Aurora Serverlessを試す
Aurora Serverlessを試す:
ネットワーク装置のログデータをDBに格納しているのですが、Amazon RDSのAurora Serverlessを試したので備忘録として残しておきたいと思います。
Amazon RDSはフルマネージドなデータベースサービスで、データベースのセットアップやパッチ適用、バックアップ、障害対応、スケーリングなどのセットアップ作業や運用作業をAWSのサービスで実施してくれます。RDSの初期設定時にDBエンジンとしてAuroraを選択しキャパシティタイプをServerlessとするとデータベースはサーバレスで稼働し、クライアントからのアクセス時に起動しアクセスがなくアイドル状態が続くと停止されるようになります。
ログデータは常時生成されて行くのでサーバレスと相性は良くないと思われますが、設定などの確認をしたかったためAurora Serverlessを試しています。記載時点でAurora ServerlessはIAMデータベース認証には対応していないようです。
Aurora Serverlessの概要や未対応機能はAWS公式ブログを参照。
公式ドキュメントの*1と*2を参考にDBクラスタを作成します。
事前にVPCとDBサブネットグループ、DBクラスターパラメータグループを作成しておきます。
1.データベースエンジンとしてAuroraを選択し、エディションはMySQL5.6との互換性を選択。
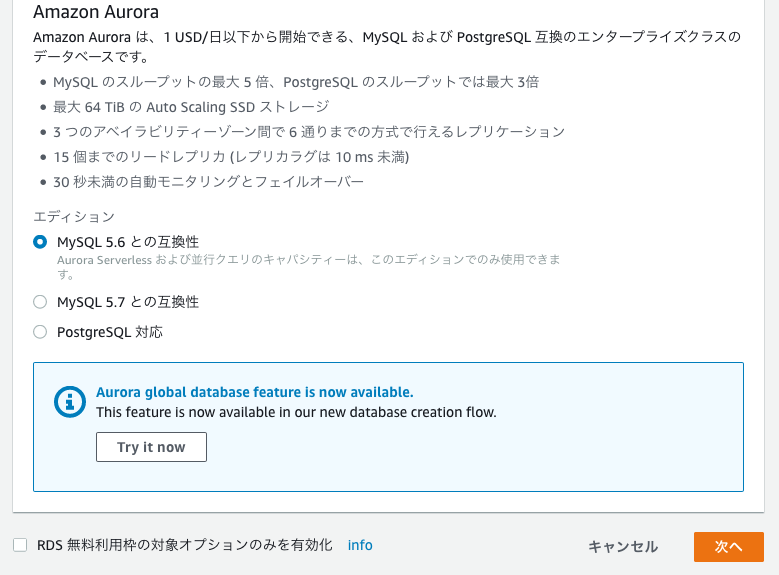
2.DBエンジンのキャパシティタイプとしてServerlessを選択。
3.DBクラスター名とDBの管理者アカウントとパスワードを指定。DBクラスター作成後はこのアカウントで一度別のDBユーザを作成。
4.最小・最大のキャパシティユニットと何分アイドル状態が続いたらクラスターを停止するかを指定。負荷状況に応じてここで指定したキャパシティユニットでスケールしていきます。
5.DBクラスターを配置するVPCとセキュリティグループを指定。
6.DBクラスターパラメータグループやDBの暗号化キー(KMS)などを指定し、DBクラスターを作成。
7.クラスターエンドポイントを確認しクライアントから接続。
AWS CLIからもAurora ServerlessのDBクラスターを作成できます。上記GUIと同じ設定のDBクラスターをAWS CLIから作成する場合は以下を実行。
ドキュメントを参照すると、そのほかオプションの変更も可能なようです。
また作成したDBクラスターはaws rds describe-db-clustersで確認可能。
ドキュメントを参照するとそのほかrdsサブコマンドも確認できます。
アプリから接続する前に、DBクライアントツールでテーブルやユーザを作成しておきます。
仮想マシンを別途用意しmysqlコマンドにてDBクラスタへ接続します。(mysqlコマンドなどはmariadb-clientパッケージなどで入手)
DBクラスターが起動されていない場合、起動処理があるため接続に若干時間がかかります。アイドル状態が続くと再度DBクラスタは停止します。
データ格納用のデータベースを定義。(aws rds create-db-clusterでDBクラスターを作成する際にデータベースも作成できるようです)
作成したデータベースへのアクセス権限を持つユーザを作成。
作成したユーザで再度mysqlコマンドで接続し直してテーブルを定義。
今回はPythonで試しています。PythonからDBクラスターに接続するため、MySQL用ライブラリ(mysql-connector-python)をインストールしておきます。
簡易的なDB接続確認用ですが以下コードを作成します。今回はDBに接続しデータを格納してコミットする程度しかしていない接続簡易確認なので、そのほか必要な実装を行います。(AWS Lambdaでコードを実行する場合はZip形式でパッケージングしlambdaにアップロードして設定します。Lambdaの設定は今回は省略。)
データベース接続情報は環境変数から与えています。#パスワードはいい指定方法ないですかね...
mysql-connector-pythonはMySQL公式ドキュメントを参照。
DatetimeはPython公式ドキュメントを参照。
依存ライブラリをインストールする際にカレントディレクトリにmysql-connectorや依存パッケージが展開されるので、lambdaにアップロードする際は作成したコードとまとめてパッケージングしておきます。
Aurora Serverless MySQL の一般利用が開始
Amazon Aurora の環境をセットアップする
Amazon Aurora の使用開始
create-db-cluster
MySQL Connector/Python Developer Guide
8.1. datetime — 基本的な日付型および時間型
1.はじめに
ネットワーク装置のログデータをDBに格納しているのですが、Amazon RDSのAurora Serverlessを試したので備忘録として残しておきたいと思います。Amazon RDSはフルマネージドなデータベースサービスで、データベースのセットアップやパッチ適用、バックアップ、障害対応、スケーリングなどのセットアップ作業や運用作業をAWSのサービスで実施してくれます。RDSの初期設定時にDBエンジンとしてAuroraを選択しキャパシティタイプをServerlessとするとデータベースはサーバレスで稼働し、クライアントからのアクセス時に起動しアクセスがなくアイドル状態が続くと停止されるようになります。
ログデータは常時生成されて行くのでサーバレスと相性は良くないと思われますが、設定などの確認をしたかったためAurora Serverlessを試しています。記載時点でAurora ServerlessはIAMデータベース認証には対応していないようです。
Aurora Serverlessの概要や未対応機能はAWS公式ブログを参照。
2.DBクラスターの作成
公式ドキュメントの*1と*2を参考にDBクラスタを作成します。事前にVPCとDBサブネットグループ、DBクラスターパラメータグループを作成しておきます。
2.1.GUIで作成
1.データベースエンジンとしてAuroraを選択し、エディションはMySQL5.6との互換性を選択。2.DBエンジンのキャパシティタイプとしてServerlessを選択。
3.DBクラスター名とDBの管理者アカウントとパスワードを指定。DBクラスター作成後はこのアカウントで一度別のDBユーザを作成。
4.最小・最大のキャパシティユニットと何分アイドル状態が続いたらクラスターを停止するかを指定。負荷状況に応じてここで指定したキャパシティユニットでスケールしていきます。
5.DBクラスターを配置するVPCとセキュリティグループを指定。
6.DBクラスターパラメータグループやDBの暗号化キー(KMS)などを指定し、DBクラスターを作成。
7.クラスターエンドポイントを確認しクライアントから接続。
2.2.CLIから作成
AWS CLIからもAurora ServerlessのDBクラスターを作成できます。上記GUIと同じ設定のDBクラスターをAWS CLIから作成する場合は以下を実行。aws rds create-db-cluster \ --db-cluster-identifier [DBクラスター識別子] \ --db-cluster-parameter-group-name [default.aurora5.6] \ --vpc-security-group-ids [VPCのセキュリティグループID(sg-xxxxxxxx)] \ --db-subnet-group-name [DBサブネットグループ] \ --engine aurora \ --master-username [DBマスターユーザ名] \ --master-user-password [DBマスターユーザパスワード] \ --storage-encrypted \ --engine-mode serverless \ --scaling-configuration MinCapacity=2,MaxCapacity=4,AutoPause=True,SecondsUntilAutoPause=300 \ --deletion-protection
また作成したDBクラスターはaws rds describe-db-clustersで確認可能。
aws rds describe-db-clusters --db-cluster-identifier [DBクラスター識別子]
{
"DBClusters": [
{
"Capacity": 4,
"MasterUsername": "DBマスターユーザ",
"ReadReplicaIdentifiers": [],
"VpcSecurityGroups": [
{
"Status": "active",
"VpcSecurityGroupId": "VPCのセキュリティグループID"
}
],
"HostedZoneId": "xxxx",
"EngineMode": "serverless",
"Status": "available",
"MultiAZ": false,
"LatestRestorableTime": "YYYY-MM-DDThh:mm:ss.SSSZ",
"PreferredBackupWindow": "hh:mm-hh:mm",
"DBSubnetGroup": "DBサブネットグループ",
"AllocatedStorage": 1,
"BackupRetentionPeriod": 1,
"PreferredMaintenanceWindow": "date1:hh1:mm1-date2:hh2:mm2",
"Engine": "aurora",
"Endpoint": "クラスターエンドポイント",
"EarliestRestorableTime": "YYYY-MM-DDThh:mm:ss.SSSZ",
"IAMDatabaseAuthenticationEnabled": false,
"ClusterCreateTime": "YYYY-MM-DDThh:mm:ss.SSSZ",
"EngineVersion": "5.6.10a",
"DeletionProtection": true,
"ScalingConfigurationInfo": {
"MinCapacity": 2,
"AutoPause": true,
"MaxCapacity": 4,
"SecondsUntilAutoPause": 300
},
"DBClusterIdentifier": "DBクラスター識別子",
"DbClusterResourceId": "cluster-xxxx",
"DBClusterMembers": [],
"DBClusterArn": "arn:aws:rds:ap-northeast-1:xxxxxxxxxxxx:cluster:DBクラスター識別子",
"KmsKeyId": "arn:aws:kms:ap-northeast-1:xxxxxxxxxxxx:key/xxxx",
"StorageEncrypted": true,
"AssociatedRoles": [],
"DBClusterParameterGroup": "default.aurora5.6",
"AvailabilityZones": [
"ap-northeast-1d",
"ap-northeast-1a",
"ap-northeast-1c"
],
"Port": 3306
}
]
}
3.クライアントからの接続
3.1.事前準備
アプリから接続する前に、DBクライアントツールでテーブルやユーザを作成しておきます。仮想マシンを別途用意しmysqlコマンドにてDBクラスタへ接続します。(mysqlコマンドなどはmariadb-clientパッケージなどで入手)
DBクラスターが起動されていない場合、起動処理があるため接続に若干時間がかかります。アイドル状態が続くと再度DBクラスタは停止します。
mysql -u DBマスターユーザ -p -h クラスターエンドポイント
MySQL [none]> create database Database名 character set utf8; MySQL [none]> show databases;
MySQL [none]> create user ユーザ名1 identified by 'パスワード'; MySQL [none]> grant all on Database名.* to ユーザ名1;
MySQL [none]> use Database名 MySQL [Database名]> create table testTable (testText text, testValue int, time timestamp); MySQL [Database名]> show tables;
3.2.アプリから接続
今回はPythonで試しています。PythonからDBクラスターに接続するため、MySQL用ライブラリ(mysql-connector-python)をインストールしておきます。pip install mysql-connector-python -t .
データベース接続情報は環境変数から与えています。#パスワードはいい指定方法ないですかね...
lambda_function.py
import os
import mysql.connector
from mysql.connector import errorcode
from datetime import datetime
host = os.getenv("HOST_NAME")
dbname = os.getenv("DB_NAME")
username = os.getenv("USER_NAME")
password = os.getenv("PASSWORD")
config = {
'host' : host,
'user' : username,
'password' : password,
'database' : dbname
}
def lambda_handler(event, context):
write_table_mysql()
return 'end of stream data'
def write_table_mysql():
try:
conn = mysql.connector.Connect(**config)
except mysql.connector.Error as err:
print(err)
else:
cursor = conn.cursor()
cursor.execute('insert into testTable (testText, testValue, time) \
values (%s, %s, %s)', ('test message', 1, datetime.now().strftime("%y-%m-%d %H:%M:%S")))
conn.commit()
cursor.close()
conn.close()
#lambda_handler(None, None)
DatetimeはPython公式ドキュメントを参照。
依存ライブラリをインストールする際にカレントディレクトリにmysql-connectorや依存パッケージが展開されるので、lambdaにアップロードする際は作成したコードとまとめてパッケージングしておきます。
zip -r lambda_function.zip *
4.参考記事
Aurora Serverless MySQL の一般利用が開始Amazon Aurora の環境をセットアップする
Amazon Aurora の使用開始
create-db-cluster
MySQL Connector/Python Developer Guide
8.1. datetime — 基本的な日付型および時間型
コメント
コメントを投稿