AWS Fargate を使用してサーバーレスの Twitter リーダーを構築する
AWS Fargate を使用してサーバーレスの Twitter リーダーを構築する:
前回の記事では、Ben Snively と Vai Desai が、サーバーレス技術を用いてソーシャルメディアのダッシュボードを構築する方法を紹介しました。ソーシャルメディアのダッシュボードは「#AWS」のハッシュタグでツイートを読み取り、機械学習ベースのサービスを使用して翻訳を行い、自然言語処理 (NLP) を使用してトピック、エンティティ、センチメント分析を行います。最後に、Amazon Athena を使用してこの情報を集計し、ダッシュボードを作成して、ツイートから取得した情報を可視化します。このアーキテクチャでは、管理する唯一のサーバーは Twitter フィードを読み取るアプリケーションを実行します。このブログ記事では、このアプリケーションを Docker コンテナに移動し、AWS Fargate を使用して Amazon ECS で実行する手順について説明します。これにより、アーキテクチャ内で Amazon EC2 インスタンスを管理する必要がなくなります。
AWS Fargate は、Amazon Elastic Container Service (ECS) のテクノロジーで、それによりサーバーやクラスターを管理することなくコンテナを実行できるようになります。AWS Fargate を使用すると、コンテナを実行するために仮想マシンのクラスタをプロビジョニング、構成、および拡張する必要がなくなります。これにより、サーバーの種類を選択したり、クラスターをいつスケールするかを決めたり、クラスターのパッキングを最適化したりする必要がなくなります。AWS Fargate により、サーバーやクラスターとやり取りしたり、考えたりする必要がなくなります。AWS Fargate を使用すると、コンテナアプリケーションを実行するインフラストラクチャを管理する代わりに、コンテナアプリケーションの設計と構築に専念できます。
AWS Fargate は、Amazon EC2 の運用上の責任を排除したい場合に最適です。AWS Fargate は、AWS CodeStar、AWS CodeBuild、AWS CodeDeploy、AWS CodePipeline などの AWS Code サービスと完全に統合されており、エンドツーエンドの継続的な配信パイプラインを設定して ECS への導入を自動化することが難なく行えます。
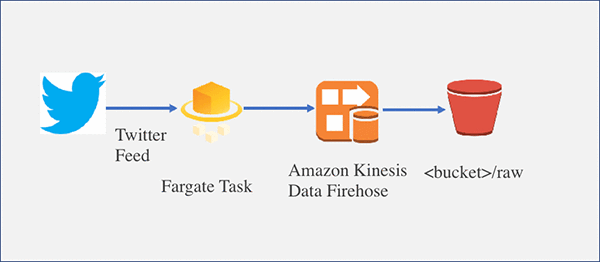
このブログ記事では、EC2 インスタンスで実行する Twitter のストリームプロデューサーアプリを、Fargate が管理するコンテナに移すことに焦点を当てます。
まず、Twitter フィードリーダーアプリケーション用のコードとその依存関係をすべて持つ Docker イメージを作成します。Docker イメージを取得したら、Docker イメージのリポジトリとして機能する ECR にこのイメージをアップロードして登録します。ECR に登録されたイメージを使用して、Fargate サービスで Docker コンテナを実行するために設定したい構成を記述するタスク定義を作成します。最後に、タスクを実行してアプリケーションをテストします。
出力: さまざまなパッケージをインストールし、Dockerfile からイメージを構築する際に環境変数を設定します。Dockerfile の 5〜10 のステップでは、次のような出力が生成されます。
Dev Environment で以下の手順を実行します。
ECS と Fargate を使った作業の詳細については、「AWS Fargate ドキュメント」をご覧ください。
 Raja Mani は、AWS パートナーをサポートするソリューションアーキテクトです。彼は サーバーレス開発、DevOps、コンテナ、ビッグデータ、機械学習に興味を持っています。彼は AWS パートナーが顧客向けにエンタープライズレベルの Amazon Web Services ソリューションを設計するのを手伝っています。
Raja Mani は、AWS パートナーをサポートするソリューションアーキテクトです。彼は サーバーレス開発、DevOps、コンテナ、ビッグデータ、機械学習に興味を持っています。彼は AWS パートナーが顧客向けにエンタープライズレベルの Amazon Web Services ソリューションを設計するのを手伝っています。
 Luis Pineda はシカゴに本拠を置く Amazon Web Services のパートナーソリューションアーキテクトです。AWS を使用してビジネス上の問題を解決するために、パートナーや顧客と協力しています。仕事以外では、アウトドア、ランニング、サイクリングやサッカーを楽しんでいます。
Luis Pineda はシカゴに本拠を置く Amazon Web Services のパートナーソリューションアーキテクトです。AWS を使用してビジネス上の問題を解決するために、パートナーや顧客と協力しています。仕事以外では、アウトドア、ランニング、サイクリングやサッカーを楽しんでいます。
前回の記事では、Ben Snively と Vai Desai が、サーバーレス技術を用いてソーシャルメディアのダッシュボードを構築する方法を紹介しました。ソーシャルメディアのダッシュボードは「#AWS」のハッシュタグでツイートを読み取り、機械学習ベースのサービスを使用して翻訳を行い、自然言語処理 (NLP) を使用してトピック、エンティティ、センチメント分析を行います。最後に、Amazon Athena を使用してこの情報を集計し、ダッシュボードを作成して、ツイートから取得した情報を可視化します。このアーキテクチャでは、管理する唯一のサーバーは Twitter フィードを読み取るアプリケーションを実行します。このブログ記事では、このアプリケーションを Docker コンテナに移動し、AWS Fargate を使用して Amazon ECS で実行する手順について説明します。これにより、アーキテクチャ内で Amazon EC2 インスタンスを管理する必要がなくなります。
AWS Fargate は、Amazon Elastic Container Service (ECS) のテクノロジーで、それによりサーバーやクラスターを管理することなくコンテナを実行できるようになります。AWS Fargate を使用すると、コンテナを実行するために仮想マシンのクラスタをプロビジョニング、構成、および拡張する必要がなくなります。これにより、サーバーの種類を選択したり、クラスターをいつスケールするかを決めたり、クラスターのパッキングを最適化したりする必要がなくなります。AWS Fargate により、サーバーやクラスターとやり取りしたり、考えたりする必要がなくなります。AWS Fargate を使用すると、コンテナアプリケーションを実行するインフラストラクチャを管理する代わりに、コンテナアプリケーションの設計と構築に専念できます。
AWS Fargate は、Amazon EC2 の運用上の責任を排除したい場合に最適です。AWS Fargate は、AWS CodeStar、AWS CodeBuild、AWS CodeDeploy、AWS CodePipeline などの AWS Code サービスと完全に統合されており、エンドツーエンドの継続的な配信パイプラインを設定して ECS への導入を自動化することが難なく行えます。
Fargate でツイート読み取りアプリを実行する
このブログ記事に沿って作業すると、次のようなアーキテクチャがセットアップされます。このブログ記事では、EC2 インスタンスで実行する Twitter のストリームプロデューサーアプリを、Fargate が管理するコンテナに移すことに焦点を当てます。
まず、Twitter フィードリーダーアプリケーション用のコードとその依存関係をすべて持つ Docker イメージを作成します。Docker イメージを取得したら、Docker イメージのリポジトリとして機能する ECR にこのイメージをアップロードして登録します。ECR に登録されたイメージを使用して、Fargate サービスで Docker コンテナを実行するために設定したい構成を記述するタスク定義を作成します。最後に、タスクを実行してアプリケーションをテストします。
前提条件
- 前回のブログ記事にアクセスし、そこにある指示に従ってください。高水準のステップは次のとおりです。
- AWS CloudFormation テンプレートを起動します。テンプレートを起動するときは、Twitter API の設定パラメータを指定する必要があります。
- CloudFormation スタックが作成された後、AWS マネジメントコンソールでスタックを検索し、[Resources] を選択します。IngestionFirehoseStream リソースの物理 ID をメモします。それは次のようなものになるでしょう: SocialMediaAnalyticsBlogPo-IngestionFirehoseStream-<ID>

- S3 通知を設定する – 新しいツイートから Amazon Translate と Amazon Comprehend を呼び出す
- Twitter のストリームプロデューサーを開始します。これは、EC2 インスタンスで実行されているアプリケーションです。
- Athena テーブルを作成します。これは、4 つの異なる SQL ステートメントを実行することによって行われます。
- (オプション – 推奨) Amazon QuickSight ダッシュボードを構築します。
すべての手順を完了したら、次のアーキテクチャを環境にデプロイする必要があります。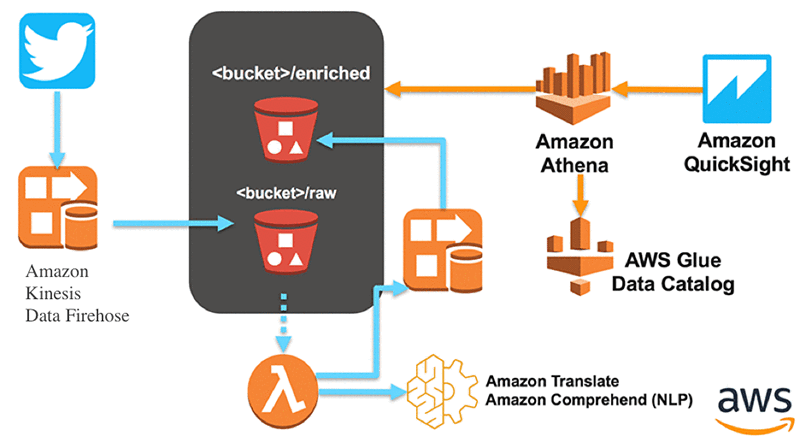
- AWS CLI コマンドと Docker コマンドを実行できる環境を設定します。EC2 インスタンスを起動して Docker をインストールするか、Docker に付属の AWS Cloud9 を使用できます。EC2 インスタンスを使用し、Docker をそこにインストールしました。EC2 オプションを使用する場合は、IAM ロールを作成してインスタンスにアタッチする必要があります。
この環境を、次のステップから「Dev Environment」と呼ぶことにします。Dev Environment を使用して Docker イメージを作成し、イメージを ECR サービスに登録します。この環境では、Amazon Kinesis Data Firehose、ECR、および IAM API の使用を許可する必要があります。{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "ssm:PutParameter", "firehose:*", "iam:CreateRole", "ecr:*", "iam:AttachRolePolicy", "ssm:GetParameter" ], "Resource": "*" } ] }
注: Docker 環境に AWS CLI をインストールする必要があります。AWS CLI のインストールについては、このページを参照してください。
ステップ 1: Docker イメージを作成する
Docker イメージを作成するには、まず Dockerfile を作成する必要があります。Dockerfile は、Docker イメージに使用するベースイメージと、インストールしてその上で実行したいものを記述したマニフェストです。Dockerfile の詳細については、Dockerfile の [Reference] をご覧ください。ここでは、Node アプリケーションを実行するコンテナをインスタンス化するために使用する Docker イメージを作成します。特に、Twitter ストリームプロデューサーノードアプリケーションを実行したいと思います。- Docker 環境でディレクトリを選択し、そのディレクトリで次の手順を実行します。ここでは /home/ec2-user ディレクトリを使用して、以下の手順を実行します。
- アプリケーションコードを Dev Environment にダウンロードします。前提条件のセクション 1.a の手順を実行したとき、SocialMediaAnalyticsBlogPost というスタックを作成するために CloudFormation テンプレートを使用しました。このスタックは、Twitter ストリームプロデューサーアプリで EC2 インスタンスを設定します。CloudFormation ファイルを開いて EC2 設定セクション (テンプレートの 229 行目) に移動すると、アプリケーションコードが Amazon S3 バケットから EC2 インスタンスにコピーされたことがわかります。Dev Environment に同じコードをコピーしたいと思います。次のコマンドを使用します。
mkdir SocialAnalyticsReader cd socialAnalyticsReader wget https://s3.amazonaws.com/serverless-analytics/SocialMediaAnalytics-blog/SocialAnalyticsReader.tar tar -xf SocialAnalyticsReader.tar - 今度は SocialAnalyticsReader アプリでリファクタリングを少し行います。Node アプリケーションは現在、設定ファイルから Twitter API 資格情報を読み取るように設計されています。このアプローチは、アプリケーションがコンテナで実行された後は避けようと思います。より良い方法は、AWS Systems Manager Parameter Store のようなサービスに設定を保存することです。設定を抽出することで、コンテナイメージの柔軟性と再利用性が向上します。たとえば、Docker イメージを再構築する必要なく、アプリケーションの設定値を変更することができます。次のファイルの内容を置き換えます。twitter_stream_producer_app.js
twitter_stream_producer.js'use strict'; var AWS = require('aws-sdk'); var config = require('./config'); var producer = require('./twitter_stream_producer'); // var kinesis = new AWS.Kinesis({region: config.kinesis.region}); var kinesis_firehose = new AWS.Firehose({apiVersion: '2015-08-04', region: config.region}); // console.log(kinesis_firehose.listDeliveryStreams()); var params = { Name: '/twitter-reader/aws-config', /* required */ WithDecryption: false }; var config_from_parameter_store; var ssm = new AWS.SSM({region: config.region}); var request = ssm.getParameter(params); var promise = request.promise(); promise.then( function(data){ console.log('promise then:',data.Parameter.Value); // global.twitter_config = data.Parameter.Value; producer(kinesis_firehose, data.Parameter.Value).run(); }, function(error){ console.log(error); });
新しいファイルを元のバージョンと比較すると、わずか数行のコードしか変更されていないことがわかります。要するに、これでアプリケーションは、AWS Node SDK を使用して、設定ファイルから設定を取得するのではなく、AWS Systems Manager Parameter ストアから設定を取得します。コンテナの設定と秘密を扱うために推奨されるアプローチに関する詳細については、このブログ記事をお勧めします。'use strict'; var config = require('./config'); //var twitter_config = require('./twitter_reader_config.js'); var Twit = require('twit'); var util = require('util'); var logger = require('./util/logger'); function twitterStreamProducer(firehose, twitter_config_str) { var twitter_config = JSON.parse(twitter_config_str); var log = logger().getLogger('producer'); var waitBetweenPutRecordsCallsInMilliseconds = config.waitBetweenPutRecordsCallsInMilliseconds; var T = new Twit(twitter_config.twitter) function _sendToFirehose() { var stream = T.stream('statuses/filter', { track: twitter_config.topics , language: twitter_config.languages }); var records = []; var record = {}; var recordParams = {}; stream.on('tweet', function (tweet) { var tweetString = JSON.stringify(tweet) recordParams = { DeliveryStreamName: twitter_config.kinesis_delivery, Record: { Data: tweetString +'\n' } }; firehose.putRecord(recordParams, function(err, data) { if (err) { console.log(err); } }); } ); } return { run: function() { log.info(util.format('Configured wait between consecutive PutRecords call in milliseconds: %d', waitBetweenPutRecordsCallsInMilliseconds)); _sendToFirehose(); } } } module.exports = twitterStreamProducer; - /home/ec2-user ディレクトリに戻り、次の内容の Dockerfile (大文字と小文字を区別) というファイルを作成します。
FROM amazonlinux:2017.09 RUN curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.32.0/install.sh | bash \ && . ~/.nvm/nvm.sh \ && nvm install 8.10.0 ENV PATH /root/.nvm/versions/node/v8.10.0/bin:$PATH WORKDIR /home/ec2-user RUN mkdir twitterApp COPY ./SocialAnalyticsReader/ /home/ec2-user/twitterApp RUN chmod ugo+x /home/ec2-user/* USER root WORKDIR /home/ec2-user/twitterApp ENTRYPOINT ["node","twitter_stream_producer_app.js"] - これらの手順を完了すると、ディレクトリ構造は次のようになります。

ステップ 2: Docker イメージを構築する
前の手順で Docker 環境で Dockerfile を作成 (/home/ec2-user ディレクトリからそれを実行) したディレクトリからこのコマンドを実行して、Docker イメージを作成します。docker build –t tweetreader .Step 5/8 : COPY ./SocialAnalyticsReader/ /home/ec2-user/twitterApp/
---> Using cache
---> 04d0088db623
Step 6/8 : RUN chmod ugo+x /home/ec2-user/*
---> Running in 5e4d9cc10239
Removing intermediate container 5e4d9cc10239
---> 5d7d7328cb93
Step 7/8 : USER root
---> Running in 893f1653c200
Removing intermediate container 893f1653c200
---> dfc016c8e4a7
Step 8/8 : ENTRYPOINT ["node","twitterApp/twitter_stream_producer_app.js"]
---> Running in a839a2139689
Removing intermediate container a839a2139689
---> ba5ede432da0
Successfully built ba5ede432da0
Successfully tagged tweetreader:latest
ステップ 3: Docker イメージを Amazon Elastic Container Registry (ECR) にプッシュする
ここでは、開発したばかりの Docker イメージを、完全マネージド型の Docker コンテナレジストリである Amazon Elastic Container Registry (ECR) にアップロードし、開発者が Docker コンテナイメージを簡単に保存、管理、および展開できるようにします。Amazon ECR は Amazon Elastic Container Service (ECS) と統合されており、本番ワークフローへと続く開発を簡素化します。Dev Environment で以下の手順を実行します。
- 次の aws configure コマンドを実行し、デフォルトの Region を「us-east-1」に設定します。
aws configure set default.region us-east-1 - このコマンドを使用して Amazon ECR リポジトリを作成します (出力の repositoryUri をメモします)。
aws ecr create-repository --repository-name tweetreader-repo
- 次のコマンドを使用して、前のステップの repositoryUri 値で tweetreader イメージにタグを付けます。
docker tag tweetreader:latest aws_account_id.dkr.ecr.us-east-1.amazonaws.com/ tweetreader-repo - 次のコマンドを使用して、Docker のログイン情報を取得します。
aws ecr get-login --no-include-email - 前の手順から返された Docker ログインコマンドを実行します。コマンドが成功すると、「Login Succeeded」というメッセージが表示されます。
- 次のコマンドを使用して、ステップ 1 の repositoryUri を使用して Docker イメージを Amazon ECR にプッシュします。
docker push aws_account_id.dkr.ecr.us-east-1.amazonaws.com/tweetreader-repo
ステップ 4: AWS Systems Manager Parameter Store に設定情報を格納する
次に、設定データ管理と秘密管理のための階層ストレージを提供する AWS Systems Manager Parameter Store にアプリケーション設定情報を格納します。パスワード、データベース文字列、ライセンスコードなどのデータをパラメータ値として保存することができます。コンテナの外部に設定パラメータを格納することで、このデータをコードから分離し、細かいレベルでアクセスを制御および監査できるようにすることで、セキュリティ体制を改善します。- AWS マネジメントコンソールに移動し、AWS Systems Manager コンソールに移動します。
- 左側のナビゲーションペインで、一番下までスクロールして [Parameter Store] を選択し、次に右上の [パラメータの作成] を選択します。
名前の場合: /twitter-reader/aws-config タイプの場合: String を選択 値の場合:
{ "twitter": { "consumer_key": "VAL1", "consumer_secret": "VAL2", "access_token": "VAL3", "access_token_secret": "VAL4" }, "topics": ["AWS", "VPC", "EC2", "RDS", "S3", "ECSSSS"], "languages": ["en", "es", "de", "fr", "ar", "pt"], "kinesis_delivery": "VAL5" }- プレースホルダー VAL1〜VAL4 を Twitter API の資格情報に対応する値で更新します。
- 前提条件セクションのステップ b IngestionFirehoseStream の物理 ID で取得した値でプレースホルダー VAL5 を更新します。
- 値は、
SocialMediaAnalyticsBlogPo-IngestionFirehoseStream-<value>のような値になります。 - [Create Parameter] を選択します。

ステップ 5: Fargate タスク定義とクラスターを作成する
次に、AWS Fargate を起動タイプとして Amazon ECS のタスクを設定します。Fargate の起動タイプを使用すると、バックエンドインフラストラクチャのプロビジョニングと管理を行うことなくコンテナ化されたアプリケーションを実行できます。- DevEnvironment に次の内容のテキストファイル「trustpolicyforecs.json」を作成します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ecs-tasks.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } - DevEnvironment で次のコマンドを使用して、「AccessRoleForTweetReaderfromFG」というロールを作成します。
aws iam create-role --role-name AccessRoleForTweetReaderfromFG --assume-role-policy-document file://trustpolicyforecs.json - DockerEnvironment で次のコマンドを使用して、Kinesis Data Firehose と Systems Manager IAM ポリシーをステップ 2 で作成したロールにアタッチします。
AccessRoleForTweetReaderfromFG は、ECS 上で実行されているタスクによって想定される IAM ロールです。ここで行う作業は Node アプリケーションを実行し、Kinesis Data Firehose にレコードを書き込み、AWS Systems Manager Parameter Store から設定情報を読み込むための IAM ポリシーだけが必要です。aws iam attach-role-policy --policy-arn arn:aws:iam::aws:policy/AmazonKinesisFirehoseFullAccess --role-name AccessRoleForTweetReaderfromFG aws iam attach-role-policy --policy-arn arn:aws:iam::aws:policy/AmazonSSMReadOnlyAccess --role-name AccessRoleForTweetReaderfromFG - Amazon ECS コンソールで、[Repositories] を選択し、前のステップで作成した [tweetreader-repo] リポジトリを選択します。リポジトリ URI をコピーします。

- [Task Definitions] を選択し、次に [Create New Task Definition] を選択します。
- 起動タイプの互換性を FARGATE として選択し、[Next Step] をクリックします。
- タスク定義の作成画面で、次の操作を行います。
- [Task Definition Name] に、「tweetreader-task」と入力します。
- [Task Role] で、[AccessRoleForTweetReaderfromFG] を選択します
- [Task Memory] で、[2GB] を選択します
- [Task CPU] で、[1 vCPU] を選択します

- [Container Definitions] の下にある [Add Container] を選択します。[Add Container] ページで、次の操作を行います。
- コンテナ名に「tweetreader-cont」と入力します。
- ステップ 1 でコピーした [Image URL] を入力します。
- [Memory Limits] に「128」と入力し、[Add] を選択します。
- タスクを作成するには、タスク定義画面で [Create] ボタンを選択します。タスク、実行ロール、Amazon CloudWatch Logs グループが正常に作成されます。
- Amazon ECS コンソールで、[Clunsters] を選択し、クラスターを作成します。テンプレートを「Network only, Powered by AWS Fargate」として選択し、次のステップを選択します。
- クラスター名を「tweetreader-cluster」と入力し、[Create] を選択します。

ステップ 6: Fargate タスクを開始し、アプリケーションを確認する
- Amazon ECS コンソールで、Task Definitions に行き、[tweetreader-task] を選択し、[Actions] を選択し、そして [Run Task] を選択します。
- [Run Task] ページで、Launch Type で Cluster で [Fargate] を選択し、[tweetreader-cluster] を選択して [Cluster VPC] と [Subnets] の値を選択し、次に [Run Task] を選択します。
- アプリケーションをテストするには、Fargate コンソールで実行中のタスクを選択します。[ログ] タブに移動し、そこに何もないことを確認します。これは、ノードアプリケーションが実行されており、エラーが発生していないことを意味します。Fargate タスクにエラーログがないことを確認したら、Amazon S3 コンソールに移動し、元のブログ記事の CloudFormation テンプレートの一部として作成されたバケットに移動します。raw と呼ばれるフォルダが表示されます。このフォルダの内容を確認してください。Twitter フィードリーダーアプリからサーバーレス処理フロー (Amazon Kinesis Data Firehose、Amazon Lex、Amazon Translate、Amazon Athena) に送信されたデータがあるはずです。
結論
おめでとうございます! EC2 インスタンスで以前実行されていたアプリケーションが正常に「コンテナ化」されました。さらに、Amazon ECS と AWS Fargate でコンテナを実行しているため、EC2 インスタンスのプロビジョニングや管理は不要です。また、タスクに必要なメモリー、CPU、および同時実行の量を調整することによって、AWS Fargate のタスク定義設定を調整することもできます。ECS と Fargate を使った作業の詳細については、「AWS Fargate ドキュメント」をご覧ください。
著者について
Raja Mani は、AWS パートナーをサポートするソリューションアーキテクトです。彼は サーバーレス開発、DevOps、コンテナ、ビッグデータ、機械学習に興味を持っています。彼は AWS パートナーが顧客向けにエンタープライズレベルの Amazon Web Services ソリューションを設計するのを手伝っています。Luis Pineda はシカゴに本拠を置く Amazon Web Services のパートナーソリューションアーキテクトです。AWS を使用してビジネス上の問題を解決するために、パートナーや顧客と協力しています。仕事以外では、アウトドア、ランニング、サイクリングやサッカーを楽しんでいます。
コメント
コメントを投稿