AWS での Apache Kafka の実行のためのベストプラクティス
AWS での Apache Kafka の実行のためのベストプラクティス:
この記事は Intuit とのパートナーシップに基づいて書かれ、AWS で Apache Kafka クラスタを実行するための学習、ベストプラクティス、推奨事項を共有するものです。Intuit の Vaishak Suresh と同氏の同僚の方々の貢献とサポートに感謝いたします。
Intuit の概要: Intuitは、AWS のエンタープライズ顧客のリーダーであり、ビジネスと財務管理ソリューションのクリエーターです。Intuit の AWS とのパートナーシップに関する詳細については、以前のブログ記事 Real-time Stream Processing Using Apache Spark Streaming and Apache Kafka on AWSを参照してください。Apache Kafka はリアルタイムのストリーミングアプリケーションを構築することを可能にする、オープンソースの分散型ストリーミング プラットフォームです。
この記事に記載されているベストプラクティスは、2年以上にわたり、AWS で大規模な Kafka クラスタを実行し運営する当社の経験に基づいています。この記事では、AWS で Kafka を現在実行している AWS 顧客を支援し、また AWS にオンプレミスの Kafka 展開を移行することを考えている顧客も支援することを目的としています。
AWS は完全に管理対象となっている Kafka のオルタナティブである Amazon Kinesis Data Streams を提供します。
Amazon EC2 で Kafka の展開を実行すると、ストリーミングデータの取り込みのための高性能でスケーラブルなソリューションを提供します。AWS は多くの異なるインスタンスタイプとストレージオプションの組み合わせを Kafka デプロイに提供しています。しかし、可能性のあるデプロイトポロジーの数を考えると、ユースケースに対して必ずしも最も適切な戦略を選択することは、必ずしも常に自明であるわけではありません。
このブログ記事では、AWS でのKafka クラスタの実行について、以下の面を取り上げます。
このパターンでは、これは Kafka クラスタデプロイです。
Kafka クラスタのパッチングとアップグレードのために再起動が必要です。このアプローチで、ローリングアップグレードが各クラスタに対して個別に行われます。

このパターンでは、これは Kafka クラスタデプロイです。
Intuit はブローカーを 3 つの AZ (単一リージョン、3 つの AZ) に分散させて、単一の Kafka クラスタを 1 つの AWS リージョンで使用することを推奨しています。このアプローチは、障害のある AZ は Kafka のダウンタイムを発生させないため、このアプローチ以外の場合よりも強力な耐障害性を提供します。
エフェメラルストレージは、Amazon EC2 インスタンスにローカルです。インスタンスタイプに基づいた高い IOPS を提供できます。一方で、Amazon EBS ボリュームは高い柔軟性を提供し、ストレージのニーズに基づいて、IOPS を構成できます。EBS ボリュームはまた、回復時間の観点でいくらかの明確な優位性も示します。ストレージの選択は、Kafka クラスタによりサポートされるワークロードのタイプに密接に関係しています。
Kafka は構成可能な数のインスタンスにわたり、データ区画をレプリケーションすることで、耐障害性を組み込みます。ブローカーに障害が発生すると、他のレプリカをホストするクラスタの他のブローカーからすべてのデータをフェッチすることにより回復できます。データ転送のサイズに応じて、回復プロセスとネットワークトラフィックに影響することができます。これらは、代わりに最終的に、クラスタのパフォーマンスに影響します。
以下の表はストレージの EBS を使用することに対して、インスタンスストアを使用する利点を対照して示します。
EBS の頻繁なインスタンスの再スタック要件と EBS により提供されるその他の利点のために、Intuit は EBS を選択しました。
一般的に、Kafka のデプロイメントでは、3 つのレプリケーション要素が使用されます。EBS はサービス内でレプリケーションを提供するため、Intuit は 3 つの代わりに 2 つのレプリケーション要素を選択します。
Intuit は Kafka クラスタに対して ST1 (処理量最適化 HDD) EBSと共に、ブローカーに対しては r3.xlarge インスタンスを使用し、ZooKeeper には r3.large を使用します。
Intuit のテストからサンプルのベンチマークの数値は、以下のとおりです。
EBS ストレージが必要な場合、AWS には新しい世代の r4 インスタンスがあります。r4 インスタンスは、多くの点で R3 よりも優れています。
クラスタで高い読み/書きトラフィックが予想される場合、10 Gb/秒のパフォーマンスを提供するインスタンスタイプを選択してください。
さらに、ブローカー間ネットワークトラフィックをプライベートサブネット上に維持するオプションを選択してください。このアプローチにより、クライアントはブローカーに接続できるようになります。ブローカーとクライアントの間のコミュニケーションでは、同じネットワークインターフェイスとポートを使用します。詳細については、EC2 インスタンスの IP アドレス指定に関するドキュメントを参照してください。
複数の AWS リージョンをデプロイしている場合、クロスリージョン VPC ピアリングを使用して、2 つの AWS リージョンの 2 つの VPC を接続できます。しかし、クロス AZ デプロイメントに関係するネットワーキングコストに注意してください。
別の Kafka クラスタを作成してアップグレードする余裕がある場合は、ブルー/グリーンアップグレードシナリオを強くお勧めします。このシナリオでは、最新の Kafka バージョンでクラスタを最新のものに維持するようにお勧めします。Kafka バージョンのアップグレードとその他の詳細については、Kafka アップグレードのドキュメントを参照してください。
以下の図は、ブルー/グリーンアップグレードを示します。
このシナリオで、アップグレードプランは、次のようになります。
これらは、いくつかのパフォーマンス調整テクニックです。
モニタリングのために、Intuit はいくつかのツールを使用しました。それには、Newrelec、Wavefront、Amazon CloudWatch、およびAWS CloudTrailが含まれます。推奨されるモニタリングアプローチは、以下のとおりです。
システムメトリクスの場合、以下をモニタリングすることをお勧めします。
Kafka は Kerberos 認証をサポートします。すでに Kerberos サーバーがある場合、現在の構成に Kafka を追加できます。
インスタンスストレージに基づいて Kafka クラスタをバックアップするための最良の方法は、MirrorMaker を使用して、2 番目のクラスタをセットアップし、メッセージをレプリケーションすることです。Kafka のミラーリング機能が、既存の Kafka クラスタのレプリカを維持することを可能にします。セットアップと要件に応じて、バックアップクラスタはメインクラスタまたは異なるものとして、同じ AWS リージョンにある場合があります。
EBS ベースのデプロイメントの場合、ボリュームをバックアップするためにEBS ボリュームの自動スナップショットを有効にできます。リストアするこれらのスナップショットから新しい EBS ボリュームを容易に作成できます。Amazon S3 にバックアップファイルを保存することをお勧めします。
Kafka でバックアップする方法については、Kafka のドキュメントを参照してください。
ご質問またはご提案については、以下でコメントを残してください。


Prasad Alle は、AWS プロフェッショナルサービスのシニアビッグデータコンサルタントです。AWS エンタープライズおよび戦略的顧客のために、スケーラブルで信頼性の高いビッグデータ、機械学習、人工知能、IoT ソリューションをリードおよび構築するのに尽力しています。関心のあるテクノロジーは、先進的なエッジコンピューティング、エッジでの機械学習等、多岐にわたります。余暇の楽しみは家族と過ごすこと。
この記事は Intuit とのパートナーシップに基づいて書かれ、AWS で Apache Kafka クラスタを実行するための学習、ベストプラクティス、推奨事項を共有するものです。Intuit の Vaishak Suresh と同氏の同僚の方々の貢献とサポートに感謝いたします。
Intuit の概要: Intuitは、AWS のエンタープライズ顧客のリーダーであり、ビジネスと財務管理ソリューションのクリエーターです。Intuit の AWS とのパートナーシップに関する詳細については、以前のブログ記事 Real-time Stream Processing Using Apache Spark Streaming and Apache Kafka on AWSを参照してください。Apache Kafka はリアルタイムのストリーミングアプリケーションを構築することを可能にする、オープンソースの分散型ストリーミング プラットフォームです。
この記事に記載されているベストプラクティスは、2年以上にわたり、AWS で大規模な Kafka クラスタを実行し運営する当社の経験に基づいています。この記事では、AWS で Kafka を現在実行している AWS 顧客を支援し、また AWS にオンプレミスの Kafka 展開を移行することを考えている顧客も支援することを目的としています。
AWS は完全に管理対象となっている Kafka のオルタナティブである Amazon Kinesis Data Streams を提供します。
Amazon EC2 で Kafka の展開を実行すると、ストリーミングデータの取り込みのための高性能でスケーラブルなソリューションを提供します。AWS は多くの異なるインスタンスタイプとストレージオプションの組み合わせを Kafka デプロイに提供しています。しかし、可能性のあるデプロイトポロジーの数を考えると、ユースケースに対して必ずしも最も適切な戦略を選択することは、必ずしも常に自明であるわけではありません。
このブログ記事では、AWS でのKafka クラスタの実行について、以下の面を取り上げます。
- デプロイの考察とパターン
- ストレージオプション
- インスタンスタイプ
- ネットワーキング
- アップグレード
- パフォーマンス調整
- モニタリング
- セキュリティ
- バックアップとリストア
デプロイの考察とパターン
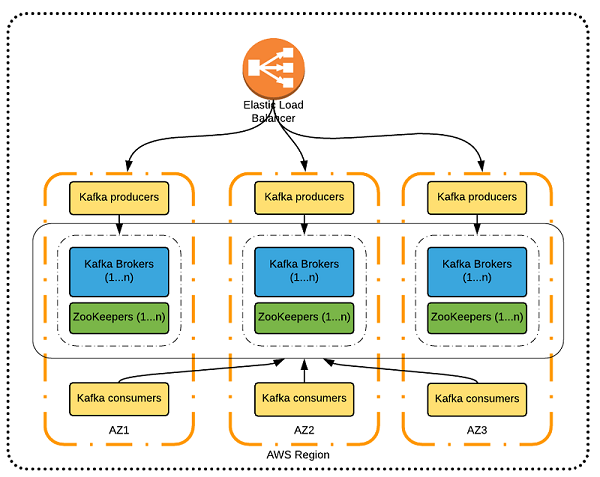
このセクションでは、AWS の Kafka に対して使用できるさまざまなデプロイオプションについて、その長所と短所に沿って話し合います。デプロイの成功はこれらのオプションを思慮深く考察することから始まります。デプロイの可用性、整合性、運用上のオーバーヘッドの考察は、正しいオプションを選択するときに役立ちます。単一の AWS リージョン、3 つのアベイラビリティゾーン、すべてアクティブ
1 つの代表的なデプロイパターン (すべてアクティブ) は、3 つのアベイラビリティゾーン (AZ) をもつ単一の AWS リージョンにあります。1 つの Kafka クラスタが、以下の図で示されているように、Apache Zoo Keeper と Kafka プロデューサー、およびコンシューマーインスタンスと共に各 AZ でデプロイされます。このパターンでは、これは Kafka クラスタデプロイです。
- Kafka プロデューサーと Kafka クラスタは、各 AZ でデプロイされます。
- データは、Elastic Load Balancer を使用して、 3 つの Kafka クラスタにわたり均等に分配されます。
- Kafka コンシューマーは、3 つすべての Kafka クラスタからデータを集計します。
- すべての Kafka プロデュサーをマークダウンします
- コンシューマーを停止します
- Kafka をデバッグしてリスタックします
- コンシューマーを再起動します
- Kafka プロデュサーを再起動します
| 長所 | 短所 |
|
|
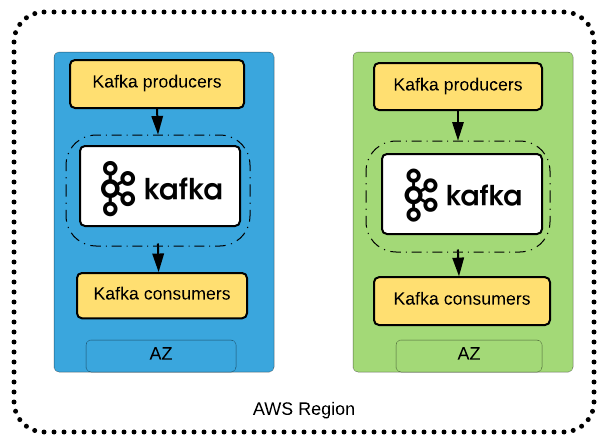
単一のリージョン、3 つのアベイラビリティゾーン、アクティブスタンバイ
別の代表的なデプロイメントパターン (アクティブ‐スタンバイ) は、単一の Kafka クラスタと Kafka ブローカー、および 3 つの AZ にわたって分配される Zookeepers をもつ単一の AWS リージョンにあります。別の動揺の Kafka クラスタは、以下の図で示されているように、スタンバイとして動作します。MirrorMaker による Kafka ミラーリングを使用して、2 個のクラスタ間でメッセージをレプリケーションできます。このパターンでは、これは Kafka クラスタデプロイです。
- Kafka プロデュサーは、3 つすべての AZ に展開されます。
- 1 つの Kafka クラスタのみが 3 つの AZ (アクティブ) にデプロイされます。
- ZooKeeper インスタンスは、各 AZ にデプロイされます。
- ブローカーは、3 つすべての AZ に均等に広げられます。
- Kafka コンシューマーは、3 つすべての AZ にわたってデプロイできます。
- スタンバイ Kafka プロデューサーとマルチ-AZ Kafka クラスタは、デプロイメントの一部です。
- トラフィックをスタンバイ Kafka プロデューサークラスタと Kafka クラスタに切り替えます。
- スタンバイ Kafka クラスタから消費するために、コンシューマーを再起動します。
| 長所 | 短所 |
|
|
ストレージオプション
Amazon EC2 のファイルストレージには、2 つのストレージオプションがあります。エフェメラルストレージは、Amazon EC2 インスタンスにローカルです。インスタンスタイプに基づいた高い IOPS を提供できます。一方で、Amazon EBS ボリュームは高い柔軟性を提供し、ストレージのニーズに基づいて、IOPS を構成できます。EBS ボリュームはまた、回復時間の観点でいくらかの明確な優位性も示します。ストレージの選択は、Kafka クラスタによりサポートされるワークロードのタイプに密接に関係しています。
Kafka は構成可能な数のインスタンスにわたり、データ区画をレプリケーションすることで、耐障害性を組み込みます。ブローカーに障害が発生すると、他のレプリカをホストするクラスタの他のブローカーからすべてのデータをフェッチすることにより回復できます。データ転送のサイズに応じて、回復プロセスとネットワークトラフィックに影響することができます。これらは、代わりに最終的に、クラスタのパフォーマンスに影響します。
以下の表はストレージの EBS を使用することに対して、インスタンスストアを使用する利点を対照して示します。
| インスタンスストア | EBS |
|
|
一般的に、Kafka のデプロイメントでは、3 つのレプリケーション要素が使用されます。EBS はサービス内でレプリケーションを提供するため、Intuit は 3 つの代わりに 2 つのレプリケーション要素を選択します。
インスタンスタイプ
インスタンスタイプの選択は一般的に、Kafka クラスタのストリーミングアプリケーションに必要なストレージのタイプにより導かれます。アプリケーションではエフェメラルストレージが必要な場合、 h1、i3、および d2 インスタンスが最良のオプションです。Intuit は Kafka クラスタに対して ST1 (処理量最適化 HDD) EBSと共に、ブローカーに対しては r3.xlarge インスタンスを使用し、ZooKeeper には r3.large を使用します。
Intuit のテストからサンプルのベンチマークの数値は、以下のとおりです。
| 設定 | ブローカーバイト (MB/s) |
|
集計 346.9 |
- 高速プロセッサー (Broadwell) があります。
- EBS はデフォルトで最適化されています。
- 小規模のサイズで最高 10 Gbps の Elastic Network Adapter (ENA) に基づいたネットワーキングを特長としています。
- R3 よりも 20 パーセントコストが安い
ネットワーキング
ネットワークは Kafka のような分散システムで最も重要な役割を果たします。高速で信頼性のあるネットワークにより、ノードが互いに容易にコミュニケーションできるように保証します。使用可能なネットワークのスループットは、Kafka が扱えるトラフィックの最大量をコントロールします。ネットワークスループットは、ディスクストレージと組み合わせられ、クラスタのサイジングを管理する要素となることがよくあります。クラスタで高い読み/書きトラフィックが予想される場合、10 Gb/秒のパフォーマンスを提供するインスタンスタイプを選択してください。
さらに、ブローカー間ネットワークトラフィックをプライベートサブネット上に維持するオプションを選択してください。このアプローチにより、クライアントはブローカーに接続できるようになります。ブローカーとクライアントの間のコミュニケーションでは、同じネットワークインターフェイスとポートを使用します。詳細については、EC2 インスタンスの IP アドレス指定に関するドキュメントを参照してください。
複数の AWS リージョンをデプロイしている場合、クロスリージョン VPC ピアリングを使用して、2 つの AWS リージョンの 2 つの VPC を接続できます。しかし、クロス AZ デプロイメントに関係するネットワーキングコストに注意してください。
アップグレード
Kafkaは下位互換ではない履歴がありますが、そのかい互換のサポートは改善しています。Kafka アップグレード中に、プロデューサーとコンシューマーのクライアントをアップグレードしている元のバージョンと同じか低いバージョンに維持していなければなりません。アップグレードが終了した後で、新しいプロトコルバージョンとそれがサポートする新しい機能を使い始めることができます。以下で話し合うように、3 つのアップグレードアプローチが選択可能です。ローリングアップグレードまたはその場でのアップグレード
ローリングアップグレードまたはその場でのアップグレードのシナリオで、1 回に 1 つの Kafka ブローカーをアップグレードします。エンドユーザーのダウンタイムを避けるために、ローリングアップグレードが再開するための推奨事項を考慮にいれてください。ダウンタイムアップグレード
ダウンタイムを受け入れる余裕がある場合は、クラスタ全体をダウンし、各 Kafka ブローカーをアップグレードしてから、クラスターを再開します。ブルー/グリーンアップグレード
Intuit は以下に記載されているとおり、ワークロードに対するブルー/グリーンデプロイメントモデルに従います。別の Kafka クラスタを作成してアップグレードする余裕がある場合は、ブルー/グリーンアップグレードシナリオを強くお勧めします。このシナリオでは、最新の Kafka バージョンでクラスタを最新のものに維持するようにお勧めします。Kafka バージョンのアップグレードとその他の詳細については、Kafka アップグレードのドキュメントを参照してください。
以下の図は、ブルー/グリーンアップグレードを示します。
このシナリオで、アップグレードプランは、次のようになります。
- AWS で新しい Kafka クラスタを作成します。
- 新しい Kafka プロデューサースタックを作成して、新しい Kafka クラスタをポイントします。
- 新しい Kafka クラスタのトピックを作成します。
- グリーンのデプロイメントを端から端までテストします (サニティチェック)。
- Amazon Route 53 を使用して、AWS の新しい Kafka プロデューサーを作成した新しいグリーンの Kafka 環境をポイントするように変更します。
- Amazon Route 53 を AWS の古い Kafka プロデューサースタックに切り替えて、古い Kafka 環境をポイントするようにします。
パフォーマンス調整
多次元で Kafka パフォーマンスを微調整できます。以下はパフォーマンス調整に対するいくつかのベストプラクティスです。これらは、いくつかのパフォーマンス調整テクニックです。
- スループットがネットワーク容量に達しない場合は、次を試してください。
- もっと多くのスレッドを追加する
- バッチサイズを大きくする
- プロデューサーインスタンスを追加する
- 区画を追加する
- acks =-1の時にレイテンシーを改善するには、num.replica.fetches 値を増やします。
- クロス AZ データ転送の場合、ソケットと OS TCP のバッファ設定を調整してください。
- num.io.threads が Kafka に専用のデスクの数よりも多いことを確信してください。
- プロデューサーの数にコンシューマーの数とレプリケーション係数を加えたものに基づいて、num.network.threads を調整してください。
- メッセージサイズは、ネットワークの帯域幅に影響します。Kafka クラスタからより高いパフォーマンスを得るためには、10 Gb/秒 のパフォーマンスを提供するインスタンスタイプを選択します。
- Oracle JDK を使用することで GC の一時停止を最小化し、新しい G1 garbage-first コレクターを使用します。
- Kafka ヒープサイズを 4 GB 未満に維持するように試みます。
モニタリング
Kafka クラスタが本番環境で正しく動作することを知ることは重要です。時には、クラスタが稼働していることを知るだけで充分ですが、Kafka アプリケーションにはモニタリングする多くの可動部分があります。実際に、監視することが重要なものと、脇においておくことができるものを理解することは、すぐに混乱してしまう場合があります。モニタリングするアイテムは、トラフィックの全体的なレートに関する単純なメトリクスから、プロデューサー、コンシューマー、コントローラー、ZooKeeper、トピック、区画、メッセージなどの範囲に及びます。モニタリングのために、Intuit はいくつかのツールを使用しました。それには、Newrelec、Wavefront、Amazon CloudWatch、およびAWS CloudTrailが含まれます。推奨されるモニタリングアプローチは、以下のとおりです。
システムメトリクスの場合、以下をモニタリングすることをお勧めします。
- CPU ロード
- ネットワークメトリクス
- ファイルハンドル使用量
- ディスクスペース
- ディスク I/O パフォーマンス
- Garbage collection
- ZooKeeper
- Batch-size-avg
- Compression-rate-avg
- Waiting-threads
- Buffer-available-bytes
- Record-queue-time-max
- Record-send-rate
- Records-per-request-avg
- Batch-size-avg
- Compression-rate-avg
- Waiting-threads
- Buffer-available-bytes
- Record-queue-time-max
- Record-send-rate
- Records-per-request-avg
セキュリティ
ほとんどの分散型システムと同様、Kafka は比較的高いセキュリティでデータを関係するコンポーネントにわたって転送するメカニズムを備えています。セットアップに応じて、セキュリティには、ブローカーと ZooKeeper における暗号化、Kerberos、Transport Layer Security (TLS) 証明書、高度なアクセスコントロールリスト (ACL) のセットアップなどを含みます。以下は、Intuit アプローチに関して示します。このセクションで取り上げられていない Kafka セキュリティの詳細については、Kafka ドキュメント を参照してください。安心の暗号化
EBS に支えられた EC2 インスタンスの場合は、暗号化を有効にした Amazon EBS ボリュームを使用することで、安心の暗号化を有効にできます。Amazon EBS は暗号化のために、AWS Key Management Service (AWS KMS) を使用します。詳細については、EBS ドキュメントの Amazon EBS Encryption を参照にしてください。インスタンスストア に支えられた EC2 インスタンスの場合は、Amazon EC2 インスタンスストア暗号化を使用することで、安心の暗号化を有効にできます。移動中の暗号化
Kafka はクライアントとインターモード通信のために、TLS を使用します。認証
クライアント(プロデューサーおよびコンシューマー)から他のブローカーおよびツールへのブローカ^への接続の認証は、Secure Sockets Layer(SSL)またはSimple Authentication and Security Layer(SASL)のいずれかを使用します。Kafka は Kerberos 認証をサポートします。すでに Kerberos サーバーがある場合、現在の構成に Kafka を追加できます。
認証
Kafka では、認証はプラグ式で外部認証サービスとのインテグレーションがサポートされています。バックアップとリストア
デプロイメントで使用されるストレージのタイプは、バックアップとリストア戦略を指示します。インスタンスストレージに基づいて Kafka クラスタをバックアップするための最良の方法は、MirrorMaker を使用して、2 番目のクラスタをセットアップし、メッセージをレプリケーションすることです。Kafka のミラーリング機能が、既存の Kafka クラスタのレプリカを維持することを可能にします。セットアップと要件に応じて、バックアップクラスタはメインクラスタまたは異なるものとして、同じ AWS リージョンにある場合があります。
EBS ベースのデプロイメントの場合、ボリュームをバックアップするためにEBS ボリュームの自動スナップショットを有効にできます。リストアするこれらのスナップショットから新しい EBS ボリュームを容易に作成できます。Amazon S3 にバックアップファイルを保存することをお勧めします。
Kafka でバックアップする方法については、Kafka のドキュメントを参照してください。
結論
この記事では、AWS Cloud で実行中の Kafka のいくつかのパターンについて取り上げました。AWS はまた、Amazon Kinesis Data Streams で代替のマネージドソリューションも提供し、管理するサーバーまたは心配するスケーリングクリフはなく、ダウンタイムなしで数秒でストリーミングパイプラインのサイズを測定でき、アベイラビリティゾーンにわたるデータレプリケーションは自動で行われ、すぐに使用できるセキュリティがあり、Kinesis データストリームは Lambda、Redshift、Elasticsearch などの多様な AWS のサービスに密接に組み込まれ、Storm、Spark、Flink などのオープンソースフレームワークをサポートします。kafka-kinesis コネクターを参照してください。ご質問またはご提案については、以下でコメントを残してください。
その他の参考資料
この記事が役に立つと思われる場合は、Implement Serverless Log Analytics Using Amazon Kinesis Analytics と Real-time Clickstream Anomaly Detection with Amazon Kinesis Analytics を併せてお読みください。著者について
Prasad Alle は、AWS プロフェッショナルサービスのシニアビッグデータコンサルタントです。AWS エンタープライズおよび戦略的顧客のために、スケーラブルで信頼性の高いビッグデータ、機械学習、人工知能、IoT ソリューションをリードおよび構築するのに尽力しています。関心のあるテクノロジーは、先進的なエッジコンピューティング、エッジでの機械学習等、多岐にわたります。余暇の楽しみは家族と過ごすこと。
コメント
コメントを投稿