最新 – Amazon Comprehend でカスタム文書分類子をトレーニングする
最新 – Amazon Comprehend でカスタム文書分類子をトレーニングする:
Amazon Comprehend は自然言語のテキストを大量に処理するパワーをもたらします (詳しくは、入門的な内容を記した、私の投稿記事、Amazon Comprehend – Continuously Trained Natural Language Processing をご覧ください)。2017 年に英語およびスペイン語のサポートとともに立ち上げて以来、私たちはお客様のニーズに基づいた機能を追加してきました。たとえば、非同期バッチオペレーション、構文分析、多言語サポート (フランス語、ドイツ語、イタリア語、ポルトガル語)、リージョンの追加などが挙げられます。
自動機械学習 (AutoML) を使用することで、Comprehend は ML の入力と出力を学習する必要のない、お客様が既にお持ちのデータを使用したカスタム自然言語処理 (NLP) モデルの作成を実現します。お客様のデータセットとユースケースに基づき、適切なアルゴリズムを自動的に選択して、パラメータ、ビルドのチューニング、および結果モデルのテストを行います。
タグ付き文書のコレクションを既にお持ちであれば (サポートチケット、Amazon Transcribe 経由、フォーラムの投稿などといったコールセンターの会話)、開始点としてこれらをご使用いただけます。この場合、タグ付きとは単に、各文書が検証済みであり、望ましい方法で特徴づけるラベルが割り当てられていることを意味します。カスタム分類には少なくともラベルごとに 50 件の文書が必要ですが、数百または数千件の文書があれば特徴づけの精度が上がります。
この記事では主にカスタム分類について取り上げ、適切なテキストから不適切な表現を含むテキストを分離するモデルのトレーニング方法をご紹介します。続いて、新しいテキストを分類するモデルの使用方法をご紹介します。
分類子の使用
開始点となるのは次の様なトレーニングテキストの CSV ファイルです (ここでは画像を加工していますが、不適切な言葉が多数含まれています)。
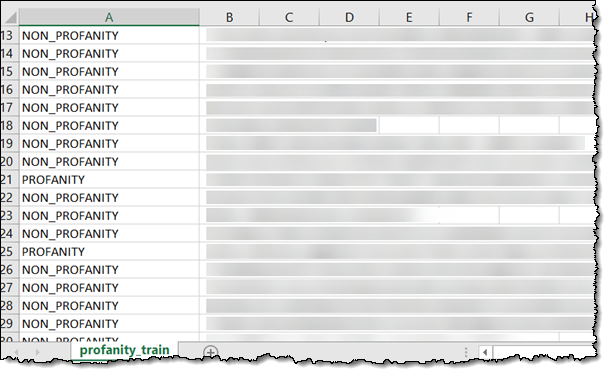
トレーニングデータは S3 オブジェクト内に常駐している必要があり、また、1 行につきラベルと文書を 1 つづつ指定します。
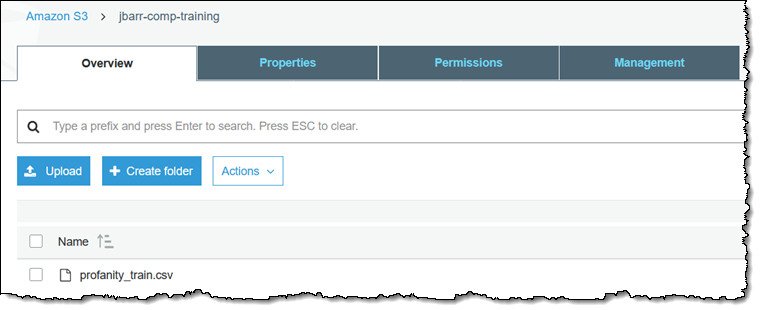
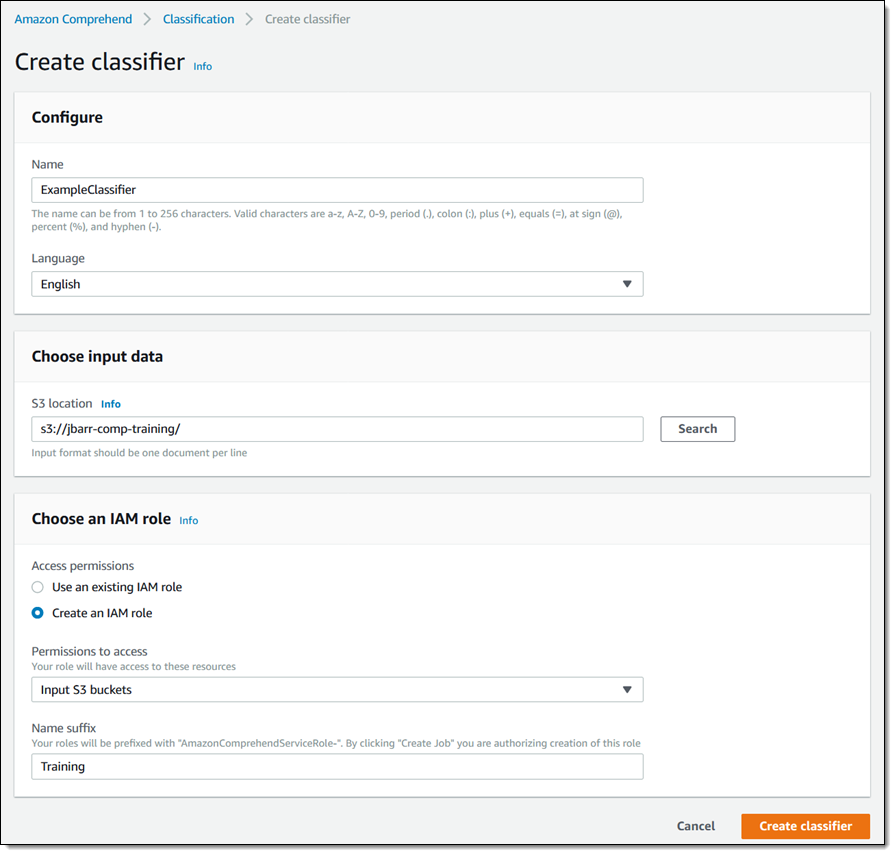
次に、Amazon Comprehend コンソールへ移動し、[Classification] (分類)をクリックします。私は既存の分類子を持っていないので、[Create classifier] (分類子の作成) をクリックします。
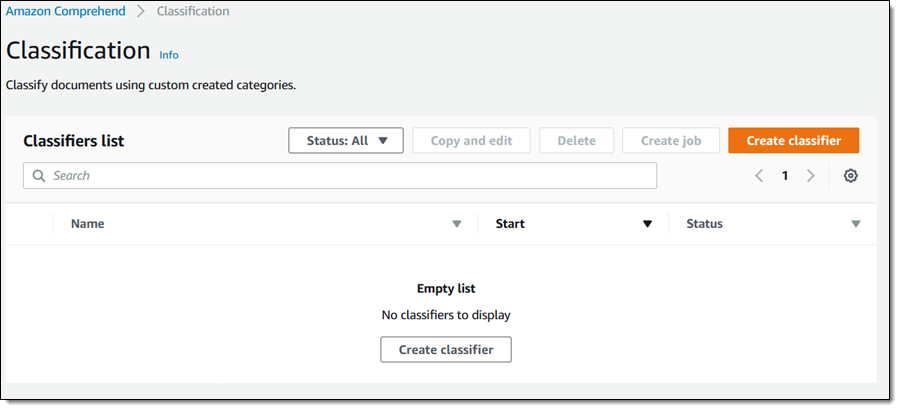
分類子に名前をつけ、文書の言語を選択し、自分のトレーニングデータが置かれている S3 バケットを選択します。その後、そのバケットへのアクセス許可をもつ AWS Identity and Access Management (IAM) ロールを作成します。そして、[Create classifier] (分類子を作成) をクリックして先に進みます。
トレーニングの処理はすぐに始まります。
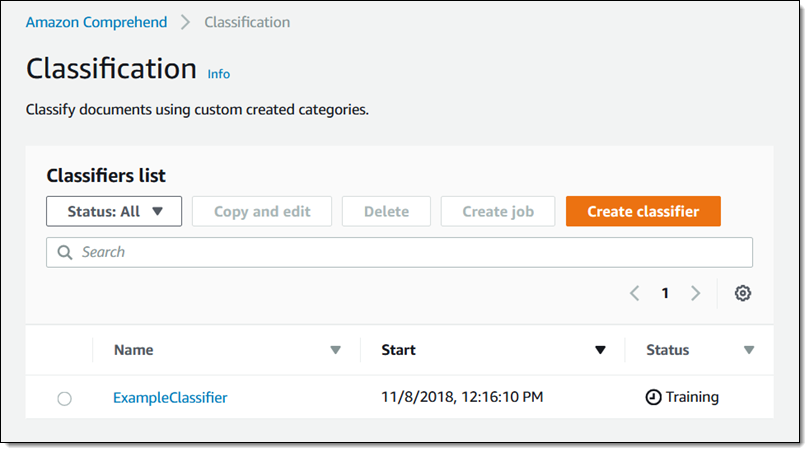
ステータスは数分で [Trained] (トレーニング済み) に変わり、これでテキストの分類と、不適切な言葉が大量に含まれたテキストの分類をする分類ジョブを作成する準備は完了です。
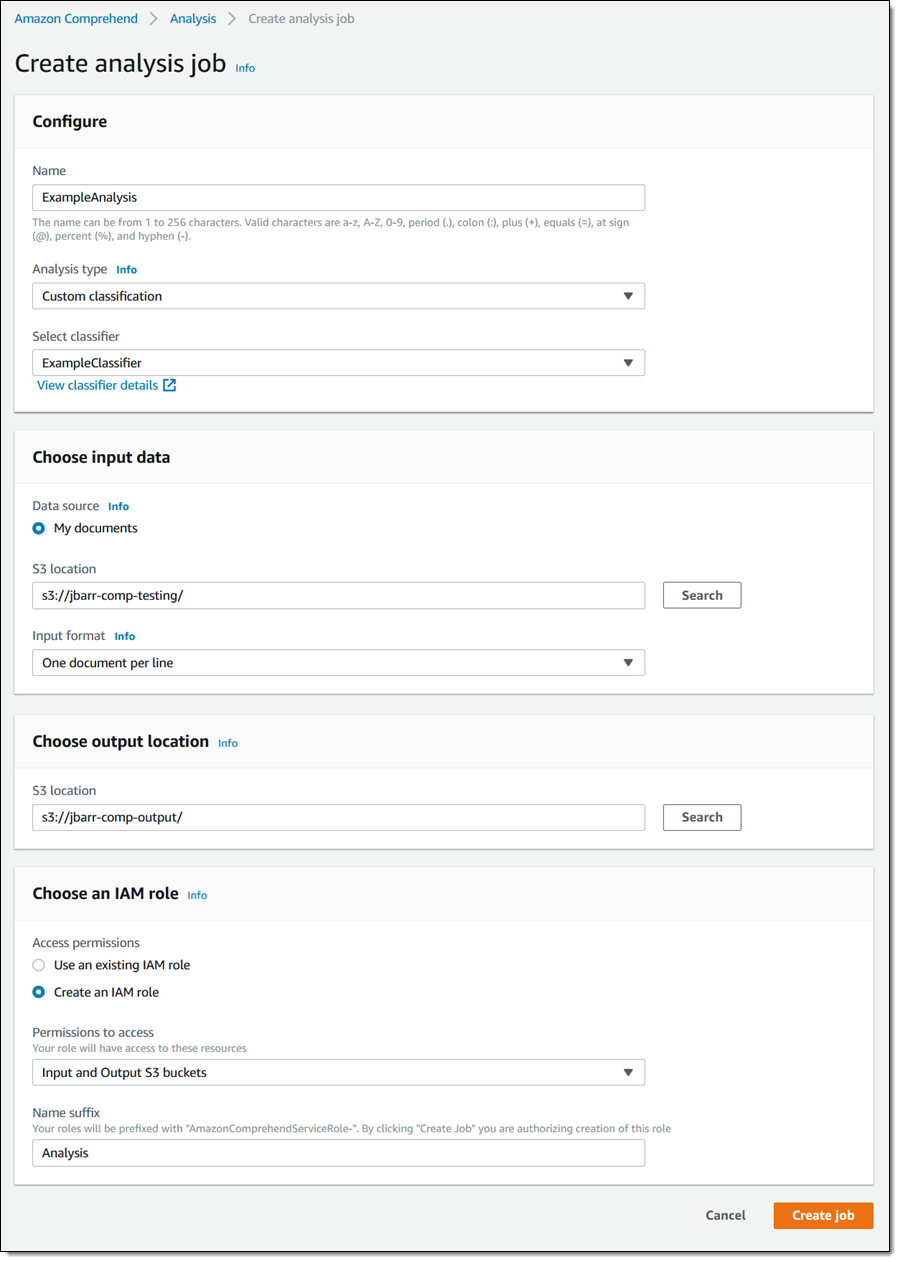
このテキストを別の S3 バケットへ入れてコンソールの [Analysis] (分析) をクリックし、[Create job] (ジョブの作成) をクリックします。その後、ジョブに名前をつけて、分析のタイプとしてカスタム分類を選択し、先程構築した分類子を選択します。また、(上記のファイルで) 入力バケットと、新しく構築された分類子ごとに分類された結果を受信する別のバケットをポイントし、[Create job] (ジョブを作成) をクリックして先に進みます (重要な安全上のヒント: 入力と出力に同じ S3 バケットを使用するのであれば、入力文書は名前で参照するようにしてください)。
ジョブはすぐに開始され、数分で完了します。
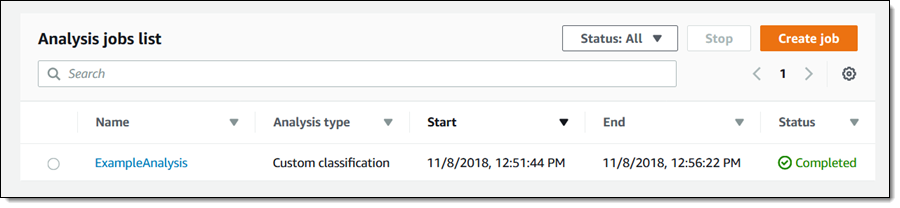 結果はジョブが作成されたときに選択した S3 バケットに保存されます。
結果はジョブが作成されたときに選択した S3 バケットに保存されます。
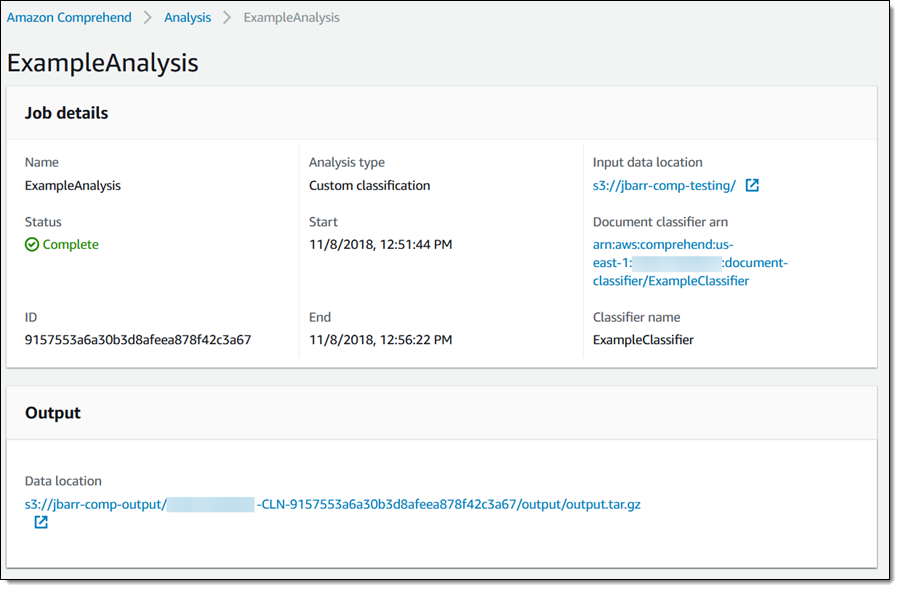
出力の各行は、入力ファイルの文書に呼応します。

1 行の詳細を示す例を以下に示します。
ご覧のように新しい分類サービスはパワフルで使用しやすいものです。Machine Learning についてまったく知識がなくても、数分で有用かつ高品質の結果を得ることができました。
ところで、Amazon Comprehend CLI と Amazon Comprehend API を使用してモデルをトレーニングし、テストすることもできます。
今すぐ利用可能です!
Amazon Comprehend の分類サービスは現在、Comprehend を利用できるすべてのリージョンでご利用いただけます。
— Jeff;
Amazon Comprehend は自然言語のテキストを大量に処理するパワーをもたらします (詳しくは、入門的な内容を記した、私の投稿記事、Amazon Comprehend – Continuously Trained Natural Language Processing をご覧ください)。2017 年に英語およびスペイン語のサポートとともに立ち上げて以来、私たちはお客様のニーズに基づいた機能を追加してきました。たとえば、非同期バッチオペレーション、構文分析、多言語サポート (フランス語、ドイツ語、イタリア語、ポルトガル語)、リージョンの追加などが挙げられます。
自動機械学習 (AutoML) を使用することで、Comprehend は ML の入力と出力を学習する必要のない、お客様が既にお持ちのデータを使用したカスタム自然言語処理 (NLP) モデルの作成を実現します。お客様のデータセットとユースケースに基づき、適切なアルゴリズムを自動的に選択して、パラメータ、ビルドのチューニング、および結果モデルのテストを行います。
タグ付き文書のコレクションを既にお持ちであれば (サポートチケット、Amazon Transcribe 経由、フォーラムの投稿などといったコールセンターの会話)、開始点としてこれらをご使用いただけます。この場合、タグ付きとは単に、各文書が検証済みであり、望ましい方法で特徴づけるラベルが割り当てられていることを意味します。カスタム分類には少なくともラベルごとに 50 件の文書が必要ですが、数百または数千件の文書があれば特徴づけの精度が上がります。
この記事では主にカスタム分類について取り上げ、適切なテキストから不適切な表現を含むテキストを分離するモデルのトレーニング方法をご紹介します。続いて、新しいテキストを分類するモデルの使用方法をご紹介します。
分類子の使用
開始点となるのは次の様なトレーニングテキストの CSV ファイルです (ここでは画像を加工していますが、不適切な言葉が多数含まれています)。
トレーニングデータは S3 オブジェクト内に常駐している必要があり、また、1 行につきラベルと文書を 1 つづつ指定します。
次に、Amazon Comprehend コンソールへ移動し、[Classification] (分類)をクリックします。私は既存の分類子を持っていないので、[Create classifier] (分類子の作成) をクリックします。
分類子に名前をつけ、文書の言語を選択し、自分のトレーニングデータが置かれている S3 バケットを選択します。その後、そのバケットへのアクセス許可をもつ AWS Identity and Access Management (IAM) ロールを作成します。そして、[Create classifier] (分類子を作成) をクリックして先に進みます。
トレーニングの処理はすぐに始まります。
ステータスは数分で [Trained] (トレーニング済み) に変わり、これでテキストの分類と、不適切な言葉が大量に含まれたテキストの分類をする分類ジョブを作成する準備は完了です。
このテキストを別の S3 バケットへ入れてコンソールの [Analysis] (分析) をクリックし、[Create job] (ジョブの作成) をクリックします。その後、ジョブに名前をつけて、分析のタイプとしてカスタム分類を選択し、先程構築した分類子を選択します。また、(上記のファイルで) 入力バケットと、新しく構築された分類子ごとに分類された結果を受信する別のバケットをポイントし、[Create job] (ジョブを作成) をクリックして先に進みます (重要な安全上のヒント: 入力と出力に同じ S3 バケットを使用するのであれば、入力文書は名前で参照するようにしてください)。
ジョブはすぐに開始され、数分で完了します。
出力の各行は、入力ファイルの文書に呼応します。
1 行の詳細を示す例を以下に示します。
{
"File":"profanity_test.csv",
"Line":"0",
"Classes":[
{
"Name":"PROFANITY",
"Score":1.0
},
{
"Name":"NON_PROFANITY",
"Score":0.0
}
]
}ところで、Amazon Comprehend CLI と Amazon Comprehend API を使用してモデルをトレーニングし、テストすることもできます。
今すぐ利用可能です!
Amazon Comprehend の分類サービスは現在、Comprehend を利用できるすべてのリージョンでご利用いただけます。
— Jeff;
コメント
コメントを投稿