Amazon SageMaker Jupyterノートブックを使用してAmazon Neptune グラフを分析する
Amazon SageMaker Jupyterノートブックを使用してAmazon Neptune グラフを分析する:
新しいグラフデータモデルやクエリを作成する、あるいは、既存のグラフデータセットを探索するかどうかに関わらず、結果を視覚化できるインタラクティブなクエリ環境があると便利です。このブログ記事では、Amazon SageMaker ノートブックを Amazon Neptune データベースに接続して、これを実現する方法を紹介します。ノートブックを使用して、データをデータベースにロードし、クエリをして結果を視覚化します。
Amazon Neptune は高速かつ信頼性の高いグラフデータベースです。クエリワークロードで、接続をナビゲートし、エンティティ間の関係の強さ、重さ、または品質を活用する必要がある場合に理想的です。
Amazon SageMaker は、機械学習モデルの構築、トレーニング、および開発のための完全管理プラットフォームです。このブログの記事では、その機能に対応した SageMaker を使用し、ホストされた Jupyter ノートブックを提供します数回クリックするだけで、Jupiter のノートブックを作成し、それを Neptune に接続し、データベースのクエリを開始できます
ここで説明した Neptune と SageMaker のリソースにはコストが発生します。SageMaker がホストするノートブックを使用すると、ノートブックをホストする Amazon EC2 インスタンスに対して料金がかかります。このブログ記事では、ml.t2.medium インスタンスを使用しています。このインスタンスは、AWS 無料利用枠 の対象です。
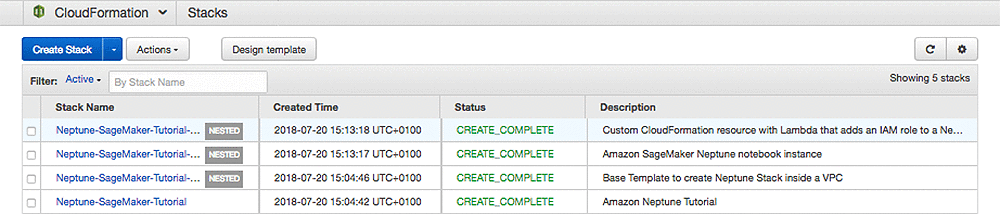
このソリューションは、4つのスタックを作成します。
Jupyter ウィンドウで、Neptune ディレクトリを開き、Getting Started ディレクトリを開きます。
この動作を確認するには、03-Social-Network-Recommendations.ipynb を開き、各セルを順番に実行するか、Run All を Cell ドロップダウンメニューから選択します。それぞれのクエリセルの下に各クエリの結果が表示されます。以下に例を示します。

新しいノートブックを作成するには、Jupyter ウィンドウで、New を選択し、conda_python3 を選択します。
新しいノートブックが util ディレクトリに相対している場所に応じて、neptune.py のパスを変更する必要があります。
どのクラスターに接続するかを、このコマンドはどのように認識するのか? Neptune クラスターと SageMaker ノートブックを作成した CloudFormation テンプレートに、NEPTUNE_CLUSTER_ENDPOINT と NEPTUNE_CLUSTER_PORT いう2つの環境変数を設定します。 これらの変数には、Neptune クラスタの詳細が含まれています。デフォルトでは、すべての neptune.py ヘルパーメソッドがこれらの環境変数を使用しますが、この動作を上書きすることができます。
Gremlin を使用して、ノートブックからデータを挿入するには、ノートブックスのクリプトでトラバーサルソースを作成し、クエリを発行します。
ノートブックスクリプトを使用してオンラインでデータを作成する代わりに、S3 から Neptune にデータを一括ロードできますこのヘルパーモジュールは、Neptune の一括ローダー API を使いやすくします。
プロパティグラフのデータを一括して Neptune にロードするには、データを CSV 形式でフォーマットし、エッジと頂点を、別々のファイルに保存する必要があります。ソースファイルを含む S3 バケットは、Neptune クラスターと同じリージョン内になければなりません。
次のコマンドを使用して、ノートブックから一括ロードを開始できます。
S3 パスに
端末を開いた状態で、tools / apache-tinkerpop-gremlin-console-3.3.3 ディレクトリに移動し、コンソールを起動します。
SageMaker が Neptune に接続できるようにするには、オプションの VPC 設定を選択し、ノートブックインスタンスの作成時に Neptune VPC と Neptune サブネットの1つを指定します。SageMaker は、指定されたサブネットに Elastic Network Interface を作成して、ノートブックインスタンスを Neptune VPC に接続します。
neptune-sagemaker-nested-stack.json – この CloudFormationスタックは、Neptune VPC のサブネットに関連付ける新しい SageMaker セキュリティグループを作成します。ネプチューン VPC セキュリティグループにインバウンドアクセスする、既存のセキュリティグループのIDを指定することで、この振る舞いを無効にできます
neptune-base-stack.json – CloudFormationスタックは、このIAMロールを作成します。ただし、Neptuneの DBCluster CloudFormation リソースは、クラスタの作成時にこのロールをクラスタに関連付けることを許可するプロパティを提供しません。このため、別の CloudFormation テンプレートの add-iam-role-to-neptune.json を使用して、AWS Lambda 関数を使用してロールをクラスタに関連付けるカスタムCloudFormationリソースを使用します。カスタムリソースには、GitHub の Stelligent の例に基づいていますが、Lambda CloudFormation リソースには Lambda Python コードがあります。これは、複数の S3 リージョンのバケットにコードを配置することを避けるために役立ちます。コード開発パッケージを含むバケットは、Lambda 関数が作成されているのと同じ AWS リージョン内に存在する必要があります。
この Python ベースの Lambda 関数は、boto3 を使って Neptune の AddRoleToDBCluster リソース管理 API を呼び出します。
このブログ記事では、Neptune クラスタと SageMaker ノートブック環境を簡単に起動できるように AWS CloudFormation テンプレートを提供しました。これにより、独自のグラフデータモデルやクエリ、ノートブックコンテンツを作成できます。
このブログ記事に質問やご意見がある場合は、コメント欄に自由に記入してください。
 Ian Robinson は、データベースサービスカスタマーアドバイザリーチームのアーキテクトです。彼は「Graph Databases」、「REST in Practice」(両方ともに O’Reilly)と「REST: From Research to Practice」(Springer)と「Service Design Patterns(Addison-Wesley)」の共著者です。
Ian Robinson は、データベースサービスカスタマーアドバイザリーチームのアーキテクトです。彼は「Graph Databases」、「REST in Practice」(両方ともに O’Reilly)と「REST: From Research to Practice」(Springer)と「Service Design Patterns(Addison-Wesley)」の共著者です。
 Kelvin Lawrence は、Amazon Neptune および他の多くの関連サービスに重点を置く、データベースサービス顧客顧問チームのプリンシパルデータアーキテクトです彼は長年にわたりグラフデータベースを扱っており、本書 Practical Gremlin の著者であり、Apache TinkerPop プロジェクトのコミッターです。
Kelvin Lawrence は、Amazon Neptune および他の多くの関連サービスに重点を置く、データベースサービス顧客顧問チームのプリンシパルデータアーキテクトです彼は長年にわたりグラフデータベースを扱っており、本書 Practical Gremlin の著者であり、Apache TinkerPop プロジェクトのコミッターです。
新しいグラフデータモデルやクエリを作成する、あるいは、既存のグラフデータセットを探索するかどうかに関わらず、結果を視覚化できるインタラクティブなクエリ環境があると便利です。このブログ記事では、Amazon SageMaker ノートブックを Amazon Neptune データベースに接続して、これを実現する方法を紹介します。ノートブックを使用して、データをデータベースにロードし、クエリをして結果を視覚化します。
Amazon Neptune は高速かつ信頼性の高いグラフデータベースです。クエリワークロードで、接続をナビゲートし、エンティティ間の関係の強さ、重さ、または品質を活用する必要がある場合に理想的です。
Amazon SageMaker は、機械学習モデルの構築、トレーニング、および開発のための完全管理プラットフォームです。このブログの記事では、その機能に対応した SageMaker を使用し、ホストされた Jupyter ノートブックを提供します数回クリックするだけで、Jupiter のノートブックを作成し、それを Neptune に接続し、データベースのクエリを開始できます
ソリューションの概要
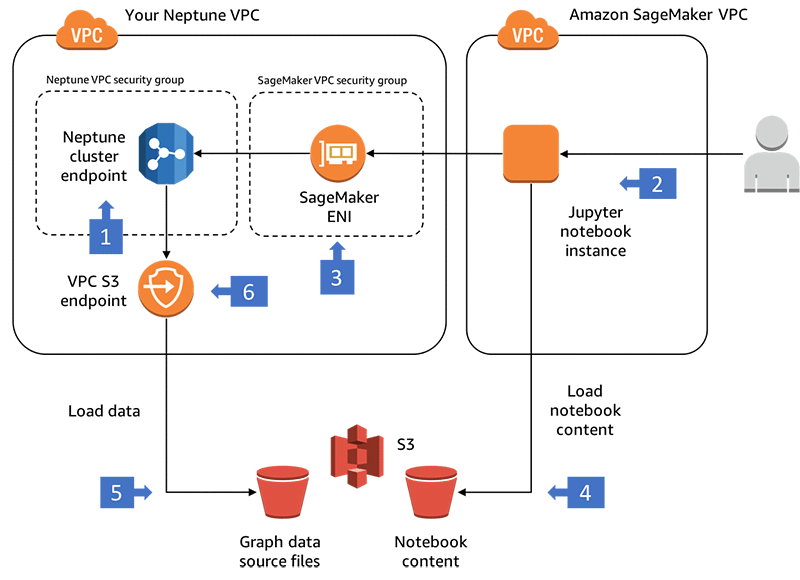
このブログの記事で紹介されているソリューションは、以下のリソースを作成します。- 3 つのサブネットと VPC S3 エンドポイントを持つ Neptune VPC
- 適切なサブネット、パラメータ、およびセキュリティグループを持つ、単一の r4.xlarge インスタンスを含む Neptune クラスター
- Neptune が S3 からデータをロードすることを許可するIAM ロール
- SageMaker Jupyter ノートブックインスタンス、IPython Gremlin 拡張モジュール、Gremlin コンソール、および一部のサンプルノートブックコンテンツ
- Neptune データベースのエンドポイントは、アカウントの新しい VPC にプロビジョニングされます。
- SageMaker の Jupyter ノートブックは、Amazon SageMaker VPC でホストされています。
- SageMaker は、Elastic Network Interface(ENI)を Neptune VPC 内に作成し、ノートブックを Neptune データベースに接続できるようにします。
- ノートブックのコンテンツは、SageMaker ライフサイクル設定スクリプトを使用して、Amazon S3 からノートブックにロードされます。
- Neptune では、Amazon S3 バケットからデータを一括ロードすることができます(これは、ノートブックのコンテンツを格納するバケットとは異なるバケットにすることができます)。
- S3 のファイルにアクセスするには、Neptune は Neptune VPC の VPC S3 エンドポイントを使用します。
Neptune-SageMaker スタックを起動する
次の表で、Launch Stack ボタンの1つを選択して、AWS CloudFormation コンソールから Neptune-SageMaker スタックを起動します。AWS CloudFormation が IAM リソースを作成することを確認し、Create を選択します。ここで説明した Neptune と SageMaker のリソースにはコストが発生します。SageMaker がホストするノートブックを使用すると、ノートブックをホストする Amazon EC2 インスタンスに対して料金がかかります。このブログ記事では、ml.t2.medium インスタンスを使用しています。このインスタンスは、AWS 無料利用枠 の対象です。
| リージョン | 表示 | 起動 |
| 米国東部 (バージニア北部) | 表示 | |
| 米国東部(オハイオ州) | 表示 | |
| 米国西部(オレゴン州) | 表示 | |
| 欧州(アイルランド) | 表示 |
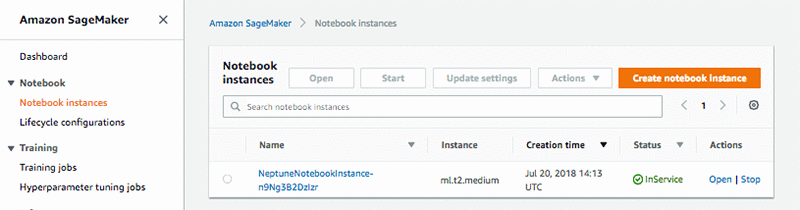
ノートブックインスタンスを起動する
スタックが作成されたら、Amazon SageMakerコンソールを開き、左側のメニューからNotebook instancesを選択します。[アクション] 列で、[開く] を選択します。Jupyter ウィンドウで、Neptune ディレクトリを開き、Getting Started ディレクトリを開きます。
コンテンツを参照して実行する
Getting-Started ディレクトリには、次の 3 つのノートブックがあります。- 01-Introduction.ipynb
- 02-Labelled-Property-Graph.ipynb
- 03-Social-Network-Recommendations.ipynb
この動作を確認するには、03-Social-Network-Recommendations.ipynb を開き、各セルを順番に実行するか、Run All を Cell ドロップダウンメニューから選択します。それぞれのクエリセルの下に各クエリの結果が表示されます。以下に例を示します。
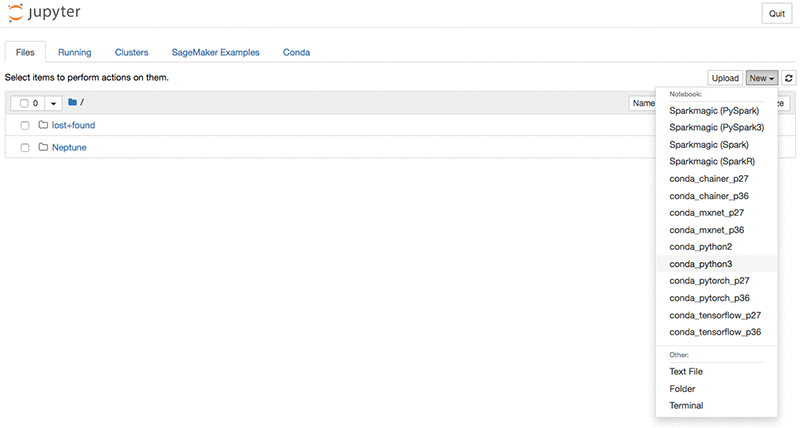
自分のノートを作成する
さて、Jupiter ノートブックから Neptune にクエリする例を見てきたので、ご自身のノートブックを作成する準備が整いました。新しいノートブックを作成するには、Jupyter ウィンドウで、New を選択し、conda_python3 を選択します。
neptune.py を実行する
このソリューションでは、Python ヘルパーモジュールの neptune.py を util ディレクトリにインストールします。このヘルパーモジュールを使用すると、クエリの開始点として機能するトラバーサルソースを簡単に作成でき、データを Neptune に読み込むことができます。ノートブックスクリプトの冒頭で、このヘルパーモジュールを実行します。%run 'util/neptune.py'既存データを削除する
Neptune クラスタに対して他のノートブックを実行している場合は、既存のデータが含まれている可能性があります。このデータを削除するには、次のコマンドを実行します。neptune.clear()neptune.clear(neptune_endpoint=<cluster-endpoint>, neptune_port=<port>)いくつかのデータを作成する
データを 2 種類の方法で、ノートブックから Neptune に挿入できます。Gremlin クライアントを使用して、オンラインの Gremlin エンドポイントにクエリを送信することによって頂点とエッジを作成する、あるいは、Amazon S3 バケットからデータを一括ロードすることもできます。Gremlin を使用して、ノートブックからデータを挿入するには、ノートブックスのクリプトでトラバーサルソースを作成し、クエリを発行します。
g = neptune.graphTraversal()
g.addV('Person').property('name', 'Jane Smith').next()
neptune.graphTraversal() ヘルパーメソッドは、リモート接続を作成し、変数 g をトラバーサルソースにバインドします。このトラバーサルソースは、クエリの開始点として機能します。すべてのクエリに対して新しいトラバーサルソースを初期化する必要はありません。ノートブック全体で g を再利用できます。ノートブックスクリプトを使用してオンラインでデータを作成する代わりに、S3 から Neptune にデータを一括ロードできますこのヘルパーモジュールは、Neptune の一括ローダー API を使いやすくします。
プロパティグラフのデータを一括して Neptune にロードするには、データを CSV 形式でフォーマットし、エッジと頂点を、別々のファイルに保存する必要があります。ソースファイルを含む S3 バケットは、Neptune クラスターと同じリージョン内になければなりません。
次のコマンドを使用して、ノートブックから一括ロードを開始できます。
neptune.bulkLoad('s3://your-bucket-${AWS_REGION}/path-to-your-files/')S3 パスに
${AWS_REGION} プレースホルダを含めると、bulkLoad() ヘルパーメソッドは、これを、Neptune クラスターと SageMaker ノートブックが動作している AWS リージョン名に置き換えます。bulkLoad() は、ロードが完了するまでブロックします。負荷が大きい場合は、メソッドの非同期バージョンを使用し、 bulkLoadStatus() を使用して負荷状況を確認します。status_url = neptune.bulkLoad('<s3-path-to-your-files>')
(status, response) = neptune.bulkLoadStatus(status_url)
statusがLOAD_COMPLETEDの場合、ロードは完了です。これらの 2 行をノートブックの異なるセルに入れて、一度ロードをトリガーすることができますが、繰り返しステータスを確認してください。いくつかのクエリを実行する
Jupyter から Gremlin で Neptune にクエリするには、Gremlin を Python 言語で実装している gremlinpython パッケージを使います。gremlinpython を使うときに覚えておくべきことがいくつかあります:- Pythonの予約語 –
as、in、and、or、is、not、from, およびglobal– には、アンダースコアを付ける必要があります。 - Gremlin サーバにトラバーサルを送信するには、ターミナルアクション –
next()、nextTraverser()、toList()、toSet()、またはiterate()– を使用する必要があります。
g.V().as('a').in_().as_('b').select('a','b').toList()Gremlin コンソールの使用
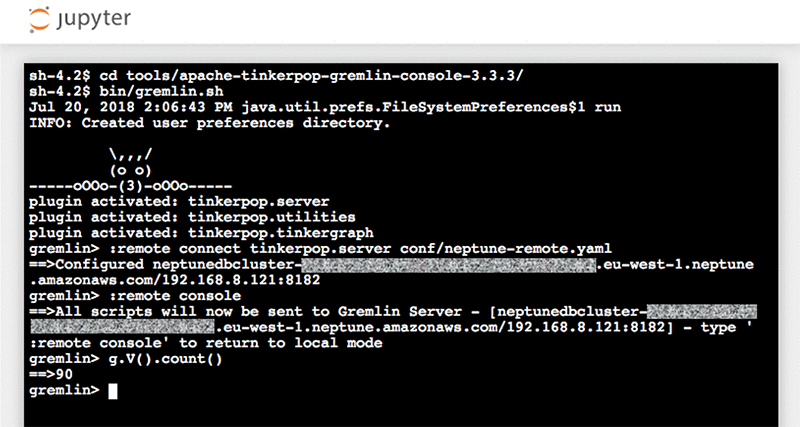
ノートブックにクエリーを書く代わりに、Gremlin コンソールを使って、Neptune と対話することができます。この SageMaker セットアップは、ノートブックインスタンスに Gremlin コンソールをインストールします。コンソールを使用するには、Jupyter ノートブックインスタンスを開き、[New] を選択して、[Terminal] を選択します。これを次に示します。端末を開いた状態で、tools / apache-tinkerpop-gremlin-console-3.3.3 ディレクトリに移動し、コンソールを起動します。
中継されます
このブログ記事で作成されたデータセットとアセットは、いくつかの方法で再利用できます。既存の Neptune クラスタを SageMaker で再利用したいのですが?
問題ありませんルート CloudFormation テンプレート(neptune-sagemaker-base-stack.json)を実行する代わりに、neptune-sagemaker-nested-stack.json テンプレートを実行します。このテンプレートには、次の追加のパラメータを指定する必要があります。- NeptuneClusterEndpoint – 既存の Neptune クラスターのクラスタエンドポイント。この情報は、Neptune クラスタのクラスターの詳細タブから取得できます。
- NeptuneClusterPort – 既存の Neptune クラスターのポート。
- NeptuneClusterVpc – Neptune クラスターが動作している VPC の VPC ID。この情報は、Neptune クラスタのインスタンスの詳細タブから取得できます。
- NeptuneClusterSubnetId – ネプチューンクラスタが実行されているサブネットのIDこの情報は、Neptune クラスタのインスタンスの詳細タブから取得できます。
- NeptuneClientSecurityGroup – ネプチューンクラスタにアクセスできる VPC セキュリティグループNeptune クラスタがどこからでもアクセスできる場合に限り、空のままにしておきます。
- NeptuneLoadFromS3RoleArn – Amazon Neptune が Amazon S3 リソースにアクセスできるようにする IAM ロールの ARN。この ARN は、ノートブックがローダー API にロード要求を送信して、データベースにデータを取り込むときに使用されます。
- NotebookContentS3Locations – ノートブックインスタンスにインストールするノートブックのカンマ区切り S3 位置。
自分のノートブックで CloudFormation テンプレートを再利用する
このブログポストに含まれている CloudFormation テンプレートを再利用して、新しい Neptune クラスターまたは既存の Neptune クラスターに対して、独自のノートブックコンテンツを実行することができます。NotebookContentS3Locations パラメータ値を、自分のノートブックコンテンツの S3 位置に置き換えるだけです。パラメータを空のままにすると、必要なすべての IPython 拡張機能と、あらかじめインストールされている Gremlin コンソールを含む空の Jupyter インスタンスがテンプレートによって作成されます。CloudFormation スタックの詳細
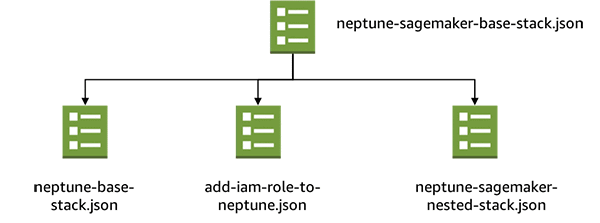
このソリューションには、次の CloudFormation スタックが含まれています。- neptune-sagemaker-base-stack.json – これはルートスタックです。
- neptune-base-stack.json – このスタックは Neptune Quick Start の一部として提供されています。スタックは、3 つのサブネット 、Neptune データベースクラスター、および必要な Neptune サブネット、データベースパラメータ、そしてセキュリティグループ – で新しい VPC を作成します。また、テンプレートは VPC S3 エンドポイントと、Neptune が S3 コンテンツにアクセスできるようにする IAM ロールを作成します。ただし、スタックは IAM ロールを Neptuneクラスターに接続しません。
- add-iam-role-to-neptune.json – このスタックは、AWS Lambda 関数を使用して、前のテンプレートで作成された S3 アクセス IAM ロールを、Neptune クラスターに接続するカスタム CloudFormation リソースを作成します。
- neptune-sagemaker-nested-stack.json – このスタックは、SageMaker Jupyter ノートブックインスタンスを、Amazon SageMaker VPC に作成します。Neptune VPC にネットワークインターフェイスを作成して、ノートブックインスタンスと Neptune クラスタ間のトラフィックを有効にします。テンプレートは、Gremlin コンソール、いくつかのIPython Gremlin 拡張モジュール、指定されたノートブックコンテンツを、ノートブックインスタンスにインストールします。
SageMaker のノートブックアクセス
Neptune Gremlin エンドポイントへのアクセスは、同じ VPC 内のクライアントに限定されます。SageMaker は Amazon SageMaker VPC に Jupyter ノートブックインスタンスを作成します。SageMaker が Neptune に接続できるようにするには、オプションの VPC 設定を選択し、ノートブックインスタンスの作成時に Neptune VPC と Neptune サブネットの1つを指定します。SageMaker は、指定されたサブネットに Elastic Network Interface を作成して、ノートブックインスタンスを Neptune VPC に接続します。
neptune-sagemaker-nested-stack.json – この CloudFormationスタックは、Neptune VPC のサブネットに関連付ける新しい SageMaker セキュリティグループを作成します。ネプチューン VPC セキュリティグループにインバウンドアクセスする、既存のセキュリティグループのIDを指定することで、この振る舞いを無効にできます
S3 IAM の役割を Neptune に自動的に関連付ける
S3 バケットからデータをロードするには、 バケットにアクセスできるAWS Identity and Access Management (IAM)ロールが必要です。このロールの ARN をローダー API に指定すると、データをロードするために Neptune が役割を引き受けます。neptune-base-stack.json – CloudFormationスタックは、このIAMロールを作成します。ただし、Neptuneの DBCluster CloudFormation リソースは、クラスタの作成時にこのロールをクラスタに関連付けることを許可するプロパティを提供しません。このため、別の CloudFormation テンプレートの add-iam-role-to-neptune.json を使用して、AWS Lambda 関数を使用してロールをクラスタに関連付けるカスタムCloudFormationリソースを使用します。カスタムリソースには、GitHub の Stelligent の例に基づいていますが、Lambda CloudFormation リソースには Lambda Python コードがあります。これは、複数の S3 リージョンのバケットにコードを配置することを避けるために役立ちます。コード開発パッケージを含むバケットは、Lambda 関数が作成されているのと同じ AWS リージョン内に存在する必要があります。
この Python ベースの Lambda 関数は、boto3 を使って Neptune の AddRoleToDBCluster リソース管理 API を呼び出します。
client = boto3.client('neptune')
client.add_role_to_db_cluster(
DBClusterIdentifier=dbClusterId,
RoleArn=iamRoleArn
)
環境変数と neptune.py ヘルパーモジュール
この例に含まれる SageMaker ライフサイクル設定スクリプトは、Python スクリプトからアクセスできるいくつかの環境変数を作成します。- NEPTUNE_CLUSTER_ENDPOINT sagemaker-neptune.json テンプレートに提供された Neptune クラスターエンドポイント。
- NEPTUNE_CLUSTER_PORT sagemaker-neptune.jsonテンプレートに提供されたNeptuneクラスタポート。
- NEPTUNE_LOAD_FROM_S3_ROLE_ARN sagemaker-neptune.json テンプレートに提供された S3 ロール ARN。
- AWS_REGION SageMaker ノートブックおよび Neptune データベースが実行されている AWS リージョン。
- clear() ネプチューンデータベースにデータをドロップします
- bulkLoad() S3からのデータをNeptuneにロードする呼び出しをブロックします。S3 パスに${AWS_REGION} プレースホルダーを指定すると、
bulkLoad()はこれをメソッドに渡されたリージョンまたはAWS_REGION 環境変数の値に置き換えます。Neptune にロードするデータを、各 Neptune リージョンのリージョン固有の名前を持つ異なる S3 バケットにパブリッシュすると、ノートブックのコンテンツを作成するときにこのプレースホルダを利用できます。 - bulkLoadAsync() バルクロードプロセスをトリガし、すぐにロードのステータスを確認するために使用できるURLを返します。
- bulkLoadStatus() バルクロード
status_urlが指定されている場合、このメソッドはロードの進行状況をチェックし、(status、jjsonresponse)を返します。ステータスはLOAD_COMPLETEDのときにロードが完了します。 - gr aphTraversal() 変数 g にバインドされたグラフのトラバーサルソースを作成し、後続の Gremlin クエリでグラフを参照するために使用できます
結論
Amazon Neptune を使用すると、高度に接続されたデータを保存してクエリすることができます。Amazon SageMaker でホストされている Jupyter ノートブックを使用すると、Neptune グラフに簡単に接続し、クエリを実行し、視覚化することができます。このブログ記事では、Neptune クラスタと SageMaker ノートブック環境を簡単に起動できるように AWS CloudFormation テンプレートを提供しました。これにより、独自のグラフデータモデルやクエリ、ノートブックコンテンツを作成できます。
このブログ記事に質問やご意見がある場合は、コメント欄に自由に記入してください。
著者について
Ian Robinson は、データベースサービスカスタマーアドバイザリーチームのアーキテクトです。彼は「Graph Databases」、「REST in Practice」(両方ともに O’Reilly)と「REST: From Research to Practice」(Springer)と「Service Design Patterns(Addison-Wesley)」の共著者です。Kelvin Lawrence は、Amazon Neptune および他の多くの関連サービスに重点を置く、データベースサービス顧客顧問チームのプリンシパルデータアーキテクトです彼は長年にわたりグラフデータベースを扱っており、本書 Practical Gremlin の著者であり、Apache TinkerPop プロジェクトのコミッターです。
コメント
コメントを投稿