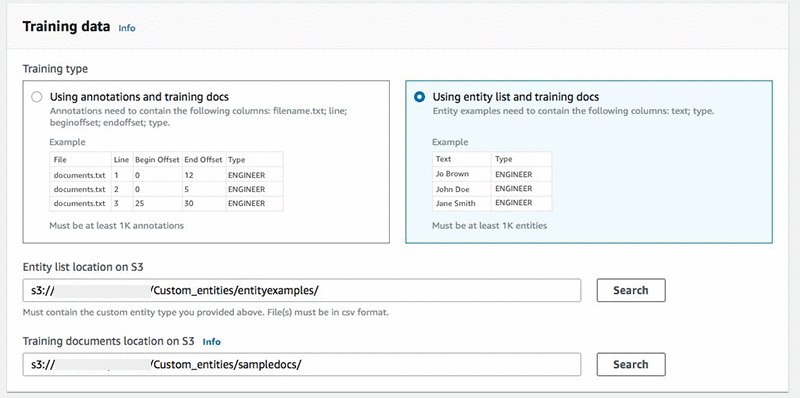
両方のトレーニングデータの準備が整ったら、モデルのトレーニングをします。このプロセスは、トレーニングデータの量や複雑さによって、数分の場合もあれば、数時間かかる場合もあります。Amazon Comprehend では、自動機械学習を使用して、そのデータに最もよく機能する正しい組み合わせを見つけるために、正しいアルゴリズムを選択し、モデルのサンプリングとチューニングを行います。
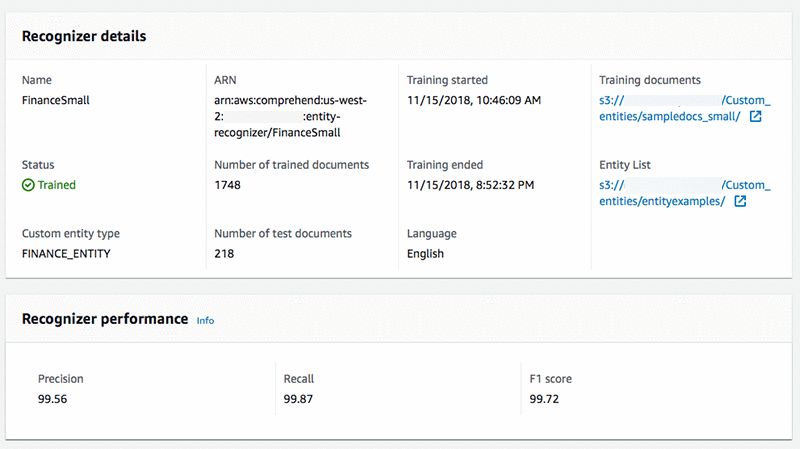
トレーニングが完了するとカスタムモデルの準備が整います。以下に、有益なメタデータと、トレーニングされたモデルを示します。
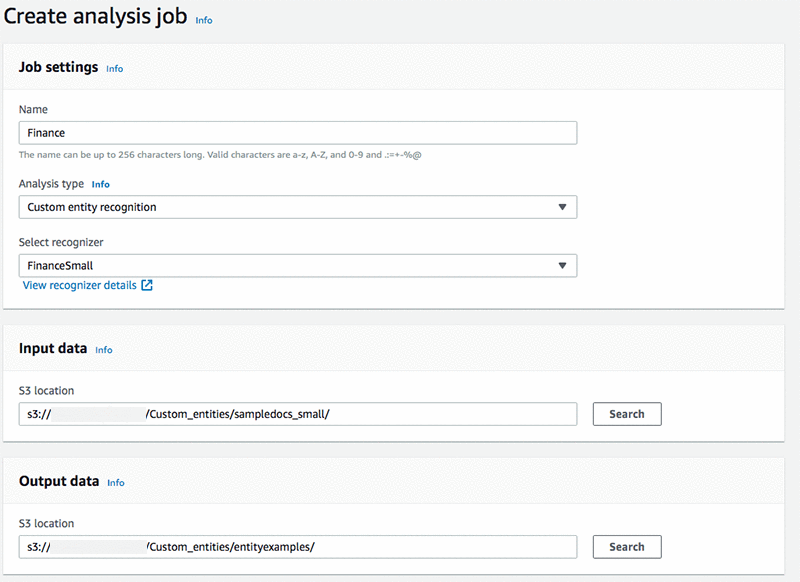
カスタムエンティティを探すドキュメントの分析を開始するには、AWS SDK を使用してポータルまたは API のいずれかを使用します。この例では、カスタムエンティティタイプを使用して財務書類を分析する分析ジョブをポータルに作成します。
CLI を使用した同じジョブ送信がどのようになるかを示します。
JSON レスポンスオブジェクトを開き、ジョブの出力を見て、カスタムエンティティを確認します。このサービスは、それぞれのエンティティに信頼度スコアメトリクスも返します。信頼度スコアが低い場合には、特定のエンティティを含むドキュメントをさらに追加して解決します。
以下では、財務用語が抽出されたカスタムモデルをご覧ください。
製品フォーラムのアクセスして、フィードバックを提供またはヘルプを受けてください。
 Nino Bice は、AWS の自然言語処理サービス Amazon Comprehend の製品をリードするシニアプロダクトマネージャです。
Nino Bice は、AWS の自然言語処理サービス Amazon Comprehend の製品をリードするシニアプロダクトマネージャです。
プライベートなカスタムエンティティタイプのサポートを可能にする Amazon Comprehend の更新をリリースしました。お客様は、完全に自動で特定の用語を抽出できる、最先端のエンティティ認識モデルのトレーニングをすることができます。機械学習の経験は必要ありません。このサービスにより、お客様は ML の入力と出力を学習しなくても、すでにお持ちのデータを使用してカスタムモデルを作成することができます。お客様はこの機能を使用して、保険証券番号、部品コード、シリアル番号などの組織のニーズに合ったカスタムエンティティを抽出するモデルを簡単に構築できます。
カスタムエンティティタイプを学習するためにサービスをトレーニングすることは、エンティティのセットや、それを含む現実のドキュメントのセットを提供するのと同じくらい簡単です。開始するには、エンティティの一覧をまとめます。製品データベースや、会社が経営計画に使っているエクセルファイルからエンティティを収集します。このブログ記事では、カスタムエンティティタイプをトレーニングして、財務書類から主要な財務用語を抽出します。
CSV 形式では、カラムヘッダとして「Text」と「Type」を必要とします。エンティティとタイプを含む文字列が、作成しようとしているエンティティタイプの名前です。
次に、それらのエンティティがどのように使われているかという観点から、エンティティを含むドキュメントのセットを集めます。このサービスでは、一覧のエンティティを少なくとも 1 つ以上含むドキュメントが、最低 1000 は必要です。
次に、1 つのフォルダからエンティティの一覧の CSV を読み込み、別のフォルダからすべてのドキュメントを含むテキストファイル (1 行に 1 つ) を読み込むようにトレーニングジョブを設定します。
両方のトレーニングデータの準備が整ったら、モデルのトレーニングをします。このプロセスは、トレーニングデータの量や複雑さによって、数分の場合もあれば、数時間かかる場合もあります。Amazon Comprehend では、自動機械学習を使用して、そのデータに最もよく機能する正しい組み合わせを見つけるために、正しいアルゴリズムを選択し、モデルのサンプリングとチューニングを行います。
トレーニングが完了するとカスタムモデルの準備が整います。以下に、有益なメタデータと、トレーニングされたモデルを示します。
カスタムエンティティを探すドキュメントの分析を開始するには、AWS SDK を使用してポータルまたは API のいずれかを使用します。この例では、カスタムエンティティタイプを使用して財務書類を分析する分析ジョブをポータルに作成します。
CLI を使用した同じジョブ送信がどのようになるかを示します。
aws comprehend start-entities-detection-job \
--entity-recognizer-arn "arn:aws:comprehend:us-east-1:1234567890:entity-recognizer/person-recognizer“ \
--job-name person-job \
--data-access-role-arn "arn:aws:iam::1234567890:role/service-role/AmazonComprehendServiceRole-role" \
--language-code en \
--input-data-config "S3Uri=s3://data/input/” \
--output-data-config "S3Uri=s3://data/output/“ \
--region us-east-1
以下では、財務用語が抽出されたカスタムモデルをご覧ください。
{
"Entities": [
{
"BeginOffset": 10,
"EndOffset": 16,
"Score": 0.999985933303833,
"Text": "stocks",
"Type": "FINANCE_ENTITY"
},
{
"BeginOffset": 24,
"EndOffset": 36,
"Score": 0.9998899698257446,
"Text": "modest gains",
"Type": "FINANCE_ENTITY"
},
{
"BeginOffset": 55,
"EndOffset": 62,
"Score": 0.9999994039535522,
"Text": "trading",
"Type": "FINANCE_ENTITY"
},
今回のブログ投稿者について
Nino Bice は、AWS の自然言語処理サービス Amazon Comprehend の製品をリードするシニアプロダクトマネージャです。
コメント
コメントを投稿