CSVデータセットのPipeモードを使って、Amazon SageMaker内臓アルゴリズムでトレーニングがより早く
CSVデータセットのPipeモードを使って、Amazon SageMaker内臓アルゴリズムでトレーニングがより早く:
Amazon SageMakerに内臓されたアルゴリズムはPipeモードをサポートし、Machine learning (ML)モデルをトレーニングしている間、Amazon Simple Storage Service (S3)からCSV形式でデータセットを取得しAmazon SageMakerへ取り込みます。
モデルのトレーニングを進めながら、データはPipe入力モードでアルゴリズムコンテナに直接流れます。トレーニングを開始する前にデータをローカルの Amazon Elastic Block Store (EBS)の容量でダウンロードするファイルモードとは異なります。Pipeモードを利用すると、トレーニングはより早く、かなり少ないディスク容量でより速く終了することができます。Machine learningモデルをトレーニングする全体的なコストを削減することができます。3.9GB CSVデータセットのAmazon SageMakerのLinear Learnerアルゴリズムで、回帰モデルのトレーニングに利用した内部基準では、ファイルモードに代わりPipeモードを利用した場合、モデルのトレーニングに費やす時間は全体的に40%も削減される例がありました。Pipeモードと利点の詳細についてはブログの掲示板をご覧ください。
初のデータセットである3.9GB CSVファイルは、200万個の記録を保有し、それぞれの記録は100個のカンマで切り離された単精度浮動小数点数でした。次はバッチサイズが1000でAmazon SageMaker Linear Learnerアルゴリズムをトレーニングしている間の、PipeモードとFileモードの全体的なトレーニングジョブ実施時間とモデルのトレーニング時間を比較したものです。
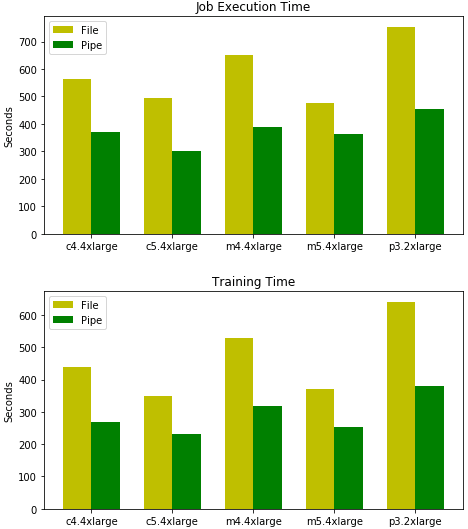
ご覧のようにCSVデータセットでPipe入力モードを利用すると、モードをトレーニングする合計時間はAmazon SageMakerにサポートされているインスタンスタイプで40%も削減できることがわかります。
二度目のデータセットである1GB CSVファイルは、400個の記録のみで、それぞれの記録は10万個のカンマで切り離された単精度浮動小数点数でした。バッチサイズが10の早期に実施していたトレーニング基準で再度実施してみました。
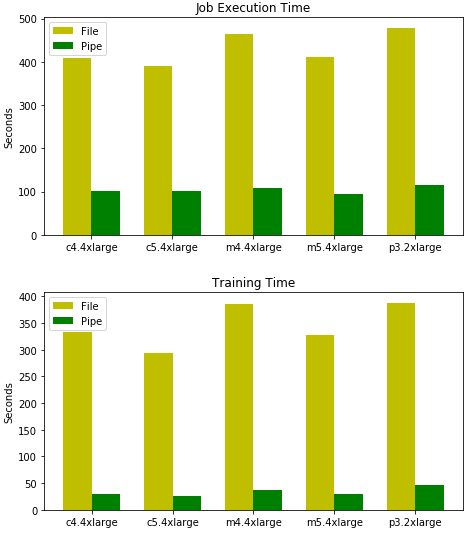
Pipeモードを利用したパフォーマンスは著しい向上を見せ、モデルをトレーニングする合計時間はおよそ75%も削減されました。
このような実験の結果は、Pipe入力モードが目覚ましいパフォーマンスの向上をもたらすということを明確に示しています。トレーニングインスタンスへデータセットをダウンロードすることから生じる遅れを避け、トレーニングジョブでより高度は読み込み処理ができるようになります。
 Can BaliogluはAWS AIアルゴリズムチームのソフト開発エンジニアで、高性能計算を専門にしています。余暇には、お手製のGPUクラスタで遊ぶことが好きです。
Can BaliogluはAWS AIアルゴリズムチームのソフト開発エンジニアで、高性能計算を専門にしています。余暇には、お手製のGPUクラスタで遊ぶことが好きです。
 Sumit Thakurは AWS Machine Learning プラットホームのシニアプロダクトマネージャーで、クラウドで顧客が容易にMachine learningできる製品を開発することが好きです。彼は、Amazon SageMaker と AWS Deep Learning AMI のプロダクトマネージャーです。余暇には、自然に触れたり、SF テレビシリーズを視聴することが好きです。
Sumit Thakurは AWS Machine Learning プラットホームのシニアプロダクトマネージャーで、クラウドで顧客が容易にMachine learningできる製品を開発することが好きです。彼は、Amazon SageMaker と AWS Deep Learning AMI のプロダクトマネージャーです。余暇には、自然に触れたり、SF テレビシリーズを視聴することが好きです。
Amazon SageMakerに内臓されたアルゴリズムはPipeモードをサポートし、Machine learning (ML)モデルをトレーニングしている間、Amazon Simple Storage Service (S3)からCSV形式でデータセットを取得しAmazon SageMakerへ取り込みます。
モデルのトレーニングを進めながら、データはPipe入力モードでアルゴリズムコンテナに直接流れます。トレーニングを開始する前にデータをローカルの Amazon Elastic Block Store (EBS)の容量でダウンロードするファイルモードとは異なります。Pipeモードを利用すると、トレーニングはより早く、かなり少ないディスク容量でより速く終了することができます。Machine learningモデルをトレーニングする全体的なコストを削減することができます。3.9GB CSVデータセットのAmazon SageMakerのLinear Learnerアルゴリズムで、回帰モデルのトレーニングに利用した内部基準では、ファイルモードに代わりPipeモードを利用した場合、モデルのトレーニングに費やす時間は全体的に40%も削減される例がありました。Pipeモードと利点の詳細についてはブログの掲示板をご覧ください。
Amazon SageMakerの内臓アルゴリズムでPipeモードを利用する
本年度初頭に内臓Amazon SageMakerアルゴリズムで利用するPipe入力モードが初めて発表された時は、protobuf recordIO形式のダータのみをサポートしていました。高処理のトレーニングジョブに特化した特殊な形式です。Pipe入力モードの持つ利点を、CSV形式のトレーニングデータセットでも活用できるようになりました。次のAmazon SageMaker内臓アルゴリズムでは、Pipe入力モードを使ったCSV形式のデータセットによるトレーニングを全面的にサポートしています:- 主成分分析 (PCA)
- K-Meansクラスタリング
- K-Nearestネイバー
- Linear Learner (分類と回帰)
- ニューラルトピックモデリング
- ランダムカットフォレスト
CSVの最適化Pipeモードを使ったより迅速なトレーニング
CSV形式でデータセットに新しく実行されるPipeモードは、高度に最適化された高処理を可能にします。Amazon SageMaker Linear Learnerアルゴリズムを合成CSVデータセット上でトレーニングし、Pipe入力モードを使うとパフォーマンスが向上することを実証します。初のデータセットである3.9GB CSVファイルは、200万個の記録を保有し、それぞれの記録は100個のカンマで切り離された単精度浮動小数点数でした。次はバッチサイズが1000でAmazon SageMaker Linear Learnerアルゴリズムをトレーニングしている間の、PipeモードとFileモードの全体的なトレーニングジョブ実施時間とモデルのトレーニング時間を比較したものです。
ご覧のようにCSVデータセットでPipe入力モードを利用すると、モードをトレーニングする合計時間はAmazon SageMakerにサポートされているインスタンスタイプで40%も削減できることがわかります。
二度目のデータセットである1GB CSVファイルは、400個の記録のみで、それぞれの記録は10万個のカンマで切り離された単精度浮動小数点数でした。バッチサイズが10の早期に実施していたトレーニング基準で再度実施してみました。
Pipeモードを利用したパフォーマンスは著しい向上を見せ、モデルをトレーニングする合計時間はおよそ75%も削減されました。
このような実験の結果は、Pipe入力モードが目覚ましいパフォーマンスの向上をもたらすということを明確に示しています。トレーニングインスタンスへデータセットをダウンロードすることから生じる遅れを避け、トレーニングジョブでより高度は読み込み処理ができるようになります。
Amazon SageMakerを利用する
ノートブック見本を活用してAmazon SageMakerで始めましょう。開発者ガイドには多くの資料があり、ディスカッション・フォーラム に登録すると新商品のお知らせを受け取ることができます。著者について
Can BaliogluはAWS AIアルゴリズムチームのソフト開発エンジニアで、高性能計算を専門にしています。余暇には、お手製のGPUクラスタで遊ぶことが好きです。Sumit Thakurは AWS Machine Learning プラットホームのシニアプロダクトマネージャーで、クラウドで顧客が容易にMachine learningできる製品を開発することが好きです。彼は、Amazon SageMaker と AWS Deep Learning AMI のプロダクトマネージャーです。余暇には、自然に触れたり、SF テレビシリーズを視聴することが好きです。
コメント
コメントを投稿