Oracle データベースを Amazon RDS PostgreSQL または Amazon Aurora PostgreSQL に移行するための成功事例: Oracle および AWS DMS CDC 環境のソースデータベースに関する留意事項
Oracle データベースを Amazon RDS PostgreSQL または Amazon Aurora PostgreSQL に移行するための成功事例: Oracle および AWS DMS CDC 環境のソースデータベースに関する留意事項:
AWS クラウドにおける Oracle から PostgreSQL への移行は、評価段階からカットオーバー段階まで、さまざまな技術とスキルを伴う複雑な多段式のプロセスになる可能性があります。伴う複雑さの内容をさらに詳しく理解するには、AWS データベースのブログ投稿をご参照してください。データベースの移行 – 開始する前に知っておくべきこととは?
このブログの投稿は一連の投稿の 2 回目です。前回の移行プロセスとインフラストラクチャに関する留意事項では、移行プロセスの準備について、そして最適なパフォーマンスを手に入れるためのインフラストラクチャ設定の注意点について説明しています。この 2 回目の記事では、元の Oracle データベースの構成と環境を両方とも 1 回の移行と、 change data capture (CDC) という方法による継続的なレプリケーションで設定する方法について説明しています。ソースデータベースの変更を保存するために Oracle DB コンポーネントを適切に設定することにより、思い通りに AWS Database Migration Service (AWS DMS) のサービス環境を構築することができます。このシリーズの3回目となる最後のブログ記事は、AWS DMS を使用したデータベース移行プロセスのエンドポイントである、ターゲットのPostgreSQLデータベース環境の設定を取り上げます。
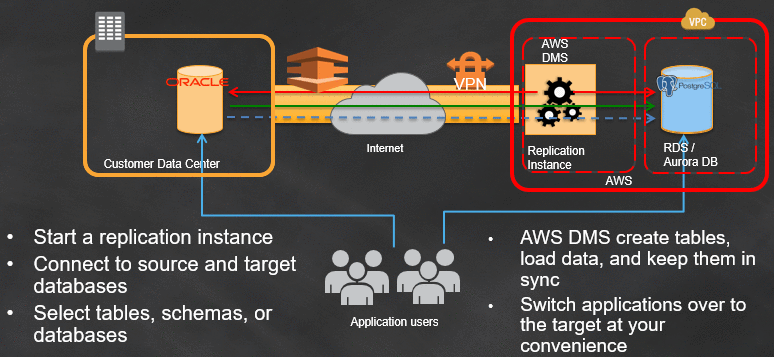
AWS DMSは、Amazon RDSまたはAmazon EC2のデータベースのオンプレミスデータベースを Amazon RDS またはAmazon Auroraデータベースに移行するためのサービスです。Amazon DMS は、 Oracle から Oracle への同機種間の移行や、 AWS クラウドの Oracle から MySQL 、PostgreSQL などの異機種間の移行も処理できます。
DMS の設定は、管理者がAWS 管理コンソールから AWS DMS にアクセスするのと同じくらい簡単です。次に管理者は、データを受信するためにデータをデータベースターゲットに転送するデータベースソースを定義します。
AWS DMS を使用すると、数分でレプリケーションタスクを開始できます。AWS DMS はデータレプリケーションプロセスを監視し、リアルタイムでパフォーマンスのデータを管理者に提示します。サービスが Multi-AZ インスタンスの設定のレプリケーションの最中にネットワークまたはホストの障害を検出すると、自動的に代替のホストが使えるように設定されます。データベースの移行中、AWS DMS はソースデータベースを操作可能な状態に保ちます。移動が中断された場合でもソースは操作可能な状態で、アプリケーションのダウンタイムを最小限に抑えます。
DMS の設定は比較的簡単ですが、始める前に、全ロードと change data capture (CDC) 移行方式の2つの重要な DMS プロセスの働きを理解しておくことをお勧めします。
AWS DMS は、移行を実行するために必要なターゲットスキーマオブジェクトを作成します。しかし、 AWS DMS は必要最小限のアプローチをとり、データを効率的に移行するために必要なオブジェクトのみを作成します。つまり、 AWS DMS はテーブル、プライマリキー、場合によっては一意のインデックスを作成します。ただし、ソースからデータを移行する必要のないオブジェクトは作成されません。たとえば、セカンダリインデックス、非プライマリキーの制約、またはデフォルトとなるデータを作成しません。
あらゆるデータ移行作業は、企業内では重要な仕事です。移行には時間とコストがかかるため、失敗すると非常に手間がかかることがあります。AWS DMS 移行プロジェクトに着手する前に、以下で説明する、全ロードおよび change data capture (CDC) のための、重要な DMS 手順段階のハイレベルな全体像の理解を持ち合わせているかどうか確認します。
外部キーはキャッシュされた変更が適用され進行中のレプリケーションを開始する前のみ、有効になります。したがってこの場合、キャッシュされた変更が適用された後でタスクを停止します。この手順は、バルクロードモードではなく、トランザクションモードでの移行タスクのみ発生します。この場合、変更はすでにソースで取得され DMS によって適用されているため、トリガーを有効にしないでください。トリガーを有効にすると、挿入が繰り返して実行され、つじつまの合わないことが発生します。ただし、ユーザーがトリガーを使用してデータ移行を監査した場合、パフォーマンスに大きな影響を与えることがあります。
AWS DMS CDC プロセスを使用して Oracle を進行中の方法でソースとしてレプリケートする場合、DMS にはログを読み取るためにOracle LogMiner と Oracle Binary Reader という2つの方法があります。Binary Reader の操作については、AWS データベースのブログ記事で説明しています。現在は AWS DMS は、Amazon RDS for Oracle とOracle Standby の Binary Reader をソースとしてサポートするようになりました。
AWS DMS ではデフォルトで、変更データキャプチャー (CDC) 向けの Oracle LogMiner を使用します。別の手段として Binary Reader も使用できます。Binary Reader は LogMiner をバイパスし、ログを直接読み取ります。Binary Reader は LogMiner と比較して大幅に改善されたパフォーマンスを提供し、Oracle サーバーの負荷を軽減します。しかし、非常にアクティブな Oracle データベースが無い限り、Oracle LogMiner を使用して Oracle データベースを移行することをお勧めします。
AWS DMS は Binary Reader を使用して、アーカイブログが生成および格納されるファイルシステムに一時ディレクトリを作成します。ほとんどの場合、これは
Oracle ソースデータベースに AWS DMS をしようする前に、ソース Oracle データベースで次の基本タスクを実行します。
次のコマンドは、データベースが
デフォルトでは、Oracle データベースは補足ロギングを実行せず、補足ロギングを使用しないと LogMiner を使用できません。したがって、LogMiner で分析されるログファイルを生成する前に、必要最小限の補足ログを有効にする必要があります。
次の例では、LogMiner を使用する時に追加の列が必要になるかもしれない状況について説明します。
テーブルにプライマリキーも null ではない一意のインデックスキーもいずれも存在しない場合は、LONG および LOB 以外のすべての列は補足ログに記録されます。これを行うのは、その行の補足ログのために
したがって、データベースレベルのプライマリキーの補足ロギングを使用する場合は、すべてまたはほとんどのテーブルに、プライマリインデックスキーまたは一意のインデックスキーを持つように定義することをお勧めします。これを有効にするには、テーブルごとに次のコマンドを実行します。
一意の列と、redo レコードのフィルタに使用される列の名前を指定する。
データベースレベルのプライマリキー、一意のインデックス、ロギングなどを有効にしたかどうかを確認するには、次のコマンドを実行します。
オンプレミスまたは EC2 Oracle データベースが補足ロギングを有効にしたかどうかを確認する。
SQL ステートメントを作成して、すべてのテーブルのプライマリキーを追加する。
少なくとも 24 時間の時間枠で、十分なアーカイブログファイルを保存することをお勧めします。
さらに、24 時間のバックログを RMAN プロセスで確認します。
これを削除するには、次のコマンドを使用する。
場合によっては、移行タスクの開始後にプライマリキーが存在しない新しいテーブルを作成することがあります。そのような場合は、ソース Oracle エンドポイント接続属性に
Oracle ASM アーキテクチャーでは、DMS セットアップは、変更処理のために Binary Reader を構成するための一時ディレクトリを作成する必要があります。ディスクグループとデータ範囲は別々の ASM インスタンスによって管理されるため、AWS DMS もこのインスタンスに接続する必要があります。さらに、この ASM インスタンスは、DMS レプリケーションインスタンスからのトラフィックも受け入れる必要があります。AWS DMS で、移行に関連するディレクトリを作成します。
Oracle ASM を AWS DMS のソースとして設定するには(詳しくは DMSマニュアルにあります)次の追加接続属性を使用します。これらは ASM での変更処理のために Binary Reader を構成します。
先に述べた属性 を Oracle ASM ソースで同時に使用する場合、テスト接続は成功しても、移行は成功していません。この場合、移行タスクログに次のようなエラーが表示されます。
Oracle ASM ソースの追加接続属性フィールドは、次のとおりです。
さらに、ASM インスタンスで作業する場合、パスワードフィールドには、移行しようとしている Oracle インスタンスのパスワードを指定する必要があります。また、ASM インスタンスに接続するためにパスワードも提供します。フィールド内の 2 つのパスワードはカンマで区切ります。
AWS DMS と同時にOracle ASM ソースの速度を向上させ、移行をもっと安定して行えるようにするには、DMS コピー機能を備えた Binary Reader を使用することをお勧めします。この方法では、DMS はアーカイブされたログを ASM から Oracle サーバー上のローカルディレクトリにコピーします。DMSは Binary Reader を使用してコピーしたログを読み取ることができます。
ここで求められるただ 1 つのことは、ローカルディレクトリが ASM インスタンス上ではなく、基盤となる Linux ファイルシステム上にあるということです。
CDC のスピードを向上させるためのいくつか素早い指針があります:
複数のタスクで同じ一時フォルダを使用している場合 (別のタスクがすでに削除した REDO ログにアクセスする必要があるタスクなどでは) 競合が起こる可能性があります。このような競合を避けるために、DMS タスクは常に 1 つの一時フォルダにアクセスする必要があります。しかし、タスクごとに同じルートフォルダの下に異なるサブフォルダを作成することができます。例えば、両方のタスクの一時フォルダに
一時フォルダで作業する場合は、DMS で処理されるアーカイブされた REDO ログファイルが削除されていることを確認してください。これらを削除すると、REDO ログが一時フォルダに蓄積されなくなります。一時フォルダが作成されるファイルシステムに十分なスペースがあることを確認します。複数のタスクが実行されている場合は、各タスクにその一時フォルダがあるため、タスクの数だけ必要なディスクスペースを増やします。
DMS コピー機能を使用して Binary Reader へのアクセスを指定するには、以下の手順を実行します。
Oracle ソースエンドポイントにおいて指定された Oracle ユーザーが、Oracle ディレクトリを作成したユーザーでない場合は、次の追加の許可が必要です。
さらに以下のものがあります。
以下は別の例です。
ASM 付きの Oracle RAC の場合、ASM サーバーのソースエンドポイントの IP アドレスを正しく設定するようにしてください。移行タスクが接続に失敗するため、サーバーのパブリック IP アドレスと
ASM 付きの Oracle RAC の場合は、次の設定を使用します。
この移行の最終段階に含まれる手順については、このシリーズの最後のブログ記事「PostgreSQL 環境のターゲットデータベースに関する考察」を参照してください。
 Mahesh Pakala は 2014 年 4 月から Amazon で働いています。Amazon に入社する前は、Ingres 、Oracle 社、DELL 社などで働いていました。高度で拡張性の高いアプリケーション、異機種間クラウドアプリケーションの移行を設計し、システムパフォーマンスを支援する看板戦略家として顧客に助言しています。
Mahesh Pakala は 2014 年 4 月から Amazon で働いています。Amazon に入社する前は、Ingres 、Oracle 社、DELL 社などで働いていました。高度で拡張性の高いアプリケーション、異機種間クラウドアプリケーションの移行を設計し、システムパフォーマンスを支援する看板戦略家として顧客に助言しています。
AWS クラウドにおける Oracle から PostgreSQL への移行は、評価段階からカットオーバー段階まで、さまざまな技術とスキルを伴う複雑な多段式のプロセスになる可能性があります。伴う複雑さの内容をさらに詳しく理解するには、AWS データベースのブログ投稿をご参照してください。データベースの移行 – 開始する前に知っておくべきこととは?
このブログの投稿は一連の投稿の 2 回目です。前回の移行プロセスとインフラストラクチャに関する留意事項では、移行プロセスの準備について、そして最適なパフォーマンスを手に入れるためのインフラストラクチャ設定の注意点について説明しています。この 2 回目の記事では、元の Oracle データベースの構成と環境を両方とも 1 回の移行と、 change data capture (CDC) という方法による継続的なレプリケーションで設定する方法について説明しています。ソースデータベースの変更を保存するために Oracle DB コンポーネントを適切に設定することにより、思い通りに AWS Database Migration Service (AWS DMS) のサービス環境を構築することができます。このシリーズの3回目となる最後のブログ記事は、AWS DMS を使用したデータベース移行プロセスのエンドポイントである、ターゲットのPostgreSQLデータベース環境の設定を取り上げます。
AWS DMSは、Amazon RDSまたはAmazon EC2のデータベースのオンプレミスデータベースを Amazon RDS またはAmazon Auroraデータベースに移行するためのサービスです。Amazon DMS は、 Oracle から Oracle への同機種間の移行や、 AWS クラウドの Oracle から MySQL 、PostgreSQL などの異機種間の移行も処理できます。
DMS の設定は、管理者がAWS 管理コンソールから AWS DMS にアクセスするのと同じくらい簡単です。次に管理者は、データを受信するためにデータをデータベースターゲットに転送するデータベースソースを定義します。
AWS DMS を使用すると、数分でレプリケーションタスクを開始できます。AWS DMS はデータレプリケーションプロセスを監視し、リアルタイムでパフォーマンスのデータを管理者に提示します。サービスが Multi-AZ インスタンスの設定のレプリケーションの最中にネットワークまたはホストの障害を検出すると、自動的に代替のホストが使えるように設定されます。データベースの移行中、AWS DMS はソースデータベースを操作可能な状態に保ちます。移動が中断された場合でもソースは操作可能な状態で、アプリケーションのダウンタイムを最小限に抑えます。
DMS の設定は比較的簡単ですが、始める前に、全ロードと change data capture (CDC) 移行方式の2つの重要な DMS プロセスの働きを理解しておくことをお勧めします。
Oracle データベースソース向けの AWS DMS プロセス
AWS DMS は純粋なデータ移行サービスです。双方向データベース複製サービスと間違えないようにしてください。AWS DMS はソースで実行されたすべてのオブジェクトと変更を転送します。インデックスのようなオブジェクトへの変更や修正は移行されません。また、コンフリクトの解決についても対処していません。ただし、列の追加などのデータの移行に必要なスキーマの変更は移行されます。AWS DMS は、移行を実行するために必要なターゲットスキーマオブジェクトを作成します。しかし、 AWS DMS は必要最小限のアプローチをとり、データを効率的に移行するために必要なオブジェクトのみを作成します。つまり、 AWS DMS はテーブル、プライマリキー、場合によっては一意のインデックスを作成します。ただし、ソースからデータを移行する必要のないオブジェクトは作成されません。たとえば、セカンダリインデックス、非プライマリキーの制約、またはデフォルトとなるデータを作成しません。
あらゆるデータ移行作業は、企業内では重要な仕事です。移行には時間とコストがかかるため、失敗すると非常に手間がかかることがあります。AWS DMS 移行プロジェクトに着手する前に、以下で説明する、全ロードおよび change data capture (CDC) のための、重要な DMS 手順段階のハイレベルな全体像の理解を持ち合わせているかどうか確認します。
全ロードのみ
全ロードのみの場合、以下のプロセスが適用されます。- AWS Schema Conversion Tool (AWS SCT) を使用してデータ定義言語 (DDL) に移行する。 つまり、ソースデータベースと同様に、ターゲットデータベースにスキーマを作成します。AWS SCT の詳細については、そのマニュアルを参照にしてください。
- ターゲット内のすべての外部キー制約およびトリガーを削除または無効にする。テーブル DDL を作成し、外部キー制約を無効にするか一時的に削除することで、これを手動で行うことができます。
- この方法で AWS DMS を使用してロードを開始する。
- 移行タイプの場合 – 既存のデータを移行し、進行中の変更を複製する。
- [ターゲットテーブル準備モード] – ターゲットにデータがある場合は切り捨て、ターゲットテーブルにデータが無い場合は何もしない。
- レプリケーションに LOB 列を含める – LOB 列のサイズが 32KB より小さいテーブルに対して、[制限付き LOB モード](デフォルト設定のまま)を使用する。LOB 列のサイズが 32 KB を超えるテーブルの場合は、[制限付き LOB モード](カスタマイズされた設定)を使用する。
- 全ロードが終了したらタスクを停止します – 全ロードが終了したらタスクを停止する。
- ロギングを有効にします。
- ターゲットデータベース内のテーブルのセカンダリオブジェクトを手動で作成する。
- バルクロードでテーブルデータを完全に移行します。これは、たとえば10 憶件のレコードのテーブルの全データを移行する最も効率的な方法です。
- すべてのデータがターゲットに移行され、キャッシュされた変更が適用されるまで、T2 、C4 、または R4 DMS インスタンスでテーブル上で発生した変更を保持およびキャッシュします。たまに DMS インスタンスタイプがパフォーマンスのボトルネックになることがあります。したがって、ふさわしい移行シナリオを配慮してインスタンスタイプを選択することをお勧めします。
- T2 インスタンス:時々パフォーマンスが劇的に高まるため、負荷を軽くできるように設計されています。小規模で断続的なワークロードの移行テストの使用されていることが多いです。
- C4 インスタンス:そのクラスで最高の CPU 性能を備えた計算集約型ワークロードとして設計されています。異機種間の移行やレプリケーション (Oracle から PostgreSQL など) を実行する場合に、CPU を集中的に使用するために主に使用されます。
- R4 インスタンス:メモリ集約型ワークロード用に設計されています。これらのインスタンスには、vCPUあたりのメモリが含まれます。DMS を使用するハイスループットのトランザクションシステムの進行中の移行やレプリケーションでは、時に大量の CPU とメモリを消費することがあります。
- 移行を CDC(進行中のレプリケーション)段階で移行します。移行の全ロードの段階でセカンダリインデックスを追加すると、関連オブジェクトを維持および移行するための追加の間接費が発生します。
CDC による全ロード
- 手順 1 ~ 3 は、先述の全ロードのみの場合と同じ。
- タスクを停止する。(自動的に実行する手順は次のとおりです。)
- すべてのセカンダリオブジェクトを追加し、外部キー制約を有効にする。
- タスクを再開して変更をキャッシュする。
StopTaskCachedChangesApplied– 全ロードが完了しキャッシュされた変更が適用された後にタスクを停止するには、このオプションを [true] に設定する。StopTaskCachedChangesNotApplied– このオプションを [true] に設定すると、キャッシュされた変更が適用される前にタスクが停止する。
外部キーはキャッシュされた変更が適用され進行中のレプリケーションを開始する前のみ、有効になります。したがってこの場合、キャッシュされた変更が適用された後でタスクを停止します。この手順は、バルクロードモードではなく、トランザクションモードでの移行タスクのみ発生します。この場合、変更はすでにソースで取得され DMS によって適用されているため、トリガーを有効にしないでください。トリガーを有効にすると、挿入が繰り返して実行され、つじつまの合わないことが発生します。ただし、ユーザーがトリガーを使用してデータ移行を監査した場合、パフォーマンスに大きな影響を与えることがあります。
AWS DMS CDC プロセスを使用して Oracle を進行中の方法でソースとしてレプリケートする場合、DMS にはログを読み取るためにOracle LogMiner と Oracle Binary Reader という2つの方法があります。Binary Reader の操作については、AWS データベースのブログ記事で説明しています。現在は AWS DMS は、Amazon RDS for Oracle とOracle Standby の Binary Reader をソースとしてサポートするようになりました。
AWS DMS ではデフォルトで、変更データキャプチャー (CDC) 向けの Oracle LogMiner を使用します。別の手段として Binary Reader も使用できます。Binary Reader は LogMiner をバイパスし、ログを直接読み取ります。Binary Reader は LogMiner と比較して大幅に改善されたパフォーマンスを提供し、Oracle サーバーの負荷を軽減します。しかし、非常にアクティブな Oracle データベースが無い限り、Oracle LogMiner を使用して Oracle データベースを移行することをお勧めします。
AWS DMS は Binary Reader を使用して、アーカイブログが生成および格納されるファイルシステムに一時ディレクトリを作成します。ほとんどの場合、これは
USE_DB_RECOVERY_FILE_DEST が示すディレクトリの場所になります。移行タスクが停止した後で、このディレクトリは削除されます。Oracle ソースデータベースに AWS DMS をしようする前に、ソース Oracle データベースで次の基本タスクを実行します。
- Oracle DMS ユーザー権限の設定を行う – AWS DMS ユーザーになるために、Oracle ユーザーアカウントを提示する必要があります。ユーザーアカウントには Oracle データベースに対する読み取りと書き込み権限が必要です。次の点に注意してください。
- 権限を付与する場合は、オブジェクトの同義語 (例えば、アンダースコア無しで
V$OBJECT) ではなく、オブジェクトの実際の名前 (例えば、アンダースコアを含めたV_$OBJECT) を使用します。DMS ユーザーが得られるアクセス権限の情報は、DMS マニュアルにあるAWS DMS ソースとしての Oracle データベースの使用を参照してください。 - また、DMS サービスを使うためにログインする IAM ユーザーに、ログを表示するために必要なすべての権限があることを確認します。これらの許可の詳細については、DMS のマニュアルにあるAWS DMS を使用するために必要な IAM 権限を参照してください。
- 権限を付与する場合は、オブジェクトの同義語 (例えば、アンダースコア無しで
- アーカイブログを有効にする – AWS DMS で Oracle を使用するには、ソースデータベースが
ARCHIVELOGモードである必要があります。 - 補足ログを有効にする – 全ロードに加えて CDC タスクを使用する予定なら、レプリケーションの変更をキャプチャするために補足ログを設定します。
オンプレミスの Oracle ソース
オンプレミスの Oracle ソースを使用する場合は、次の点に注意してください。アーカイブログモードを有効にする
Oracle データベースはNOARCHIVELOG モードまたは ARCHIVELOGのいずれかで実行できます。デフォルトでは、データベースは NOARCHIVELOGモードで作成されます。ARCHIVELOG モードでは、データベースはすべての ONLINE REDO ログがいっぱいになるとそのコピーを作成します。アーカイブされた REDO ログのこうしたコピーは、Oracle ARCH プロセスを使用して作成されます。ARCH プロセスは、アーカイブされた REDO ログファイルを複数のアーカイブログの送信先ディレクトリにコピーします。次のコマンドは、データベースが
ARCHIVELOG モードで動作するように変更されているかどうかを確認します。SQL> select log_mode from v$database;
LOG_MODE
------------
NOARCHIVELOG
SQL> shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
SQL> alter database archivelog;
SQL> startup nomount;
ORACLE instance started.
SQL> alter database mount;
Database altered.
SQL> alter database archivelog;
Database altered.
SQL> alter database open;
Database altered.
SQL> archive log list;
Database log mode Archive Mode
Automatic archival Enabled
sql> select log_mode from v$database
ARCHIVELOG
補足ログを有効にする
REDO ログファイルは、インスタンスリカバリーおよびメディアリカバリーに使用されます。こうした操作に必要なデータは、REDO ログファイルに自動的に記録されます。ただし、やり直しに基づくアプリケーションでは、追加の列が REDO ログファイルに記録される必要があります。追加の列をロギングするプロセスは補足ロギングと呼ばれます。デフォルトでは、Oracle データベースは補足ロギングを実行せず、補足ロギングを使用しないと LogMiner を使用できません。したがって、LogMiner で分析されるログファイルを生成する前に、必要最小限の補足ログを有効にする必要があります。
次の例では、LogMiner を使用する時に追加の列が必要になるかもしれない状況について説明します。
- 再構成された SQL ステートメントを別のデータベースに適用するアプリケーションでは、行を一意に識別する列のセットによって更新されたステートメント (例えばプライマリキー) を特定する必要があります。こうしたアプリケーションは、
V$LOGMNR_CONTENTSによって戻された再構成された SQL に表示されたROWIDでこれを識別できません。この結果は、あるデータベースのROWID値が別のデータベースのROWID値と異なるため意味がありません。 - アプリケーションでは、行の変更の追跡がもっと効率的になるように、修正された列だけでなく、行全体の前のイメージをログに記録する必要があります。
- 無制限の補足ロググループ – 指定された列の以前の画像は、更新が指定された列に影響を与えたかどうかに関係なく、行が更新されるたびにログに記録されます。このタイプのグループは、ALWAYS ロググループと呼ばれることもあります。
- 制限付き補足ロググループ – 指定されたすべての列の以前の画像は、ロググループ内の少なくとも 1 つの列が更新された場合にのみログに記録されます。
- データベースレベルの補足ロギング – このタイプのロギングを使用すると、LogMiner にクラスタ化されたテーブルやインデックス構成されたテーブルなどの多様なテーブル構造をサポートするための最小限の情報が入手できます。含まれるコマンドは
ALTER DATABASE ADD SUPPLEMENTAL LOG DATAです。 - 移行される各テーブルのテーブルレベルの補足ロギング – プライマリキーを持つデータベース内のすべてのテーブルについて、次のコマンドを使用します。
このコマンドは、テーブルのプライマリキーに基づいて、システムにより生成された無制限の補足ロググループを作成します。ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;
テーブルにプライマリキーも null ではない一意のインデックスキーもいずれも存在しない場合は、LONG および LOB 以外のすべての列は補足ログに記録されます。これを行うのは、その行の補足ログのために
ALL を指定するのと同じです。したがって、データベースレベルのプライマリキーの補足ロギングを使用する場合は、すべてまたはほとんどのテーブルに、プライマリインデックスキーまたは一意のインデックスキーを持つように定義することをお勧めします。これを有効にするには、テーブルごとに次のコマンドを実行します。
ALTER TABLE table_name ADD SUPPLEMENTAL LOG DATA (primary key) COLUMNSALTER DATABASE ADD SUPPLEMENTAL LOG DATA (…) COLUMNS;ALTER TABLE table_name ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (FOREIGN KEY) COLUMNS;ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (UNIQUE) COLUMNS;
データベースレベルのプライマリキー、一意のインデックス、ロギングなどを有効にしたかどうかを確認するには、次のコマンドを実行します。
SQL> SELECT
SUPPLEMENTAL_LOG_DATA_MIN,
SUPPLEMENTAL_LOG_DATA_PK,
SUPPLEMENTAL_LOG_DATA_UI,
SUPPLEMENTAL_LOG_DATA_FK,
SUPPLEMENTAL_LOG_DATA_ALL
FROM
v$database;
SQL>SELECT table_name FROM all_tables A WHERE table_name NOT IN ( SELECT table_name FROM all_constraints
WHERE constraint_type ='P' ) AND a.owner = 'AWS'; (change the AWS to your schema name)SQL>SELECT supplemental_log_data_min FROM v$database; (need to be yes or implicit)SQL>select 'alter table '||owner||'.'||table_name||' add SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;' SUP_LOG_CHK
from dba_tables where owner = 'HR';
SUP_LOG_CHK
=====================================================
alter table HR.DEPT add SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;
alter table HR.EMP add SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;
alter table HR.BONUS add SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;
alter table HR.SALGRADE add SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;
4 rows selected.
exec rdsadmin.rdsadmin_util.set_configuration('archivelog retention hours',24);CONFIGURE ARCHIVELOG DELETION POLICY TO BACKED UP 1 TIMES TO DISK;
CONFIGURE RMAN OUTPUT TO KEEP FOR 1 DAYS;
CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF 1 DAYS;Oracle ソースのための Amazon RDS
ソースとして Amazon RDS for Oracle を使用する場合は、最初に Amazon RDS for Oracle インスタンスの自動バックアップを有効にしてください。exec rdsadmin.rdsadmin_util.alter_supplemental_logging('ADD');
exec rdsadmin.rdsadmin_util.alter_supplemental_logging('ADD','PRIMARY KEY');
SQL> exec rdsadmin.rdsadmin_util.alter_supplemental_logging('DROP','ALL');
PL/SQL procedure successfully completed.
SQL>SELECT table_name FROM all_tables A WHERE table_name NOT IN ( SELECT table_name FROM all_constraints WHERE constraint_type ='P' ) AND a.owner = 'AWS'; (change the AWS to your schema name)
ALTER TABLE TABLE_NAME ADD SUPPLEMENTAL LOG DATA (ALL) COLUMNS;
または
ALTER TABLE MAS_STYLE_COLOR ADD SUPPLEMENTAL LOG GROUP example_log_group (MMAT_MATERIAL_NO) ALWAYS;addSupplementalLogging=Yを追加することをお勧めします。これは DMS がテーブル内の変更されたすべての列を取得することを意味します。この追加には、テーブルの変更権限と、テーブルを変更する排他的ロックが必要です。addSupplementalLogging=Yをテーブルの変更の権限無しに有効にすると、DMSはエラーを返します。ただ、プライマリキーを使用してテーブルを作成しこれを行うと、DMS はエラーを返しませんが、それは DMS はそのテーブルのすべての列に対して補足ログを追加しないためです。addSupplementalLogging=Yを有効にするにはソーステーブルに排他的ロックが必要なため、手動で有効にすることをお勧めします。CDC モード付の RDS Oracle
RDS Oracle ソースへの移行を CDC モードで実行するには、次の前提条件が必要です。- Oracle Binary Reader のリリース 2.4.2R1 以降を使用する。
- Oracle バージョン 11.2.0.4.v11 以降、または 12.1.0.2.v7 以降を使用する。これを行う時には、ORCL デフォルト名を使用して RDS Oracle インスタンスを作成する。そうしないと、次の手順は正常に実行されません。
- 必要なリンボリックリンクされたサーバーディレクトリを作成するには、次の手順を実行する。この手順の詳細については、DMS ドキュメントのトランザクションログへのアクセスを参照にしてください。
exec rdsadmin.rdsadmin_master_util.create_archivelog_dir; exec rdsadmin.rdsadmin_master_util.create_onlinelog_dir; - Binary Reader 方式を用いる予定なら、RDS Oracle の event condition action (ECA) に従って使用してください。ひとつのライン上に続くすべてのオプションを入力します。
useLogMinerReader=N;useBfile=Y;accessAlternateDirectly=false;useAlternateFolderForOnline=true;oraclePathPrefix=/rdsdbdata/db/ORCL_A/;usePathPrefix=/rdsdbdata/log/;replacePathPrefix=true - データベースレベルにて、プライマリキーのための補足ログを作成する。
SQL> exec rdsadmin.rdsadmin_util.alter_supplemental_logging('ADD'); PL/SQL procedure successfully completed. SQL> exec rdsadmin.rdsadmin_util.alter_supplemental_logging('ADD','PRIMARY KEY'); PL/SQL procedure successfully completed. - DMS タスクのアーカイブログを少なくとも 24 時間保持する。
以下のコマンドを実行して RDS Oracle を手動で切り替えるexec rdsadmin.rdsadmin_util.set_configuration('archivelog retention hours',24);
Oracle ASM からのデータ移行
Oracle 自動ストレージ管理 (ASM) データベースフレームワークは、Oracle データベースファイル用のボリュームマネージャーとファイルシステムを提供します。これはシングルインスタンスの Oracle データベースと Oracle Real Application Clusters (Oracle RAC) の設定をサポートします。ASM には、データベースの中にファイルシステムとボリュームを直接管理するツールがあります。ASM からの移行の内容は、AWS データベースブログの記事 AWS DMS を使用した Oracle ASM から AWS への移行方法を参照してください。Oracle ASM アーキテクチャーでは、DMS セットアップは、変更処理のために Binary Reader を構成するための一時ディレクトリを作成する必要があります。ディスクグループとデータ範囲は別々の ASM インスタンスによって管理されるため、AWS DMS もこのインスタンスに接続する必要があります。さらに、この ASM インスタンスは、DMS レプリケーションインスタンスからのトラフィックも受け入れる必要があります。AWS DMS で、移行に関連するディレクトリを作成します。
Oracle ASM を AWS DMS のソースとして設定するには(詳しくは DMSマニュアルにあります)次の追加接続属性を使用します。これらは ASM での変更処理のために Binary Reader を構成します。
useLogMinerReader=N;useBfile=Y00031609: 2017-12-05T22:21:05 [SOURCE_CAPTURE ]E: OCI error 'ORA-12162: TNS:net service name is incorrectly specified' [122307] OCI error.(oradcdc_redoutil.c:362)
00031609: 2017-12-05T22:21:05 [SOURCE_CAPTURE ]E: Cannot attach OCI server [120414] Failed to connect to database.(oradcdc_redoutil.c:363)
00031609: 2017-12-05T22:21:05 [SOURCE_CAPTURE ]E: Cannot connect to server ''(user '', thread 1) [120414] Failed to connect to database.(oradcdc_io.c:380)
useLogMinerReader=N;useBfile=Y;asm_user=<asm_username>;asm_server=<server_address>/+ASMserver_addressの値は、関連するエンドポイントを作成する場合にサーバー名に提供した値と同じです。さらに、ASM インスタンスで作業する場合、パスワードフィールドには、移行しようとしている Oracle インスタンスのパスワードを指定する必要があります。また、ASM インスタンスに接続するためにパスワードも提供します。フィールド内の 2 つのパスワードはカンマで区切ります。
my_oracle_pw,my_asm_pwCDC 処理速度
ASM 環境では、REDO ログへのアクセスが遅いことがよくあります。この遅い処理速度は、原因となる API 操作が 1 回の呼び出しで最大 32 KB までのブロックしか読み取れないことから起こります。さらに、進行中のレプリケーションで LogMiner を使用して AWS DMS と同時に ASM を設定すると、パフォーマンスが低下して大幅な遅延が生じる可能性があります。接続に問題がある場合や、ソースインスタンスがダウンした場合、移行が正常に復元できないことがあります。AWS DMS と同時にOracle ASM ソースの速度を向上させ、移行をもっと安定して行えるようにするには、DMS コピー機能を備えた Binary Reader を使用することをお勧めします。この方法では、DMS はアーカイブされたログを ASM から Oracle サーバー上のローカルディレクトリにコピーします。DMSは Binary Reader を使用してコピーしたログを読み取ることができます。
ここで求められるただ 1 つのことは、ローカルディレクトリが ASM インスタンス上ではなく、基盤となる Linux ファイルシステム上にあるということです。
CDC のスピードを向上させるためのいくつか素早い指針があります:
- テーブルの DDL またはプライマリキーに
タグなどの別の単語を使用しないこと。 - 更新または削除、バルクモードでの実行、およびパフォーマンス向上のために、PostgreSQL ターゲットにプライマリキーが必要です。
- 最初にソートキーとプライマリキーを使用してテーブルを作成しておき、その後テーブル作成モードとして切り捨てる、または何もしないことをお勧めします。ソートキーは、クエリのパターンに応じて合成したり、または交互配置できます。
- 分散キーは偶数またはキーでなければならず、
ALLにすることはできません。 - パフォーマンスを向上させるには ‘
BatchApplyPreserveTransactionを false に設定します。
Oracle RAC 付きの DMS 、DMS のコピー、そして ASM の設定
Oracle データベースは、一時フォルダからの書き込み、そして削除が可能である必要があります。Oracle ソースデータベースが RAC クラスターの場合、一時フォルダは Oracle Server RAC 内のすべてのノードからアクセス可能なファイル共有に配置する必要があります。一時フォルダにアクセスするために Binary Reader 方式を選択した場合、そのフォルダは共有ネットワークフォルダである必要はありません。複数のタスクで同じ一時フォルダを使用している場合 (別のタスクがすでに削除した REDO ログにアクセスする必要があるタスクなどでは) 競合が起こる可能性があります。このような競合を避けるために、DMS タスクは常に 1 つの一時フォルダにアクセスする必要があります。しかし、タスクごとに同じルートフォルダの下に異なるサブフォルダを作成することができます。例えば、両方のタスクの一時フォルダに
/mnt/dms を指定する代わりに、あるタスクに対しては/temp/dms/task1 とを指定し、もう一方に対しては、/temp/dms/task2 を指定できます。一時フォルダで作業する場合は、DMS で処理されるアーカイブされた REDO ログファイルが削除されていることを確認してください。これらを削除すると、REDO ログが一時フォルダに蓄積されなくなります。一時フォルダが作成されるファイルシステムに十分なスペースがあることを確認します。複数のタスクが実行されている場合は、各タスクにその一時フォルダがあるため、タスクの数だけ必要なディスクスペースを増やします。
DMS コピー機能を使用して Binary Reader へのアクセスを指定するには、以下の手順を実行します。
- Oracle サーバー上の一時フォルダを選択します。ソースが Oracle RAC である場合、すべての RAC のノードは前述のようにフォルダにアクセスする必要があります。そのフォルダは Oracle ユーザーと Oracle グループ (例えば DBA など) が読み取り、書き込み、削除を行うための許可が必要です。
- DMS が Oracle に接続するために使用するユーザーに、次の許可を与えます。以下に記載されている最後の許可は、アーカイブされた REDO ログを
COPY_FILE方式を使用して一時フォルダにコピーできるようにします。
CREATE SESSION SELECT ON v_$transportable_platform EXECUTE ON DBMS_FILE_TRANSFER - AWS DMS で Oracle ディレクトリを作成および管理するには、次の権限を付与する必要があります。先に述べたようにAWS DMS は、REDO ログを一時フォルダにコピーし、一時フォルダから削除するために、ディレクトリオブジェクトを使用する必要があります。次の権限を付与すると、AWS DMS は
DMSREP_プレフィックスを持つ Oracle ディレクトリを作成します。この権限を付与しない場合は、対応するディレクトリを手動で作成する必要があります。ディレクトリは、アーカイブされた REDO ログと一時フォルダのパスを指定している必要があります。ディレクトリを手動で作成する場合は、DMSREP_プレフィックスをディレクトリ名に追加する必要はありません。
CREATE ANY DIRECTORY
- Oracle ソースエンドポイントを作成する場合に、指定された DMS ユーザーがOracle ディレクトリを作成したユーザーでない場合は、次の追加の許可を与えます.(以下がその例です)
- ソースディレクトリとして指定された Oracle ディレクトリオブジェクトで
READ (読み取り)する。(つまり、もし BFILE 方式を使用して一時フォルダから読み取る場合なら、ASM アーカイブされた REDO ログパスと一時フォルダです。) - コピープロセス (つまり、一時フォルダ) で送信先ディレクトリとして指定されたディレクトリオブジェクトに
WRITE (書き込み)します。
GRANT READ, WRITE ON DIRECTORY bfile_dir TO userName; GRANT SELECT ON DBA_FILE_GROUPS to DMS_user; GRANT EXECUTE ON SYS.DBMS_FILE_GROUP to DMS_user; EXECUTE DBMS_FILE_GROUP.GRANT_SYSTEM_PRIVILEGE (DBMS_FILE_GROUP.MANAGE_ANY_FILE_GROUP, 'DMS_user', FALSE);
- ソースディレクトリとして指定された Oracle ディレクトリオブジェクトで
- 古い REDO ログが一時フォルダに蓄積されないようにするには、処理した後に一時フォルダから REDO ログファイルを削除するように AWS DMS を設定する必要があります。削除操作は、Oracle ファイルグループと Oracle
DBMS_FILE_GROUPパッケージを使用して実行されます。 - ASM からのオンライン REDO ログ (つまり
SYSASMまたはSYSADMの権限です) を読み取るために、AWS DMS は必要な ASM アクセスの許可を得ていることを確認してください。ASM からのオンライン REDO ログの読み取りは Oracle DBMS_DISKGROUP パッケージの機能を使用して実行されるため、この許可が必要です。これを行うには、SYSASM または SYSADM の権限が必要です。コマンドプロンプトウィンドウを開き、以下のステートメントを発行することで、ASM アカウントへのアクセスを有効にすることもできます。
Oracle 11g リリース 2 (11.2.0.2) 以降は、ASM アカウントにアクセスするには、AWS DMS ユーザーにsqlplus asmuser/asmpassword@+asmserver as sysasm ------------または----------------------------- sqlplus asmuser/asmpassword@+asmserver as sysdbaSYSASMの権限が付与されている必要があります。サポートされているより古いバージョンの場合は、SYSDBA権限を与えれば十分です。 - アーカイブされた REDO ログの送信先識別子 を選択します。この番号はレプリケーションで読み取るアーカイブ REDO ログの送信先 ID です。その値は、 DEST_ID number in v$archived_logと同じにする必要があります。次にソースエンドポイントに次の属性を追加します。
ここでarchivedLogDestId=nnnnは DMS 内の接続文字列の送信先 ID です。 - 追加の接続属性フィールドが次のようになるように Oracle ASM ソースエンドポイントを設定します。
以下に例を示します。useLogMinerReader=N;copyToTempFolder=/dms_temp;archivedLogDestId=nn;accessTempFolderDirectly=N;useBfile=Y;asm_user=asmuser;asm_server=asmserver.company.com/+asmserver;deleteProccessedArchiveLogs=Y
useLogMinerReader=N;copyToTempFolder=/backups/dms;archivedLogDestId=1;accessTempFolderDirectly=N;useBfile=Y;asm_user=pakalam;asm_server=10.81.7.81/+ASM;deleteProccessedArchiveLogs=Y;archivedLogsOnly=Y
READ ON DIRECTORYの権限を与えます。Oracle ソースエンドポイントにおいて指定された Oracle ユーザーが、Oracle ディレクトリを作成したユーザーでない場合は、次の追加の許可が必要です。
- ソースディレクトリ (つまり BFILE 方式を使用して一時フォルダから読み取る場合は、ASM アーカイブ REDO ログのパスと一時フォルダ) として指定された Oracle ディレクトリオブジェクトに対して
READ (読み取り)を実行します。 - コピー処理 (つまり、一時フォルダ) でコピー先ディレクトリとして指定されたディレクトリオブジェクトに対して
WRITE (書き込み)を実行します。
GRANT READ, WRITE to DIRECTORY bfiledir to user;
GRANT SELECT ON DBA_FILE_GROUPS to dms_user;
GRANT EXECUTE on SYS.DBMS_FILE_GROUP to dms_user;EXECUTE DBMS_FILE_GROUP.GRANT_SYSTEM_PRIVILEGE with the system privilege 'MANAGE_ANY_FILE_GROUP' for the RI user.
execute DBMS_FILE_GROUP.GRANT_SYSTEM_PRIVILEGE (DBMS_FILE_GROUP.MANAGE_ANY_FILE_GROUP, 'dms_user', FALSE);asm_server の内部 IP アドレスを使用するとエラーメッセージが表示されます。ASM 付きの Oracle RAC の場合は、次の設定を使用します。
- 以下の接続属性を使用します。
useLogminerReader=N;asm_user=<asm_username e.g. sysadm>;asm_server=<first_RAC_server_ip_address>/<ASM service name e.g. +ASM or +APX> - 次のようにカンマで区切ったパスワードをフィールドを使用します。
your_oracle_user_pw, your_asm_user_pw - ASM 以外のセットアップで RDS Oracle Binary Reader モードを使用する場合は、次の追加接続属性を使用します。
useLogMinerReader=N; useBfile=Y;accessAlternateDirectly=false; useAlternateFolderForOnline=true; oraclePathPrefix=/rdsdbdata/db/ORCL_A/;usePathPrefix=/rdsdbdata/log/; replacePathPrefix=true
additionalArchivedLogDestid=2‘) のサポートを始めました。[useLogminerReader=Y;useBfile=N;]archivedLogsOnly=Y;archivedLogDestId=1;additionalArchivedLogDestId=2 まとめ
このブログ記事では、PostgreSQL 環境への移行のためにソース Oracle データベースを設定およびセットアップするために必要な移行手順について説明しています。この移行構築プロセスの部分を通じて、AWS Database Migration Service (AWS DMS) と AWS Schema Conversion Tool (AWS SCT) を使用します。この移行の最終段階に含まれる手順については、このシリーズの最後のブログ記事「PostgreSQL 環境のターゲットデータベースに関する考察」を参照してください。
謝辞
このブログは Silvia Doomra、Melanie Henry、Wendy Neu、Eran Schitzer、 Mitchell Gurspan、 Ilia Gilderman、 Kevin Jernigan、 Jim Mlodgenski、 Chris Brownlee、 Ed Murray そしてMichael Russo らの徹底的で粘り強いレビューとフィードバック無しには執筆は不可能でした。著者について
Mahesh Pakala は 2014 年 4 月から Amazon で働いています。Amazon に入社する前は、Ingres 、Oracle 社、DELL 社などで働いていました。高度で拡張性の高いアプリケーション、異機種間クラウドアプリケーションの移行を設計し、システムパフォーマンスを支援する看板戦略家として顧客に助言しています。
コメント
コメントを投稿