新しい Amazon DynamoDB キー診断ライブラリを使用して、アプリケーションのトラフィックパターンを視覚化および理解する方法
新しい Amazon DynamoDB キー診断ライブラリを使用して、アプリケーションのトラフィックパターンを視覚化および理解する方法:
本日、最もアクセスしたデータベース項目のグラフとダッシュボードを表示することを可能にする Amazon DynamoDB キー診断ライブラリを公開しました。DynamoDB テーブルは、プロビジョニング対応とオンデマンドの 2 つの異なるキャパシティーモードで使用できます。DynamoDB は特定の項目に対するトラフィックが 3000 読み込みキャパシティーユニット/秒または 1000 書き込みキャパシティーユニット/秒を超えない限り、アクセスパターンを自動的にサポートします。キー診断ライブラリは、テーブルへのトラフィックを分析し、各パーティションキーへの読み込みと書き込みの回数を示すグラフを表示するツールを提供します。これにより、ほぼリアルタイムでアプリケーションのトラフィックを監視し、予期しない不均一なワークロードに対応することができます。
例えば、ほとんどのページビューを稼いでいる、インベントリテーブルの中で最も人気のある製品を知りたければ、ライブラリは最も関心のある製品を特定するのに役立ちます。あなたがモバイルゲームを管理している場合、過剰なトラフィックを引き起こし、他のゲーマーに悪影響を与える潜在的な厄介者を迅速に特定し、速度を制限することができます。
このブログ記事では、主要な診断ライブラリを設定する方法を説明します。次に、ライブラリの視覚化を使用して、映画データベースの例で、不均一なアクセス分布のキーを特定する方法を説明します。

SDK の統合方法については、CloudFormation テンプレートをデプロイしてください。不均一なアクセス分布と関連するメトリクスを表示するダッシュボードを表示するには、次のセクションを参照してください。
注意: この記事の掲載時点で、ライブラリはキーのメトリックを分および秒の単位で集計しています。ビジネス要件に応じてあなたはクライアントを変更し、異なる細分性でデータを集約したいと考えているかもしれません。さらに、すべての依存しているサービスが米国東部 (バージニア北部)、米国西部 (オレゴン)、欧州 (アイルランド)、欧州 (フランクフルト)でのみ利用可能なため、この AWS リージョンにある CloudFormation テンプレートを含めて設定することができます。アベイラビリティは時間の経過とともに変わることがあるため、最新情報は AWS リージョンテーブルを参照してください。
設定された認証情報で Amazon S3、AWS Lambda、Amazon Kinesis、Amazon CloudWatch、CloudFormation の権限があることを確認します。
次に提供されたホットキー Lambda 関数を Amazon S3 バケットにパッケージ化します。
次に、必要な残りの AWS リソース (Kinesis Data Streams ストリーム、Kinesis Data Analytics アプリケーション、CloudWatch アラーム) を次のように作成できます。また、CloudFormation スタック名を指定します。
CloudFormation は Kinesis Data Analytics アプリケーションを自動的に起動しないため、アプリケーションを起動するためには Amazon Kinesis コンソールに移動するか、次のコマンドを実行します。
リポジトリでデモムービーサンプルアプリケーションを実行するか (ステップ 3.1)、キー診断ライブラリを使用するようにコードを変更します (ステップ 3.2)。
この記事のデフォルト設定では、このクライアントを介してアクセスされるすべてのテーブルおよびグローバルセカンダリーインデックスのすべてのキー属性が監視されます。監視する属性を指定する必要があれば、テーブル名のマップをキー属性名に渡すことができます。
DynamoDB と Kinesis クライアントの構築を簡素化するために、提供された
Athena テーブルを作成後は、Amazon QuickSight を使用してアプリケーションのキー使用パターンを視覚化できます。
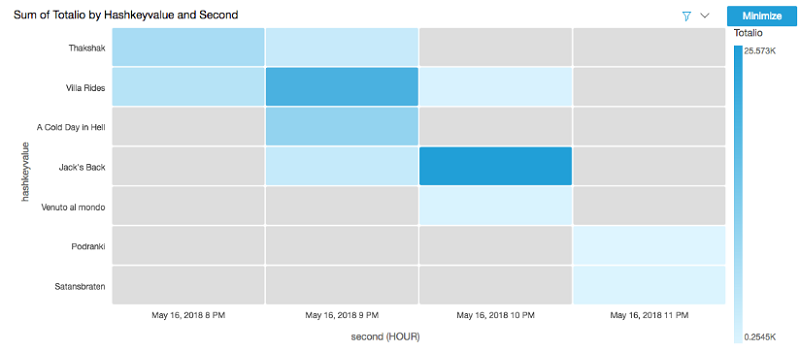
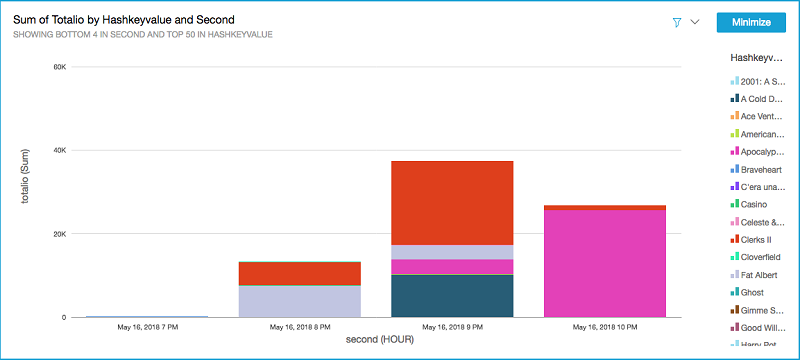
次の視覚化は、サンプルムービーアプリケーションと統合されたときのライブラリからの出力例を示しています。可視化はライブラリがデータベースからレコードを読み取る際の各ムービーレコードの相対的なヒートと、各レコードが経時的にどのくらいのトラフィックがあるかを示します。各レコードのトラフィックを視覚化することで、アプリケーション所有者はトラフィックパターンに基づいた意思決定が可能です。
 Ryan Chan はアマゾン ウェブ サービスのソフトウェア開発エンジニアです。 彼は DynamoDB チームのメンバーで、保存データのオンデマンド暗号化機能を開発しています。
Ryan Chan はアマゾン ウェブ サービスのソフトウェア開発エンジニアです。 彼は DynamoDB チームのメンバーで、保存データのオンデマンド暗号化機能を開発しています。
Most afa Elhemali はアマゾン ウェブ サービスのシニアソフトウェア開発エンジニアです。
afa Elhemali はアマゾン ウェブ サービスのシニアソフトウェア開発エンジニアです。
 Padma Malligarjunan は AWS のシニア製品マネージャーで、財務、ゲーム、小売り業界での経歴があります。 彼女は、Amazon DynamoDB を使用して、分散型でスケーラビリティの高いアプリケーションを構築するための開発ベストプラクティスのトレーニングと宣伝に取り組んでいます。
Padma Malligarjunan は AWS のシニア製品マネージャーで、財務、ゲーム、小売り業界での経歴があります。 彼女は、Amazon DynamoDB を使用して、分散型でスケーラビリティの高いアプリケーションを構築するための開発ベストプラクティスのトレーニングと宣伝に取り組んでいます。
本日、最もアクセスしたデータベース項目のグラフとダッシュボードを表示することを可能にする Amazon DynamoDB キー診断ライブラリを公開しました。DynamoDB テーブルは、プロビジョニング対応とオンデマンドの 2 つの異なるキャパシティーモードで使用できます。DynamoDB は特定の項目に対するトラフィックが 3000 読み込みキャパシティーユニット/秒または 1000 書き込みキャパシティーユニット/秒を超えない限り、アクセスパターンを自動的にサポートします。キー診断ライブラリは、テーブルへのトラフィックを分析し、各パーティションキーへの読み込みと書き込みの回数を示すグラフを表示するツールを提供します。これにより、ほぼリアルタイムでアプリケーションのトラフィックを監視し、予期しない不均一なワークロードに対応することができます。
例えば、ほとんどのページビューを稼いでいる、インベントリテーブルの中で最も人気のある製品を知りたければ、ライブラリは最も関心のある製品を特定するのに役立ちます。あなたがモバイルゲームを管理している場合、過剰なトラフィックを引き起こし、他のゲーマーに悪影響を与える潜在的な厄介者を迅速に特定し、速度を制限することができます。
このブログ記事では、主要な診断ライブラリを設定する方法を説明します。次に、ライブラリの視覚化を使用して、映画データベースの例で、不均一なアクセス分布のキーを特定する方法を説明します。
DynamoDB キー診断ライブラリの概要
DynamoDB キー診断ライブラリは、既存のアプリケーションと簡単に統合できる DynamoDB SDK の軽量ラッパーです。ライブラリには AWS アカウントに必要な Amazon Kinesis Data Firehose Stream、Amazon Kinesis Data Streams、Amazon Kinesis Data Analytics、Amazon CloudWatch Logs、CloudWatch アラーム、Amazon Athena、Amazon QuickSight リソースを作成する AWS CloudFormation テンプレートが含まれます。次にパーティションキーを使用して DynamoDB アクセスをログに記録し、各プライマリキーのアクセスの頻度 (「ヒート」) を分析し、ダッシュボードに結果を表示します。次の図は、この記事のセットアップガイドに従うときに、テンプレートでデプロイされるリソースを示しています。SDK の統合方法については、CloudFormation テンプレートをデプロイしてください。不均一なアクセス分布と関連するメトリクスを表示するダッシュボードを表示するには、次のセクションを参照してください。
ステップバイステップガイドの開始方法
推奨される AWS リソースを設定し、自分でサンプルアプリケーションを実行するためには、この GitHub リポジトリをクローンして、続くステップを実行します。注意: この記事の掲載時点で、ライブラリはキーのメトリックを分および秒の単位で集計しています。ビジネス要件に応じてあなたはクライアントを変更し、異なる細分性でデータを集約したいと考えているかもしれません。さらに、すべての依存しているサービスが米国東部 (バージニア北部)、米国西部 (オレゴン)、欧州 (アイルランド)、欧州 (フランクフルト)でのみ利用可能なため、この AWS リージョンにある CloudFormation テンプレートを含めて設定することができます。アベイラビリティは時間の経過とともに変わることがあるため、最新情報は AWS リージョンテーブルを参照してください。
設定ガイド: キー診断ライブラリのインストール、AWS リソースの設定、でもアプリケーションの時刻、コードとの統合方法
前提条件
キー診断ライブラリを使用する、またはデモを実行するには、お使いのマシンに次のものがインストールされている必要があります。- Java 1.8
- Apache Maven 3.0 以降
- AWS コマンドラインインターフェイス (AWS CLI)
ステップ 1: キー診断ライブラリのインストール
キー診断ライブラリをインストールするには、次のコマンドを実行します。$ mvn install
ステップ 2: AWS 認証情報の設定
まだの場合には AWS CLI 認証情報を設定します。設定されたアカウントに、次の AWS リソースが作成されます。$ aws configureステップ 3: CloudFormation テンプレートを使用して必要な AWS リソースを作成およびデプロイする
メトリクスのレポートと監視のために、Lambda 関数をデプロイします。これを行うには、最初に提供された Lambda 関数を Amazon S3 にアップロードします。まだ Amazon S3 バケットがない場合には、1 つ作成します (この記事全体で、プレースホルダー名を自分の名前に置き換えます)。$ export BUCKET_NAME=my_cool_new_bucket
$ aws s3 mb s3://$BUCKET_NAME$ aws cloudformation package \
--template-file resources/DynamoDB_Key_Diagnostics_Library.yaml \
--s3-bucket $BUCKET_NAME \
--output-template-file packaged.yaml$ STACK_NAME=KeyDiagnosticsStack
$ aws cloudformation deploy \
--template-file packaged.yaml \
--stack-name $STACK_NAME \
--capabilities CAPABILITY_IAM# Kinesis コンソールに移動して、Kinesis Data Analtyics アプリケーション名を検索
# または `aws kinesisanalytics list-applications` を実行します
$ KINESIS_ANALYTICS_APP_NAME="ここにアプリケーション名を入力"
# 次に InputID を検索
$ INPUT_ID=`aws kinesisanalytics describe-application \
--application-name $KINESIS_ANALYTICS_APP_NAME \
--query 'ApplicationDetail.InputDescriptions[0].InputId'`
# Kinesis Data Analytics アプリケーションの起動
$ aws kinesisanalytics start-application \
--application-name $KINESIS_ANALYTICS_APP_NAME \
--input-configurations \
Id=$INPUT_ID,\
InputStartingPositionConfiguration={InputStartingPosition=NOW}ステップ 3.1: サンプルムービーアプリケーションの実行
このサンプルアプリケーションは IMDb データセット を使用して、他のムービーよりも多くの評価がされているホットキーシナリオをシミュレーションします。アプリケーションを実行するには、最初にローカルリポジトリにライブラリをインストールします。次にsamples/movies ディレクトリに移動し、次のコマンドを実行してデモを実行します。$ KINESIS_STREAM_NAME="ここに Kinesis Data Stream 名を入力"
$ REGION="Kinesis Stream と DynamoDB テーブルを設定したリージョンを入力"
$ mvn package exec:java@movies -Dexec.args="traffic $KINESIS_STREAM_NAME $REGION"ステップ 3.2: キー診断ライブラリを使用するようにコードを変更する
キー診断ライブラリを使用するには、元の DynamoDB クライアントに加えて、DynamoDB の使用情報を記録するための Kinesis クライアント名と Kinesis Data Streams 名を指定します。DynamoDBKeyDiagnosticsClient client =
DynamoDBKeyDiagnosticsClient.monitorAllPartitionKeys(
dynamoDBClient,
kinesisClient,
kinesisStreamName
);
DynamoDBKeyDiagnosticsClient client = new DynamoDBKeyDiagnosticsClient(
dynamoDBClient,
kinesisClient,
kinesisStreamName,
ImmutableMap.of("MyTable", ImmutableList.of("MyAttribute"))
);DynamoDBKeyDiagnosticsClient インスタンス作成後は、AmazonDynamoDB クライアントを使用していたあらゆる場所でこれを使用できます (インスタンスは AmazonDynamoDB インターフェイスを実装)。DynamoDB と Kinesis クライアントの構築を簡素化するために、提供された
DynamoDBKeyDiagnosticsClientBuilder も使用できます。次のサンプルコードは、使用情報を Kinesis に非同期で記録するために作成されたスレッドプールを閉じます。try (final DynamoDBKeyDiagnosticsClient instrumented =
DynamoDBKeyDiagnosticsClientBuilder.defaultClient(kinesisStreamName)) {
// お使いのアプリケーション
}ステップ 4: 視覚化のための Amazon Athena と Amazon QuickSight の設定
ダッシュボードの作成や主要な使用情報の照会に興味がある場合、または特定の属性のアクセスパターンを理解したい場合は、Athena と Amazon QuickSight の設定を強く推奨します。- Athena コンソールに移動し、[New query 1] の下に続けて貼り付け、[Run query] を選択します。このコマンドは Amazon S3 に格納されているキー使用情報用の Athena データベースを作成します。
CREATE DATABASE IF NOT EXISTS dynamodbkeydiagnosticslibrary
COMMENT 'DynamoDBKeyDiagnosticsLibrary 用の Athena データベース';- Athena テーブルを作成します。サンプルアプリケーションに従い、テーブル名は
moviesです。ステップ 1 で提供された CloudFormation テンプレートを使用する場合、Amazon S3 の場所は以下のものと似たものになります。s3://keydiagnosticsstack-aggregatedresultbucket-ejkhrnvyw8ku/keydiagnostics/
CREATE EXTERNAL TABLE `movies`(
`second` timestamp COMMENT '2 番目の集計結果',
`tablename` string COMMENT 'DynamoDB テーブル名',
`hashkey` string COMMENT 'パーティションキー属性名',
`hashkeyvalue` string COMMENT 'パーティションキー属性名',
`operation` string COMMENT 'DynamoDB 操作',
`totalio` float COMMENT '合計消費 IO')
ROW FORMAT SERDE
'org.openx.data.jsonserde.JsonSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
's3://keydiagnosticsstack-aggregatedresultbucket-ejkhrnvyw8ku/keydiagnostics/'- Amazon QuickSight コンソールに進み、[Manage data] を選択します。
- [New data set] を選択し、[Athena] を選択して、データソース名を指定します。その後は、以前のセクションで作成した Athena データベースとテーブルを選択できるようになります。
- [Import to SPICE for quicker analytics] を選択し、次に [Visualize!] を選択します。
- これでテーブル名、時間範囲、パーティションキーをフィルターしてグラフを作成し、期間内の映画の人気を視覚化できるようになりました。
次の視覚化は、サンプルムービーアプリケーションと統合されたときのライブラリからの出力例を示しています。可視化はライブラリがデータベースからレコードを読み取る際の各ムービーレコードの相対的なヒートと、各レコードが経時的にどのくらいのトラフィックがあるかを示します。各レコードのトラフィックを視覚化することで、アプリケーション所有者はトラフィックパターンに基づいた意思決定が可能です。
まとめ
この記事では、新しい DynamoDB キー診断ライブラリを使用して、最もアクセスされたデータベース項目を特定する方法を示しました。このライブラリを使用すると、グラフやビジュアルダッシュボードを使って、アプリケーションのトラフィックを視覚化できます。データベースにホットキーとホットスポットがある場合、ライブラリは予測不能なワークロードや不均一なワークロードに対応することに役立つツールをもう 1 つ提供します。著者について
Ryan Chan はアマゾン ウェブ サービスのソフトウェア開発エンジニアです。 彼は DynamoDB チームのメンバーで、保存データのオンデマンド暗号化機能を開発しています。Most
afa Elhemali はアマゾン ウェブ サービスのシニアソフトウェア開発エンジニアです。Padma Malligarjunan は AWS のシニア製品マネージャーで、財務、ゲーム、小売り業界での経歴があります。 彼女は、Amazon DynamoDB を使用して、分散型でスケーラビリティの高いアプリケーションを構築するための開発ベストプラクティスのトレーニングと宣伝に取り組んでいます。
コメント
コメントを投稿